







 本文详细介绍了如何使用Python的matplotlib库进行基本的绘图操作,包括绘制散点图、子图以及设置图元属性。通过实例展示了如何创建多个子图,设置坐标轴范围、标签、刻度间隔和自定义文字,并提供了调整图像分辨率和保存图片的方法。此外,还提及了gridspec属性用于更高级的布局调整。
本文详细介绍了如何使用Python的matplotlib库进行基本的绘图操作,包括绘制散点图、子图以及设置图元属性。通过实例展示了如何创建多个子图,设置坐标轴范围、标签、刻度间隔和自定义文字,并提供了调整图像分辨率和保存图片的方法。此外,还提及了gridspec属性用于更高级的布局调整。
最近的工作中一直在用python,不过都是一些比较简单没有啥技术含量的东西,搬砖工作。不过有的时候会遇到用python画一些散点图,下面关于出图的内容,我想跟大家分享分享。
以下内容将按照 “绘图”–>“绘制子图”–>“绘图元素的设置”–>“出图” 的顺序,进行简单讲解。统一使用的是python的中的 matplotlib.pyplot 工具。
1、“绘图”
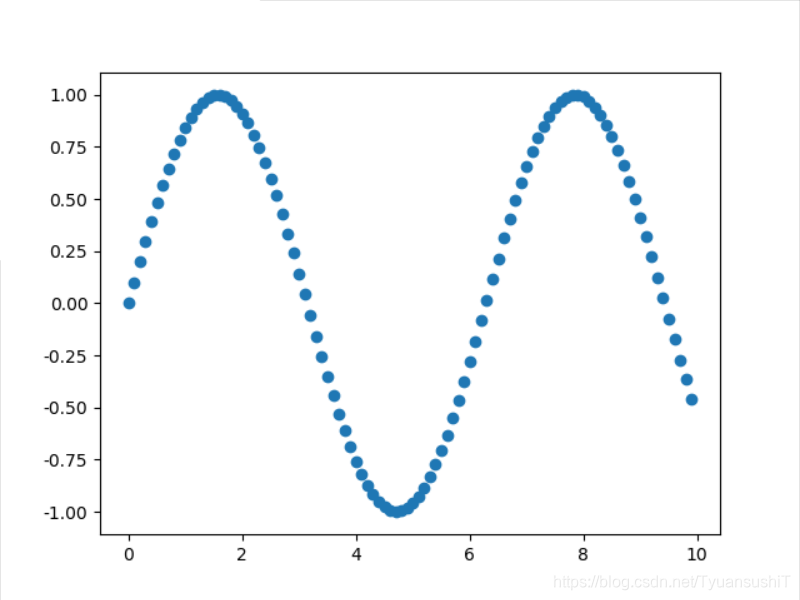
我原本在使用python的时候,发现绘图还是挺简单的,把两组数据准备好,使用pyplot工具中的scatter(),或者plot(),然后 show()一下就好了。例子如下:
import matplotlib.pyplot as plt
a=[]
b=[]
def initNumb():
for i in range(0,100):
a.append(i*0.1)
for j in range(0,100):
b.append(math.sin(j*0.1))
def plotShow1():
plt.scatter(a,b)
plt.show()
initNumb()
plotShow1()
2、“绘制子图”
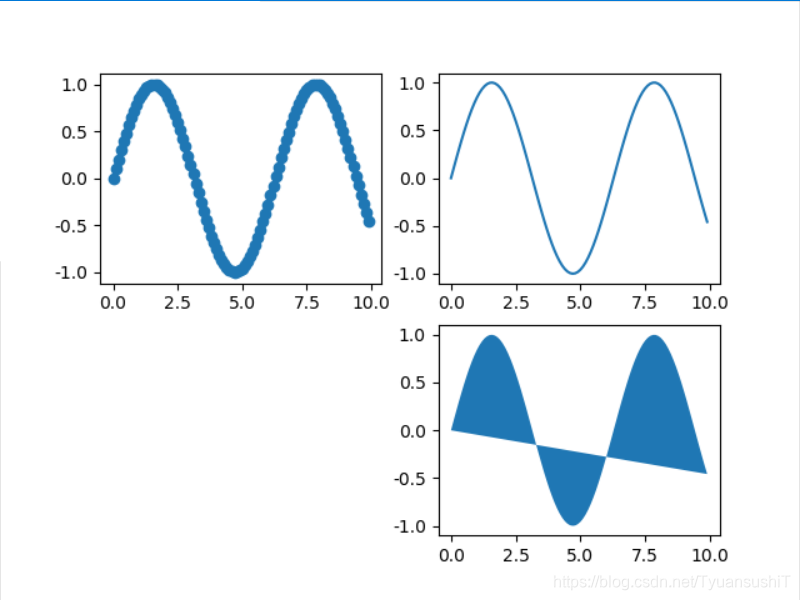
如果你想要两个或者多个图同时出现在一个图片上,变成一个文件。你就可以是用这部分的功能。当然,你也可以另辟蹊径,比如先把每个图片生成好,然后放到PS等工具中进行处理也是可以的。这里使用了add_subplot() 方法。例子如下:
import matplotlib.pyplot as plt
a=[]
b=[]
def initNumb():
for i in range(0,100):
a.append(i*0.1)
for j in range(0,100):
b.append(math.sin(j*0.1))
def plotShow2():
fig=plt.figure()
ax1 = fig.add_subplot(221)
ax1.scatter(a,b)
ax2 = fig.add_subplot(222)
ax2.plot(a,b)
ax3 = fig.add_subplot(224)
ax3.fill(a,b)
plt.show()
initNumb()
plotShow2()
3、“绘图标题元素的设置”
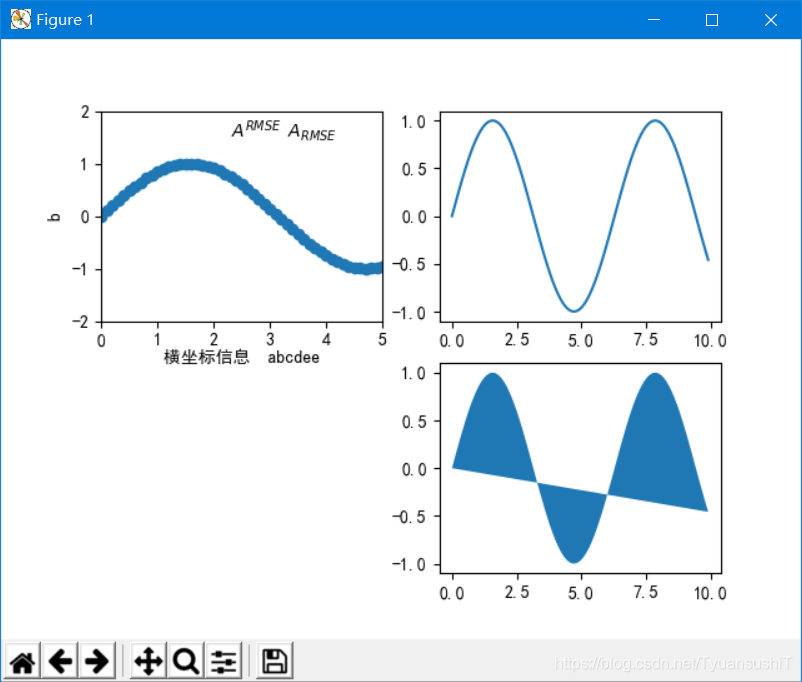
上面的两种方法虽然把图都输出了,但是存在一个问题,没有坐标轴的其他信息。横轴是啥,纵轴是啥,这个刻度间隔能不能调 ,字体字号能不能调。为了解决这个问题,就需要对这些图中的元素进行设置。例子如下:
