 Elasticsearch判断列表评估搜索相关性
Elasticsearch判断列表评估搜索相关性







作者:来自 Elastic Jhon Guzmán
探索如何构建 判断列表(judgment lists) 来客观评估搜索查询相关性,并改进例如 recall 等性能指标,以实现 Elasticsearch 中可扩展的搜索测试。
Elasticsearch 充满了新功能,可以帮助你为你的用例构建最佳搜索解决方案。了解如何在我们关于构建现代 Search AI 体验的实操网络研讨会上将它们付诸实践。你也可以开始免费 cloud 试用,或立即在本地机器上尝试 Elastic。
从事搜索引擎开发的开发者经常遇到同样的问题:业务团队对某个特定搜索不满意,因为他们希望在搜索结果顶部出现的文档却出现在结果列表的第三或第四位。
然而,当你修复了这个问题时,你会意外破坏其他查询,因为你无法手动测试所有情况。但你或你的 QA 团队如何测试一个查询的更改是否对其他查询产生连锁反应?或者更重要的是,你如何确保你的更改实际上改进了某个查询?
迈向系统化评估
这正是 判断列表 派上用场的地方。与其在每次更改时依赖手动且主观的测试,你可以定义一组与你的业务场景相关的固定查询,并为这些查询配上对应的相关结果。
这组数据就成为你的基线。每次你实施更改时,都用它来评估你的搜索是否真的有所改进。
这种方法的价值在于它:
- 消除不确定性:你不再需要猜测你的更改是否影响其他查询;数据会告诉你。
- 停止手动测试:一旦记录了 判断列表 ,测试就是自动的。
- 支持更改:你可以展示清晰的指标来支持更改带来的好处。
如何开始构建你的 判断列表
最简单的方式之一是拿一个具有代表性的查询并手动选择相关文档。构建列表有两种方式:
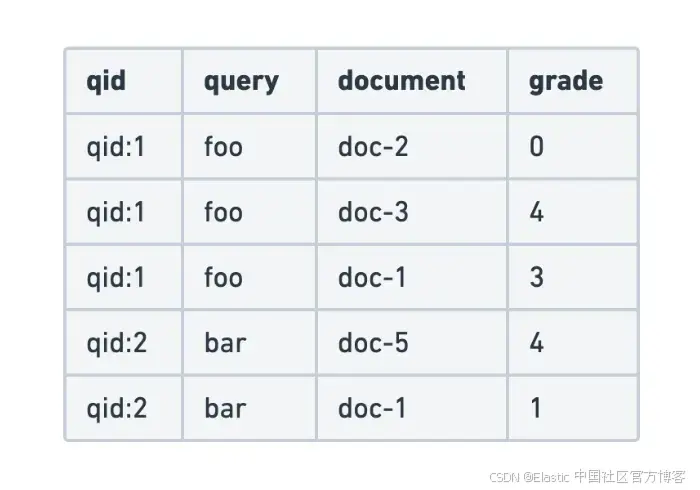
- 二元判断:每个与查询关联的文档得到一个简单标签:相关(通常得分为 “1”)或不相关(“0”)。
- 分级判断:每个文档按不同等级评分。例如使用 0 到 4 的量表,类似 Likert 量表,其中 0 = “完全不相关”,4 = “完全相关”,中间有“相关”“有点相关”等变化。
当搜索意图有明确界限时,二元判断非常有效:这个文档是否应该在结果中?
当存在灰色地带时,分级判断更有用:某些结果比其他结果更好,因此你可以得到 “非常好”, “好”,“没用”之类的结果,并使用重视结果排序和用户反馈的指标。然而,分级量表也带来缺点:不同评审者可能会以不同方式使用评分等级,使判断的一致性下降。而且由于分级指标对高分权重更大,即便是一个小变化(例如把某项从 4 评成 3)也可能对指标造成比评审者预期更大的影响。这种额外的主观性会让分级判断更嘈杂,也更难长期管理。
我需要自己对文档进行分类吗?
