




 超级会员免费看
超级会员免费看
在图数据库中,逻辑上只有两类基础的数据类型:顶点(Nodes或Vertices)和边(Edges)。
一个顶点具有自己的ID和属性(标签、类别及其他属性)。
边也类似,但它通常是由两个顶点的顺序决定的(所谓有向图指的是每条边由一个初始顶点对应一个终止顶点,再加上其他属性所构成,例如边的方向、标签、权重等)。除了这些基础的数据结构,图数据库并不需要任何预先定义的模式或表结构。
这种极度简化的理念恰恰和人类如何思考以及存储信息有着很大的相似性——人类通常并不在脑海中设定表结构,而是随机应变。
现在,让我们看一些真实世界场景中的图数据库实现。下图是一个典型图数据集中顶点的属性定义,它包含最初的几个字段的定义,如desc、level、name、type等,也存在一些动态生成、扩增的字段,如#cc、#pr、#khop_1等。对比关系型数据库而言,整个表的结构是动态可调整的。
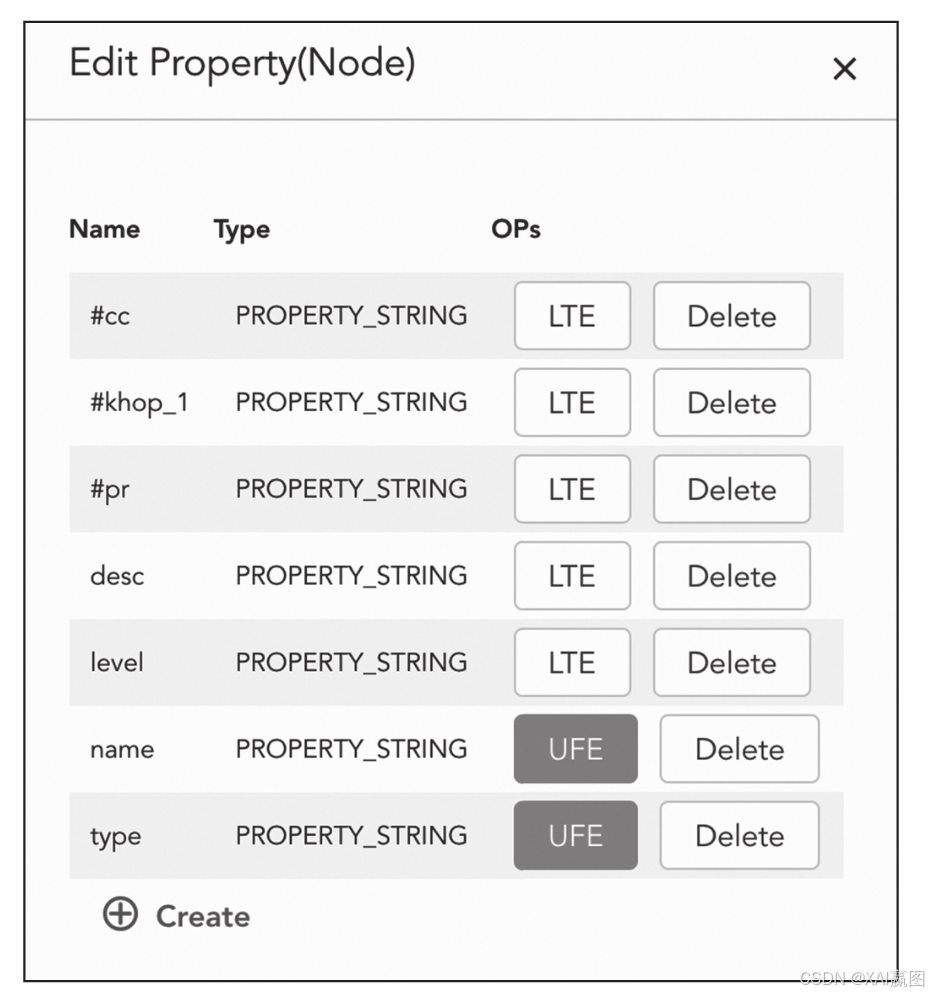
注意上图2-36中的Name和Type字段的属性为string类型,它可以最大化兼容广谱的数据类型,进而提供最大化的灵活性。顶点之间如何产生关联也无须被预先定义,这样所形成的关联网络也是灵活的。
细心的读者一定会问,这种灵活性怎么实现和保证性能的优化呢?通常的做法是通过存储与计算分层来实现。例如为了实

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