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
a=[]
b=[]
def initNumb():
for i in range(0,100):
a.append(i*0.1)
for j in range(0,100):
b.append(math.sin(j*0.1))
def plotShow2():
reload(sys)
sys.setdefaultencoding('utf-8')
# fm.FontProperties(fname=r'C:\Windows\Fonts\SimHei.ttf') # 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei'] #设置中文字体,不然中文会显示为乱码
plt.rcParams['axes.unicode_minus'] = False
fig=plt.figure(figsize=(10,10)) # 设置显示图片的大小
ax1 = fig.add_subplot(221)
ax1.scatter(a,b)
ax1.set_xlim(0, 5) #设置上下界
ax1.set_ylim(-2, 2) #设置上下界
x_major_locator = MultipleLocator(1)
ax1.xaxis.set_major_locator(x_major_locator) #设置坐标轴间隔
ax1.set_ylabel("b",labelpad=5) #设置坐标轴的名称,和距离坐标轴的距离
ax1.set_xlabel(u"横坐标信息 abcdee",labelpad=1) #设置中文信息
ax1.text(2.3, 1.5, "$A^{RMSE}$" + " $A_{RMSE}$" , fontsize=10) #给图片添加文字,并设置为斜体,上下标
ax2 = fig.add_subplot(222)
ax2.plot(a,b)
ax3 = fig.add_subplot(224)
ax3.fill(a,b)
plt.show()
initNumb()
plotShow2()
4、“出图”
这是属于最后一步了,刚开始的时候,我都是选择简单的使用QQ或者微信的截图功能,把这个图片裁剪下来,如果给别人一个示意图的时候可以使用。但是分辨率不太高,然后我又通过上图中,左下方的保存按钮,出来的图片分辨率也不太高。现在提供一个简单,而且输出分辨率还能自己定义的方法。例子如下:
plt.savefig(r"E:\OUTFile\abc.jpg", dpi=500, bbox_inches='tight') #设置输出位置,输出分辨率,是否需要图片外的空白部分
plt.show()

到这里在python中进行图的显示和输出,就基本上能够满足需求了。颜色、字号大小之类的大家可以根据自己的需求修改。还有一些特殊的设置,如每个子图占的位置能不能自己调节和设置,也是可以的,参考gridspec属性设置。
好了,如果大家在画图方面,有好的建议和教程,欢迎在评论区留言推荐,大家共同进步。(转载请注明出处)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