不一定,因为有多种方式可以创建你的 判断列表 ,每种方式都有其优缺点:
- 显式判断(Explicit Judgments):这里由领域专家逐一查看每个查询/文档,并手动决定它是否(或如何)相关。虽然质量高且可控,但可扩展性较差。
- 隐式判断(Implicit Judgements):这种方法根据真实用户行为(如点击、跳出率、购买等)推断相关文档。这种方式可以自动收集数据,但可能有偏差。例如用户往往更频繁点击排在前面的结果,即使它们并不相关。
- AI 生成判断(AI-generated Judgments):这种方式使用模型(例如 LLM)自动评估查询和文档,通常称为 LLM jury。它速度快、易扩展,但数据质量取决于模型质量以及模型训练数据与你的业务兴趣的契合度。与人工评分一样,LLM juries 也可能带来自身的偏差或不一致性,因此需要将其输出与少量可信的判断进行验证。由于 LLM 模型本质上是概率式的,即便把 temperature 设置为 0,也可能对同一结果给出不同评分。
以下是为你的 判断列表 选择最佳构建方式的一些建议:
- 决定哪些特性只有用户才能正确判断(例如价格、品牌、语言、风格、产品细节)对你来说是否至关重要。如果这些很关键,你至少需要为部分 判断列表 做显式判断。
- 当你的搜索引擎已有足够流量时,可使用隐式判断,通过点击、转化率和停留时间等指标检测用户趋势。但你仍需谨慎解读这些数据,并与显式判断对照,以避免偏差(例如:用户倾向点击排名更高的结果,即便排名更低的更相关)。
为了解决这个问题,可以使用位置去偏技术来调整或重新加权点击数据,以更好地反映真实用户兴趣。一些方法包括:
- 结果打乱:对部分用户改变搜索结果顺序,以估计位置对点击的影响。
- 点击模型:包括 Dynamic Bayesian Network DBN、User Browsing Model UBM。这些统计模型通过滚动、停留时间、点击顺序、返回结果页等模式来估计点击是否反映真实兴趣,而不仅仅是位置影响。
示例:电影评分 app
前提条件
要运行这个示例,你需要一个正在运行的 Elasticsearch 8.x 集群,可在本地或 Elastic Cloud(托管或 serverless)上,并且能够访问 REST API 或 Kibana。
想象一个应用,用户可以在其中上传他们对电影的看法,也可以搜索想看的电影。由于文本是用户自己撰写的,因此可能会有拼写错误以及大量表达方式的变化。因此搜索引擎必须能够理解这种多样性,并为用户提供有用的结果。
为了能够在不影响整体搜索行为的情况下迭代查询,你公司中的业务团队基于最常见的搜索构建了以下二元 判断列表:
| Query | DocID | Text |
|---|---|---|
| DiCaprio performance | doc1 | DiCaprio's performance in The Revenant was breathtaking. |
| DiCaprio performance | doc2 | Inception shows Leonardo DiCaprio in one of his most iconic roles. |
| DiCaprio performance | doc3 | Brad Pitt delivers a solid performance in this crime thriller. |
| DiCaprio performance | doc4 | An action-packed adventure with stunning visual effects. |
| sad movies that make you cry | doc5 | A heartbreaking story of love and loss that made me cry for hours. |
| sad movies that make you cry | doc6 | One of the saddest movies ever made — bring tissues! |
| sad movies that make you cry | doc7 | A lighthearted comedy that will make you laugh |
| sad movies that make you cry | doc8 | A science-fiction epic full of action and excitement. |
创建索引:
PUT movies
{
"mappings": {
"properties": {
"text": {
"type": "text"
}
}
}
}BULK 请求:
POST /movies/_bulk
{ "index": { "_id": "doc1" } }
{ "text": "DiCaprio performance in The Revenant was breathtaking." }
{ "index": { "_id": "doc2" } }
{ "text": "Inception shows Leonardo DiCaprio in one of his most iconic roles." }
{ "index": { "_id": "doc3" } }
{ "text": "Brad Pitt delivers a solid performance in this crime thriller." }
{ "index": { "_id": "doc4" } }
{ "text": "An action-packed adventure with stunning visual effects." }
{ "index": { "_id": "doc5" } }
{ "text": "A heartbreaking story of love and loss that made me cry for hours." }
{ "index": { "_id": "doc6" } }
