







数据库架构设计与多ORM动态数据库库的使用
1 ) 概述
- 我们现在请求一个接口,比如:/api/getUsers , 在这里设置了一个 Headers
- 里面有一个叫 x-tenant-id,这是一个标识,默认值是 default,还可以是 default2 或 default3
- 每次修改这个请求头,响应都不同
2 )架构1
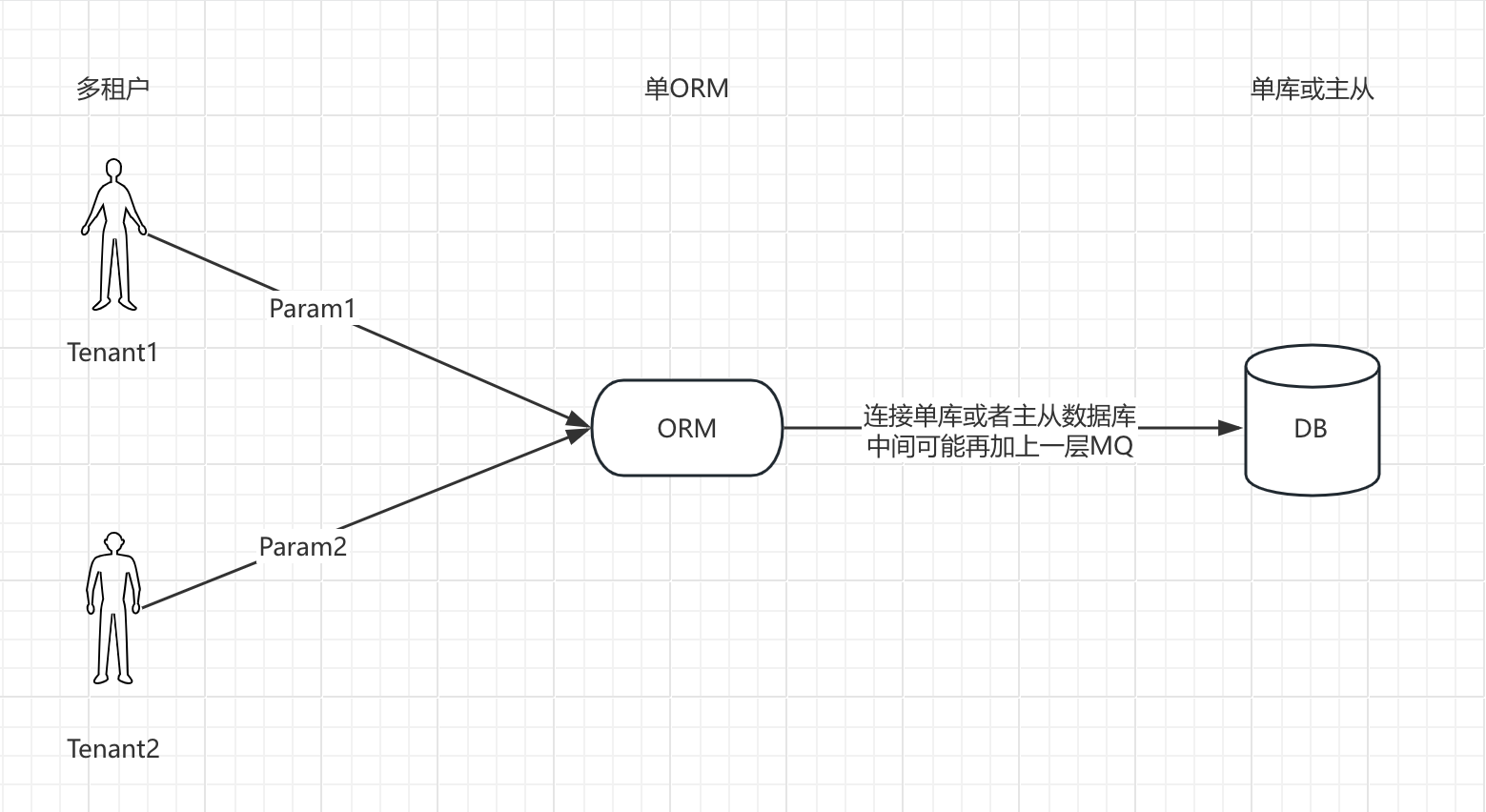
- 从请求侧发送不同参数到我们的 ORM 库,ORM 库连接到数据库,数据库侧响应回前端不同的数据。
- 可能其中没有 ORM 库,只是服务端发送不同场景
- 但实际上这是最简单的业务场景,我们现在做的是在此基础上的扩展
- 有时候,一个数据库会遇到很多问题,比如硬件限制、单库数据集中、安全性不高、扩展性和安全性有问题等,这种架构明显不符合常见应用场景。
- 常见场景可能右侧有两个数据库,一个主数据库负责写,一个从数据库负责读,或者有数据库前置中间件,如 Redis 增加数据库读性能,也可以用 Redis 做队列或专门的队列工具中间件往数据库写数据,以提升整个应用系统性能
