






作者:来自 Elastic Alexander Marquardt
了解在 Elasticsearch 中高副本数量的影响,以及如何通过合理设置副本数量来确保集群稳定性。
测试 Elastic 的前沿开箱能力。深入查看我们的示例 notebooks,开始免费 cloud 试用,或立即在你的本地机器上尝试 Elastic。
执行摘要
副本对 Elasticsearch 至关重要:它们提供高可用性并帮助扩展搜索工作负载。但像任何分布式系统一样,过多的冗余会适得其反。过高的副本数量会放大写入负载、增加分片开销、耗尽文件系统缓存、提升堆内存压力,并可能使集群变得不稳定。
本文解释了为什么过多的副本数量会导致严重的性能下降、如何诊断这些症状,以及在一个真实的大规模客户部署中,如何通过合理设置副本数量恢复稳定性。
Elasticsearch 中副本的角色
副本在 Elasticsearch 中有两个主要用途:
- 高可用性:如果某个节点发生故障,副本能确保数据依然可用。
- 搜索可扩展性:副本允许 Elasticsearch 将搜索负载分布到多个节点。
然而,每个副本都是其主分片的完整物理副本,并且每次写入都必须应用到每个副本。副本提供弹性,但同时也会消耗 CPU、堆内存、文件系统缓存、磁盘 I/O、集群状态带宽和恢复带宽。副本很强大,但并不是免费的。
什么时候高副本数量是合理的
在一小部分特定场景中,高副本数量确实可以提升性能:
- 集群包含数量很少但极其热点的数据,并且这些工作集能够在每个节点的 RAM 中完全容纳。
- 集群是有意超额配置的。
- 数据很少被写入或更新。
在这种情况下,副本可以有效利用所有节点,最大化 CPU 使用率和缓存效率。

大型多索引集群中的现实情况
大多数生产环境中包含许多索引、多样化的工作负载、不同的分片大小,以及混合的读写模式。在这些环境中,高副本数量会引入叠加的问题,可能严重降低性能。
缓存抖动与内存压力
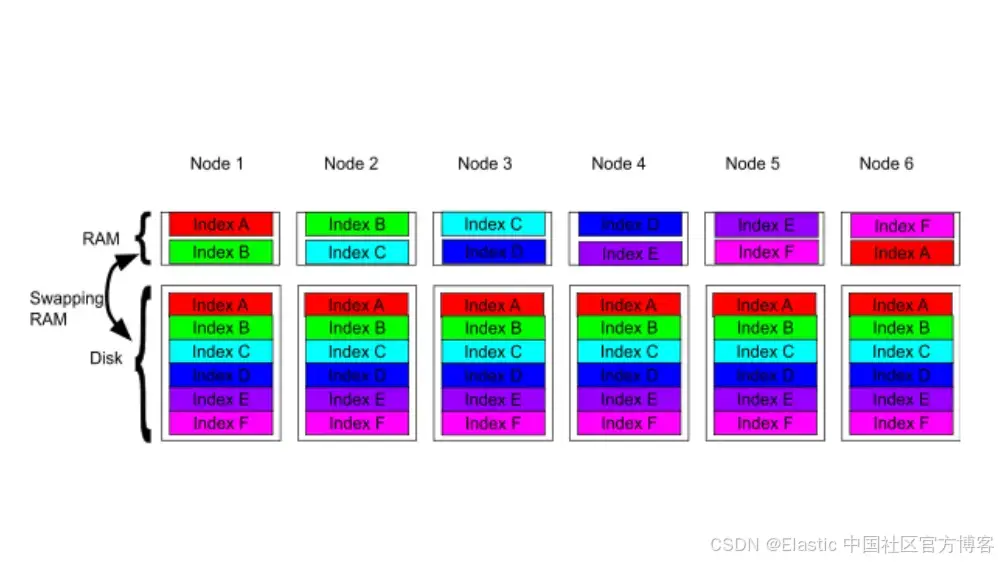
每个分片副本都会争夺有限的文件系统缓存。当副本数量过多时:
- 工作集会超出 RAM 容量
- 节点会在常规查询中被迫从磁盘读取
- 有用的缓存页面会不断被驱逐,造成 “缓存抖动”,缓存命中率崩溃
- 延迟变得不可预测
当多个索引争夺同一有限的内存时,处理一次查询的成本会急剧上升,因为该查询所需的分片数据不在 RAM 中。