{ "text": "One of the saddest movies ever made -- bring tissues!" }
{ "index": { "_id": "doc7" } }
{ "text": "A lighthearted comedy that will make you laugh." }
{ "index": { "_id": "doc8" } }
{ "text": "A science-fiction epic full of action and excitement." }下面是该 app 使用的 Elasticsearch 查询:
GET movies/_search
{
"query": {
"match": {
"text": {
"query": "DiCaprio performance",
"minimum_should_match": "100%"
}
}
}
}从判断到指标
单独来看,判断列表提供的信息有限;它们只是我们对查询结果的预期。它们真正的价值在于可以用来计算客观指标,从而衡量我们的搜索性能。
如今,大多数流行的指标包括:
- Precision:衡量在所有搜索结果中真正相关结果的比例。
- Recall:衡量搜索引擎在 x 个结果中找到的相关结果比例。
- Discounted Cumulative Gain (DCG):衡量结果排名的质量,考虑最相关的结果应该排在最前面。
- Mean Reciprocal Rank (MRR):衡量第一个相关结果的位置。它在列表中越靠前,得分越高。
以同一个电影评分 app 为例,我们将计算 recall 指标,查看我们的查询是否遗漏了信息。
在 Elasticsearch 中,我们可以使用 判断列表 通过 Ranking Evaluation API 来计算指标。该 API 接收判断列表、查询和你想要评估的指标作为输入,并返回一个值,即查询结果与 判断列表 的比较。
让我们对已有的两个查询运行 判断列表 :
POST /movies/_rank_eval
{
"requests": [
{
"id": "dicaprio-performance",
"request": {
"query": {
"match": {
"text": {
"query": "DiCaprio performance",
"minimum_should_match": "100%"
}
}
}
},
"ratings": [
{
"_index": "movies",
"_id": "doc1",
"rating": 1
},
{
"_index": "movies",
"_id": "doc2",
"rating": 1
},
{
"_index": "movies",
"_id": "doc3",
"rating": 0
},
{
"_index": "movies",
"_id": "doc4",
"rating": 0
}
]
},
{
"id": "sad-movies",
"request": {
"query": {
"match": {
"text": {
"query": "sad movies that make you cry",
"minimum_should_match": "100%"
}
}
}
},
"ratings": [
{
"_index": "movies",
"_id": "doc5",
"rating": 1
},
{
"_index": "movies",
"_id": "doc6",
"rating": 1
},
{
"_index": "movies",
"_id": "doc7",
"rating": 0
},
{
"_index": "movies",
"_id": "doc8",
"rating": 0
}
]
}
],
"metric": {
"recall": {
"k": 10,
"relevant_rating_threshold": 1
}
}
}我们将对 _rank_eval 使用两个请求:一个用于 DiCaprio 查询,另一个用于 sad movies 查询。每个请求都包括一个查询及其 判断列表(评分)。我们不需要对所有文档进行评分,因为评分中未包含的文档被视为无判断。计算时,recall 仅考虑 “相关集合”,即评分中被认为相关的文档。
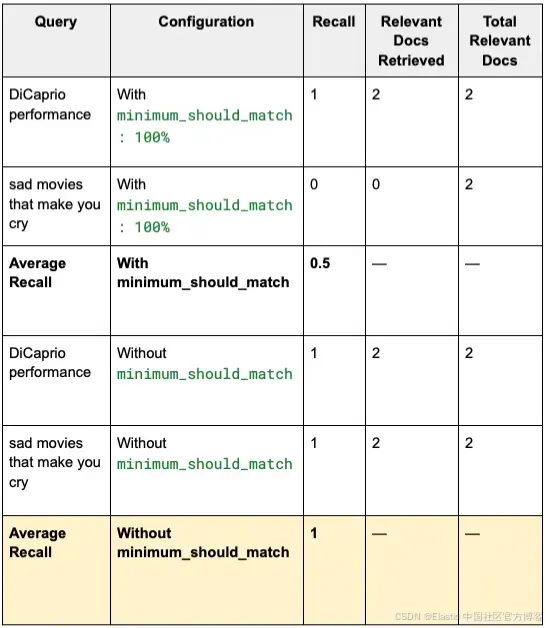
在这种情况下,DiCaprio 查询的 recall 为 1,而 sad movies 查询为 0。这意味着对于第一个查询,我们能够获取所有相关结果,而对于第二个查询,我们没有获取任何相关结果。因此平均 recall 为 0.5。
{
"metric_score": 0.5,
"details": {
"dicaprio-performance": {
"metric_score": 1,
"unrated_docs": [],
"hits": [
{
"hit": {
"_index": "movies",
"_id": "doc1",
"_score": 2.4826927
},
"rating": 1
},
{
"hit": {
"_index": "movies",
"_id": "doc2",
"_score": 2.0780432
},
"rating": 1
}
],
"metric_details": {
"recall": {
"relevant_docs_retrieved": 2,
"relevant_docs": 2
}
}
},
"sad-movies": {
"metric_score": 0,
"unrated_docs": [],
"hits": [],
"metric_details": {
"recall": {
"relevant_docs_retrieved": 0,
"relevant_docs": 2
}
}
}
},
"failures": {}
}也许我们对 minimum_should_match 参数要求太严格了,因为要求查询中的 100% 词都出现在文档中,可能会遗漏相关结果。我们可以去掉 minimum_should_match 参数,这样只要查询中有一个词出现在文档中,该文档就被视为相关。