3 ) 架构2
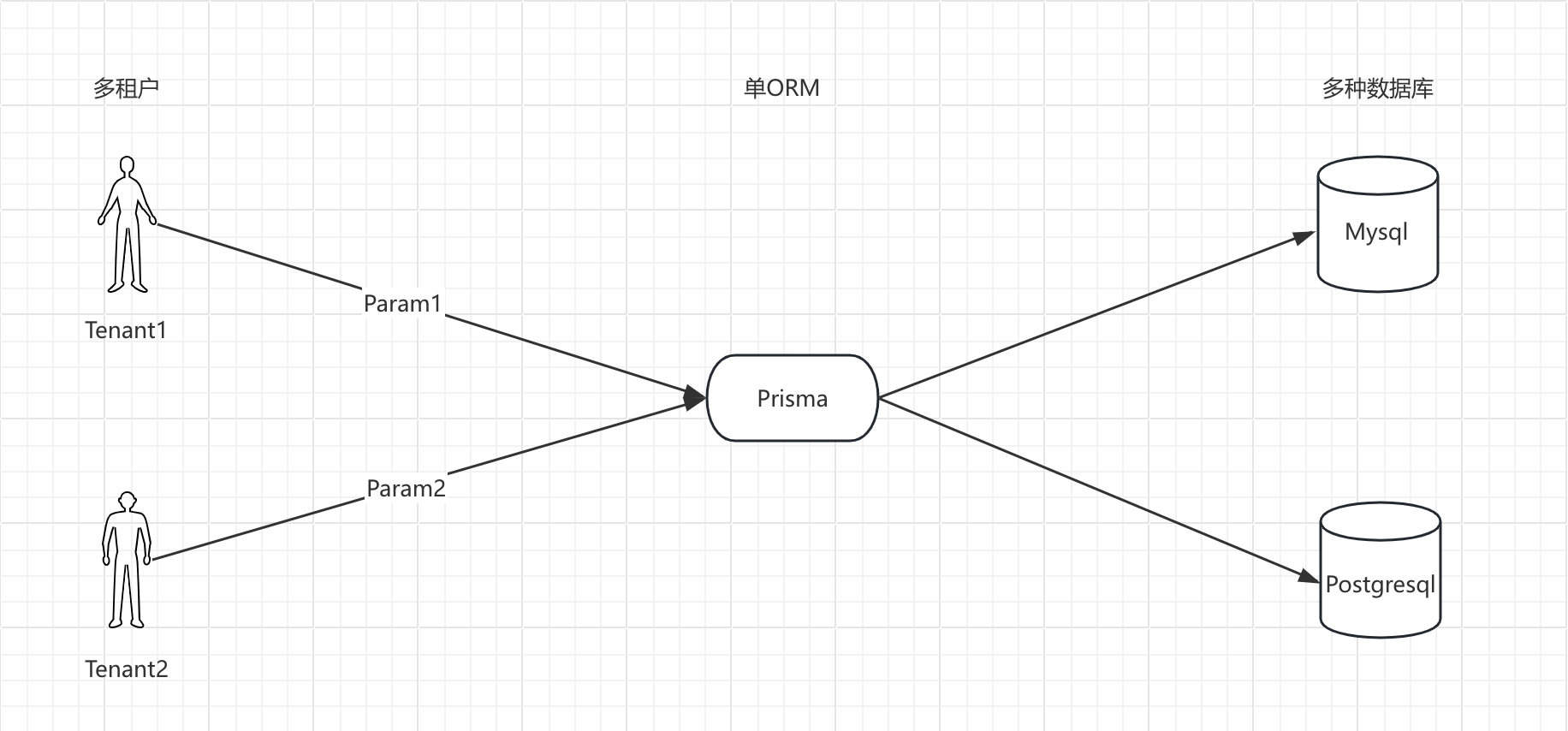
- 系统架构是针对具体业务应用场景和系统环节做的升级或扩展,架构师要考量整个系统的可扩展性
- 如果原先写代码没使用 ORM 库,后续扩展成多数据库应用场景,之前的驱动就无法对接后面的数据库,之前写的 SQL 查询和业务都会受干扰,调整成本很高
- 而架构师选定中间的 ORM 库方案后,后续即使有多个数据库,都可通过一个 ORM 库的模型对接不同数据库,生成不同表格结构
- 但后续可能会有数据库成本和数据库维护的成本问题,这种业务场景通常能覆盖大多数小伙伴的应用场景
- 当前架构应用的前提是架构1中的单库场景不满足安全性和可扩展性需求,进入生产阶段,通常会在同一种数据库类型上扩展
- 多数据库应用场景可能是用户要求,也可能是原数据库在特定业务场景下性能达不到要求,需要特定数据库的插件或功能。例如,关系型数据库适合业务系统,非关系型数据库适合存储小图片、二进制数据;消息应用场景中频繁产生系统消息时,用 MongoDB 存储数据很方便
