









作者:来自 Elastic Gilad Gal

探索 Elasticsearch 的向量搜索如何以更快的速度、更低的成本提供更优结果。
试用向量搜索:使用这套自定进度的 Search AI 实操学习课程,亲自体验向量搜索。你可以开始免费云试用,或立即在本地机器上试用 Elastic。
在由 AI 驱动的搜索世界里,有三件事最重要:查询速度、排序准确性,以及实现这些所需的资源成本。在 Elastic,我们持续在这三个方面突破极限。我很高兴分享 Elasticsearch 9.1 中的两项密集向量搜索新进展:一项名为 ACORN 的新算法,用于更快的过滤向量搜索;以及新证据表明,我们默认的量化方法 BBQ 不仅能降低成本,还可以提升排序质量。
ACORN:更智能的过滤搜索路径
现实世界的搜索很少是简单的“帮我找类似这个的东西”。它常常是 “帮我找尺码合适的类似产品” 或 “帮我找和上个季度类似的文档”。即使是避开已删除文档,也是一种过滤,因此实际中,过滤搜索非常常见。
让过滤向量搜索既快速又不损失准确性,是一个深层的技术挑战。 HNSW 算法基于图搜索,图中的节点表示向量。图是在索引时构建的,而不是查询时构建的。当支持预过滤时,为了得到准确结果(就像 Elasticsearch 所做的那样),最直接的方法是在图中遍历,只收集通过过滤的节点。问题在于,这种方法仍然会评估未通过过滤的节点,以便继续搜索它们的邻居和整个图,导致搜索变慢。当过滤条件较严格,大多数文档不通过过滤时,这个问题尤其明显。之前我们已有部分解决方案,但我们认为可以做得更好。
我们选择使用 ACORN-1(ANN Constraint-Optimized Retrieval Network),这是一篇 2024 年学术论文中描述的新算法,用于执行过滤 k 近邻(kNN)搜索。 ACORN 通过将过滤过程直接集成到 HNSW 图遍历中实现这一目标。使用 ACORN-1 时,只评估通过过滤的节点,但为了避免遗漏相关部分,会同时评估二级邻居(即邻居的邻居),前提是它们也通过过滤。 Elasticsearch 使用的 Lucene 实现中还包含一些启发式方法,进一步优化结果(详见博客)。
在选择具体算法和实现时,我们还探索了其他理论上可能进一步优化延迟的替代方案,但决定不采用它们,因为这些方法要求用户在索引前声明用于过滤的字段。而我们重视在文档导入后仍可灵活定义过滤字段的能力,因为现实中的索引是不断演变的。潜在的轻微性能提升不足以抵消灵活性丧失,我们也可以通过其他手段获得性能,例如 BBQ(见下文)。
结果是性能的大幅提升。我们测得典型加速为 5 倍,在某些高选择性过滤下提升更大。这对复杂的现实查询是一项巨大增强。要使用 ACORN-1,只需在 Elasticsearch 中执行过滤向量查询即可。
BBQ:更优排序的意外超能力
降低向量的内存占用对于构建可扩展、具成本效益的 AI 系统至关重要。我们的 Better Binary Quantization( BBQ )方法通过将高维 float 向量压缩约 32 倍来实现这一目标。我们之前在 Search Labs 博客中已经讨论过, BBQ 在召回率、延迟和成本方面优于诸如 Product Quantization 的其他技术:
不过,直观的假设是,这种极大幅度、有损压缩必然会牺牲排序质量。然而我们近期的大规模基准测试显示,通过扩大图遍历范围并重新排序,我们完全可以弥补这一点,不仅在成本和性能上实现提升,还能提高相关性排序的质量。
BBQ 不仅仅是压缩技巧;它是一个复杂的两阶段搜索过程:
-
广泛扫描:首先,使用体积极小的压缩向量快速扫描数据集,识别出一组排名靠前的文档。该集合的大小超过用户请求的前 N 个结果(即超采样)。
-
精确重排:然后,从初始扫描中选出顶级候选项,使用它们原始的高精度 float32 向量进行重排,确定最终顺序。
这种超采样加重排的过程是一种强大的校正机制,常常能发现纯 float32 HNSW 搜索在其较有限图遍历中可能遗漏的高相关结果。
排序结果证明一切
为了衡量效果,我们使用了 NDCG@10(归一化折扣累计增益@10),这是一项评估前 10 条搜索结果质量的标准指标。 NDCG 分数越高,说明相关性更高的文档排名越靠前。你可以在我们的排序评估 API 文档中了解更多信息。
我们在 BEIR 数据集中的 10 个公开数据集上运行了多项基准测试,比较了传统 BM25 搜索、使用 e5-small 模型的向量搜索( float32 向量),以及同一模型结合 BBQ 的向量搜索。我们选择 e5-small,是因为根据之前的基准测试, BBQ 在高维向量上表现最佳,而我们希望在其挑战较大的场景下测试 BBQ —— 比如 e5-small 生成的低维向量。我们使用 NDCG@10 进行测量,这是一个考虑结果顺序的排序质量指标。下面是我们观察到的结果的代表性示例。
| Data set | BM25 | e5-small float32 | e5-small BBQ with defaults |