POST /movies/_rank_eval
{
"requests": [
{
"id": "dicaprio-performance",
"request": {
"query": {
"match": {
"text": {
"query": "DiCaprio performance"
}
}
}
},
"ratings": [
{
"_index": "movies",
"_id": "doc1",
"rating": 1
},
{
"_index": "movies",
"_id": "doc2",
"rating": 1
},
{
"_index": "movies",
"_id": "doc3",
"rating": 0
},
{
"_index": "movies",
"_id": "doc4",
"rating": 0
}
]
},
{
"id": "sad-movies",
"request": {
"query": {
"match": {
"text": {
"query": "sad movies that make you cry"
}
}
}
},
"ratings": [
{
"_index": "movies",
"_id": "doc5",
"rating": 1
},
{
"_index": "movies",
"_id": "doc6",
"rating": 1
},
{
"_index": "movies",
"_id": "doc7",
"rating": 0
},
{
"_index": "movies",
"_id": "doc8",
"rating": 0
}
]
}
],
"metric": {
"recall": {
"k": 10,
"relevant_rating_threshold": 1
}
}
}如你所见,通过在两个查询中的一个去掉 minimum_should_match 参数,现在两个查询的平均 recall 都为 1。
{
"metric_score": 1,
"details": {
"dicaprio-performance": {
"metric_score": 1,
"unrated_docs": [],
"hits": [
{
"hit": {
"_index": "movies",
"_id": "doc1",
"_score": 2.0661702
},
"rating": 1
},
{
"hit": {
"_index": "movies",
"_id": "doc3",
"_score": 0.732218
},
"rating": 0
},
{
"hit": {
"_index": "movies",
"_id": "doc2",
"_score": 0.6271719
},
"rating": 1
}
],
"metric_details": {
"recall": {
"relevant_docs_retrieved": 2,
"relevant_docs": 2
}
}
},
"sad-movies": {
"metric_score": 1,
"unrated_docs": [],
"hits": [
{
"hit": {
"_index": "movies",
"_id": "doc7",
"_score": 2.1307156
},
"rating": 0
},
{
"hit": {
"_index": "movies",
"_id": "doc5",
"_score": 1.3160692
},
"rating": 1
},
{
"hit": {
"_index": "movies",
"_id": "doc6",
"_score": 1.190063
},
"rating": 1
}
],
"metric_details": {
"recall": {
"relevant_docs_retrieved": 2,
"relevant_docs": 2
}
}
}
},
"failures": {}
}总之,去掉 minimum_should_match: 100% 条款,使我们能够对两个查询获得完美的 recall。
我们成功了!对吧?
别急!
通过提高 recall,我们打开了获取更多结果的大门。然而,每一次调整都意味着权衡。这就是为什么要定义完整的测试用例,并使用不同指标来评估更改。
使用 判断列表 和指标可以防止在更改时盲目操作,因为你现在有数据支持。验证不再是手动且重复的,你可以在不止一个用例中测试更改。此外,A/B 测试允许你在实际环境中测试哪种配置对用户和业务最有效,从而实现从技术指标到真实世界指标的完整闭环。
使用 判断列表 的最终建议
使用 判断列表 不仅是为了衡量,也是在创建一个让你可以自信迭代的框架。为此,你可以遵循以下建议:
-
从小开始,但要开始。你不需要有 10,000 个查询,每个查询有 50 个 判断列表。你只需识别 5–10 个对你的业务最关键的查询,并定义你希望在结果顶部看到哪些文档。这就已经提供了一个基础。通常你会从热门查询和无结果查询开始。你也可以先用易于配置的指标如 Precision 进行测试,然后再逐步增加复杂性。
-
与用户验证。在生产环境中结合 A/B 测试补充数据。这样,你就能知道在指标上表现良好的更改是否真正产生了影响。
-
保持列表活跃。你的业务会发展,你的关键查询也会变化。定期更新 判断列表 以反映新需求。
-
将其纳入流程。将 判断列表 集成到开发流水线中。确保每次配置更改、同义词或文本分析都能自动验证基础列表。
-
将技术知识与策略连接。不要只停留在衡量技术指标如 precision 或 recall。使用你的评估结果来指导业务成果。
原文:https://www.elastic.co/search-labs/blog/judgment-lists-search-query-relevance-elasticsearch


















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