- 这种架构在安全性方面解决了单库的一些列问题,同时扩展性也非常好,但是也有一些问题
- 一是多样性管理问题,不同数据库使用 ORM 库操作时,代码书写形式可能不同,需要加一层来操作不同数据库
- 二是迁移复杂性问题,单数据库升级可直接创建 migration,多数据库时,不同数据库的 SQL 语句和语法不同,不能随便创建 migration,因为不同数据库sql语句和语法可能是不一样的
- 三是配置问题,不同用户要求存放数据库的位置可能不同
- 多数据库对接有逻辑隔离和物理隔离两种方式
- 逻辑隔离可能将 tanant1 和 tanant2 存放在同一个数据库,比如都是做订单的
- 物理隔离则是将两者存放在不同的数据库,保证了用户数据的安全性和完整性,后续还可进行读写分离和扩展
- 选择物理隔离还是逻辑隔离,要从安全性和资源利用率方面考量
4 ) 架构3
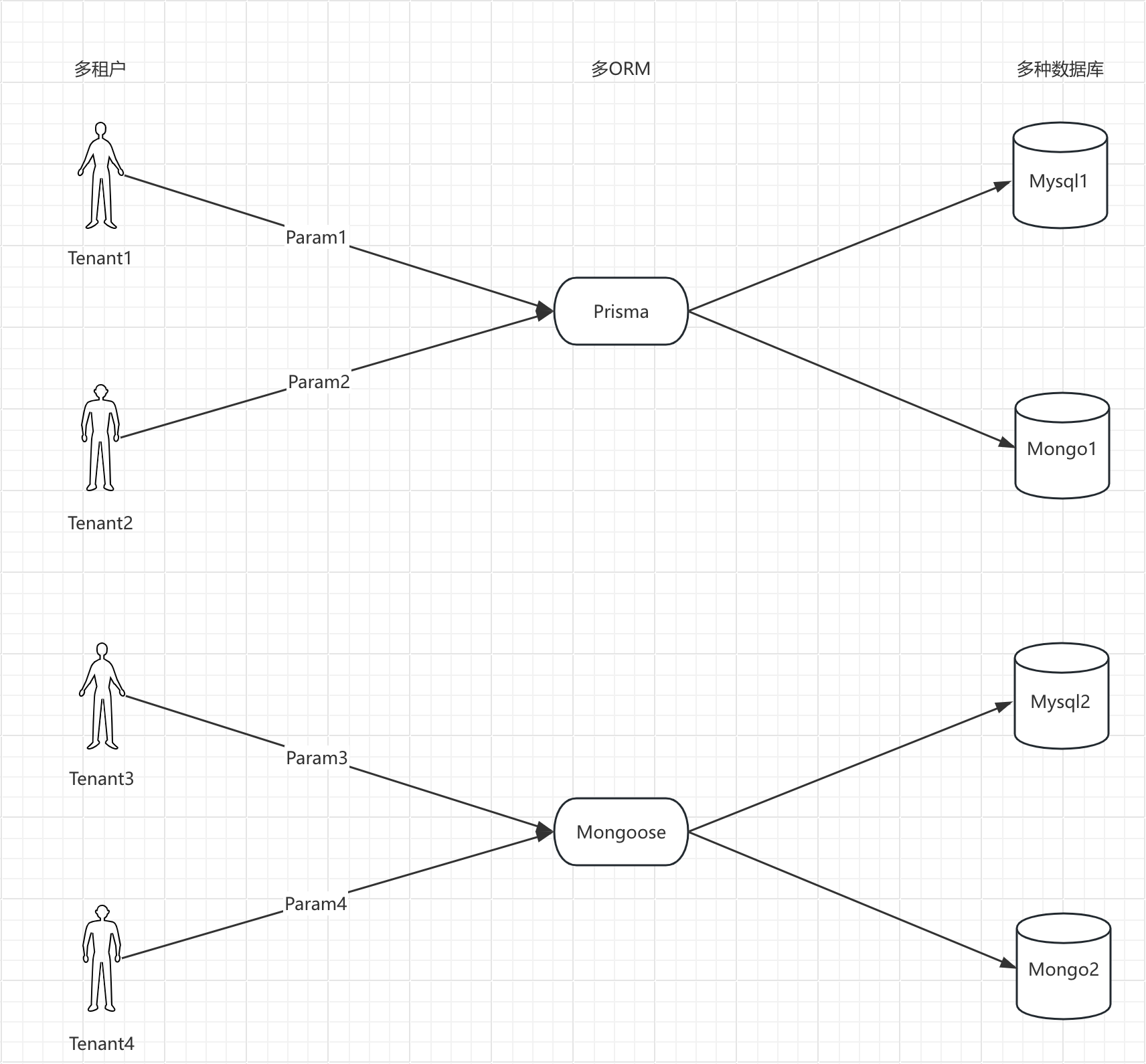