|---|---|---|---|
| Climate-FEVER | 0.143 | 0.1998 | 0.2059 |
| DBPedia | 0.306 | 0.3143 | 0.3414 |
| FiQA-2018 | 0.251 | 0.3002 | 0.3136 |
| Natural Questions | 0.292 | 0.4899 | 0.5251 |
| NFCorpus | 0.321 | 0.2928 | 0.3067 |
| Quora | 0.808 | 0.8593 | 0.8765 |
| SCIDOCS | 0.155 | 0.1351 | 0.1381 |
| SciFact | 0.683 | 0.6569 | 0.677 |
| Touché-2020 | 0.337 | 0.2096 | 0.2089 |
| TREC-COVID | 0.615 | 0.7122 | 0.7189 |
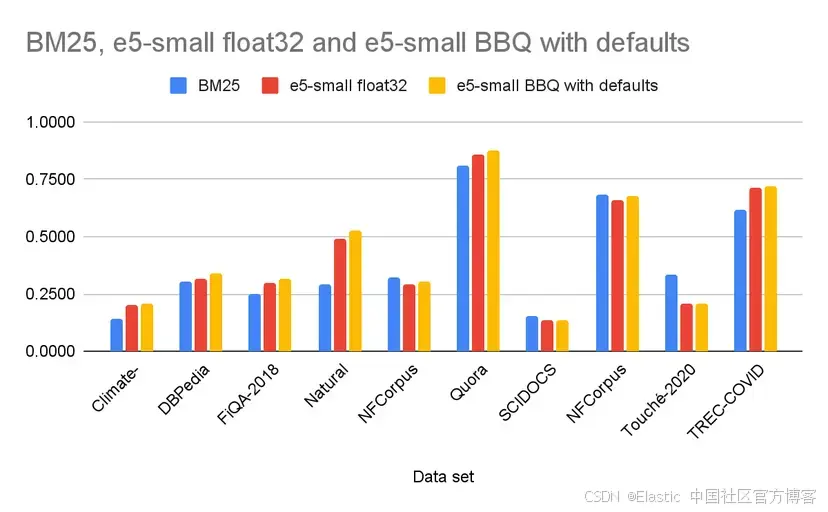
结果令人震撼。在 10 个数据集中, BBQ 在其中 9 个的排序质量优于纯 float32 搜索。即便在唯一的例外中,差异也可以忽略不计。此外,在这 10 个数据集中, BBQ 是整体表现最好的方法之一,在 6 个数据集中排名第一。顺带一提,最佳排序结果通常是通过将 BM25 与向量查询结合使用,并融合其他因素如距离、时间和热度来获得的,而 Elasticsearch 在这种类型的查询中表现出色。
有人可能会问: BBQ 是有损压缩,为什么它的排序会优于 float32?确实,在 BBQ 中我们进行超采样并用 float32 向量进行重排,但理论上使用 float32 时,我们应该可以直接用 float32 向量为所有文档排序。那么为什么 BBQ 排序反而更好?
答案在于:在 HNSW 中,我们每个分片只评估一部分向量,这由一个参数 num_candidates 决定。默认情况下,在未使用量化时, num_candidates = 1.5 * k,其中 k 是返回给用户的结果数量。你可以在这里阅读我们为确定该默认值所进行的基准测试。
而当我们使用 BBQ 进行量化时,向量比较速度更快,因此我们可以使用更大的 num_candidates,同时还降低了延迟。经过基准测试,我们将 BBQ 的默认 num_candidates 设置为 max(1.5 * k, oversample * k)。
对于上面的基准测试,我们使用默认设置,其中 k = 10,因此 num_candidates 的计算如下:
- Float32: 1.5*k = 1.5*10 = 15
- BBQ: max(1.5*k, oversample*k) = max(1.5*10, 3*10) = 30
由于 num_candidates 的不同,使用 BBQ 时我们扫描了更大范围的 HNSW 图,并在前 30 个候选中获得了更优的结果,这些候选随后由 float32 重排。这也解释了 BBQ 如何带来更好的排序质量。你可以根据自己的需求设置 num_candidates(例如见此),或者像大多数用户一样,信任我们的基准测试并使用默认值。
这也回答了我曾被咨询的一个问题:“是用 e5-large 搭配 BBQ 更好,还是用 e5-small 搭配 float32 更好?”答案现在非常明确。使用更强大的模型 e5-large 搭配 BBQ,能够兼得所有优势:
-
更优排序:来自更强大的 e5-large 模型,再通过 BBQ 进一步增强。
-
更低延迟:得益于极高效率的 BBQ 搜索流程。
-
更低成本:由于内存缩减 32 倍。
这是一种三赢的局面,证明你无需在质量和成本之间做取舍。
正因为 BBQ 的优势已经得到验证,我们在 Elasticsearch 9.1 中将 BBQ 设为默认的量化方法,适用于维度 ≥ 384 的密集向量。我们推荐大多数现代嵌入模型使用该方法,这些模型通常能很好地在向量空间中分布,使其非常适合 BBQ 的方式。
今天就开始吧
ACORN 和 BBQ 的这些进展让你能够在 Elastic 上构建更强大、可扩展且具成本效益的 AI 应用。你可以以高速执行复杂的过滤查询,同时提升排序相关性并大幅降低内存成本。
升级到 Elasticsearch 9.1,享受这些新功能。
- 在我们的文档中了解更多关于 kNN 搜索和向量量化的内容。
- 通过我们的排序评估 API 深入了解排序质量。
我们帮你处理复杂性,让你专注于打造出色的搜索体验。祝搜索愉快。
原文:Elasticsearch now with BBQ by default & ACORN for filtered vector search - Elasticsearch Labs


















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