注意:这个图是概念性的。实际中,节点会在文件系统缓存中存放许多分片的交错片段,但其底层原理与图中展示的一致。
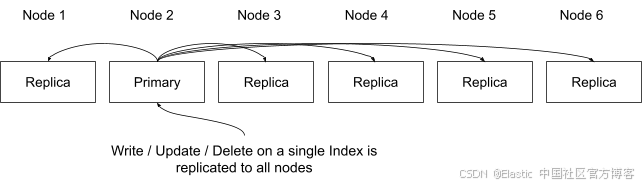
写入放大
如果一个集群有 5 个副本,一次写入就会变成 6 次独立的磁盘写入,每一次都有自己的合并周期、段管理和 I/O 成本。这会直接增加:
- 磁盘使用率
- 索引延迟
- 合并压力
- 线程池饱和
- 反压和重试负载
在高副本数量下,索引吞吐量可能变得不可持续。图示展示了当某个索引有 5 个副本时,对该索引的一次更新会在所有托管该分片副本的节点上执行写入操作,在这个示例中是集群中的全部六个节点。
更多有关写入操作,可以参考文章:
Shard 开销增加
更多的 replica 意味着更多的:
- Shards
- Segment files
- File descriptors
- Cluster state updates
- 为每个 shard 数据结构保留的内存
这会增加 JVM heap 使用并提高 GC 频率。
诊断过度副本:主要症状
遭受过度副本的集群通常会出现以下运行症状:
- 频繁的页面错误和交换:工作集无法完全放入内存,导致缓存频繁未命中。
- 过度垃圾回收(GC):由于分片过多,堆内存使用率高且 GC 停顿时间长。
- 磁盘 I/O 升高:写放大和缓存频繁替换导致磁盘操作增加。
- 未分配的分片和节点不稳定:资源耗尽可能导致节点离开,分片重新分配。
- 搜索延迟峰值:查询频繁未命中缓存而访问磁盘,导致响应时间不可预测。
如果你观察到这些症状,应检查副本数量和分片策略。
解决方案:合理设置副本数量
最佳实践
- 根据容错需求设置副本,而不是凭猜测。对于大多数集群,1 个副本就足够(如果跨越 3 个可用区,则为 2 个副本)。
- 监控缓存命中率和堆内存使用情况。确保热点工作集能够放入内存;否则,应减少副本数量或重新设计分片策略。
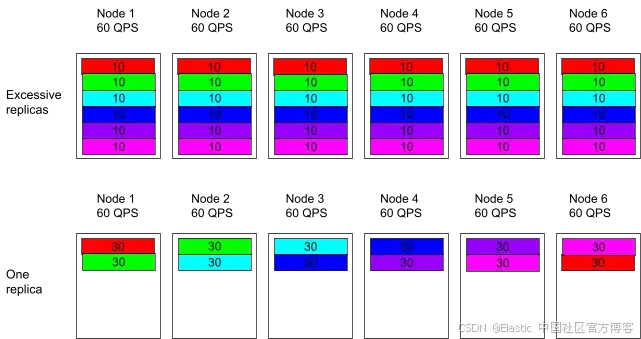
- 以之前的六节点示例为例,将副本从 5 个减少到 1 个,可以显著降低缓存争用,提高缓存局部性,并减少写放大,如下图所示。

减少副本的影响
一位大型企业客户的集群长期严重不稳定,表现出以下症状:
- 高延迟
- 节点频繁离开集群
- 磁盘 I/O 过高
- GC 中断频繁
- 搜索吞吐量骤降
在升级处理后,快速定位到根本原因:该 20 节点集群在多个索引上配置了 12 个副本。将副本数量降低到合理基线(通常为 1)并重新平衡分片后:
- 搜索延迟几乎立即恢复正常
- 磁盘 I/O 显著下降
- GC 回到正常水平
- 节点稳定,无进一步掉线
合理设置副本数量是关键的干预措施。
常见误解:减少副本会导致节点过载吗?
一个常见担忧是,减少副本数量会将搜索流量集中到更少的节点上,造成热点或瓶颈。实际上,Elasticsearch 会将每个索引的查询分发到所有可用的分片副本(主分片和副本分片)。减少副本并不会改变集群处理的总查询量;它只是改变了每个节点的内存使用情况。
副本减少后,每个节点承载的分片更少,这大大增加了查询所需数据已经在内存中的可能性。每个节点的总体 QPS 保持相当,但每个查询的成本显著下降,因为更少的查找会触发(昂贵的)磁盘 I/O。
建议
- 审查集群:检查所有索引的副本数量,确保你实际从所配置的副本中受益。
- 避免“一刀切”设置:根据工作负载调整每个索引的主分片和副本数量。
- 培训团队:副本是工具,而非万能解决方案。理解其权衡。
- 动态修改副本数量:副本数量可以随时修改。在受控环境中测试更改,并在调整前后监控性能。
结论
副本对于集群的弹性和搜索可扩展性至关重要,但在许多情况下,高副本数量可能悄悄破坏 Elasticsearch 集群性能。
过多的副本会放大写入、增加分片开销、破坏系统内存和缓存行为,并使大型多索引工作负载不稳定。
如果集群出现无法解释的延迟、GC 压力或不稳定问题,应从审查副本设置开始。在 Elasticsearch 性能优化中,更多并不总是更好——通常,少一些会更快、更可靠。
进一步阅读
- Elasticsearch: Tune for Search Speed
- Elasticsearch: Sizing and Scaling
- Elasticsearch: Shard and Replica Allocation
原文:https://www.elastic.co/search-labs/blog/elasticsearch-replica-counts-right-sizing


















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