- 与之前的架构图相比,中间变得复杂,采用多 ORM 库对接多种数据库,是因为单一 ORM 库对接数据库有问题、有瓶颈和版本限制
- 但绝大多数应用场景可能用不到多 ORM 库,通常是一个 ORM 库对接多个数据库
- 当数据库是动态的,即用户提供数据库配置,程序要与用户侧数据库对接时,就可能用到当前架构
- 合理做法是根据不同数据库连接指定不同 ORM 实例,创建对应连接来操作数据库
5 )架构4
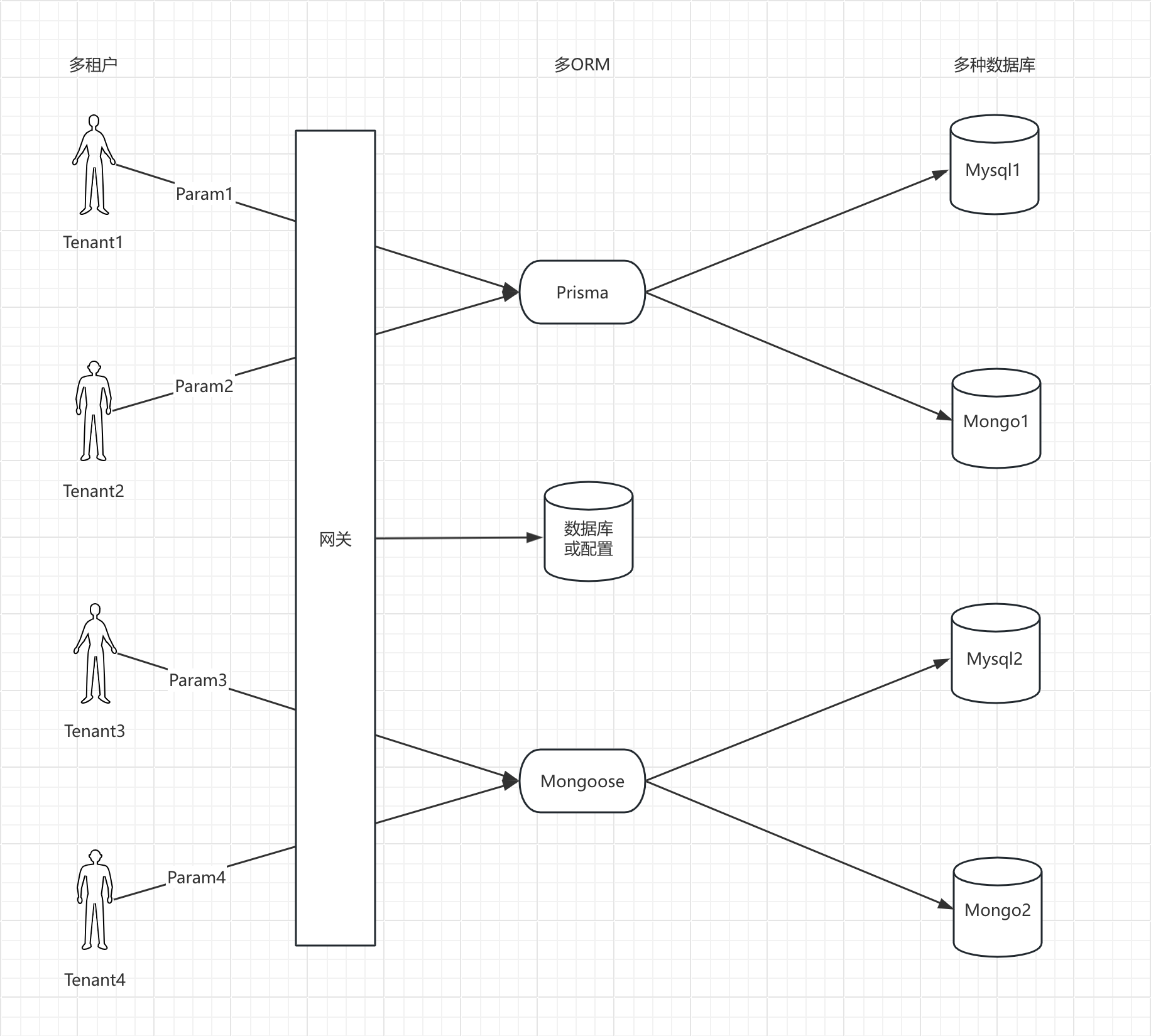
- 还可结合微服务,不同微服务对接不同数据库
- 如设计一个网关层对接后面的微服务,网关层根据默认数据库存储的用户数据库配置信息
- 选择不同微服务加载对应数据库的数据,每个微服务基本上是用到的一种ORM库,而非多种
- 如果用户侧数据库连接信息固定,也可用配置文件存储, 比如调用一个配置中心 consul 或 nacos
- 这样,可以把不同用户分配到不同微服务上去,调用不同的数据库
- 后续还可以有一个服务中心,用于管理不同微服务的注册
架构选择
- 在具体业务场景中,要根据自身情况选择架构
- 比如简单商城服务,可选择扩展性好的架构;低代码项目,用户对数据隐私敏感,适合当前架构
- 如果出现安全、性能、稳定性问题,可扩展相对薄弱的部分,如网关承载能力不足就扩展网关做负载均衡,ORM 库受限就扩展 ORM,数据库写性能受限就扩展数据库分库分表等
- 数据库架构设计和系统架构设计没那么复杂,关键是关注核心部分,很多人做不好架构设计可能是业务经验不足
- 现在借助 AI 系统和大模型能力,我们可以更系统地了解不熟悉的领域,做业务技术选型和架构方案是个倒推过程,根据具体业务倒逼自己学习
多租户总结
- 不同租户请求到不同数据库,使用不同 ORM 方案
- 这里涉及一个类似网关层的部分,读取不同数据库配置连接信息,根据信息选择不同 ORM 连接数据库
- 并且在服务器侧,针对同一个租户用户可创建一个连接池
- 用户访问时,若连接已创建就直接使用,否则重新创建数据库连接
数据连接池及常见 ORM 库配置
- 虽然 Node 是非阻塞 IO,我们可以借助 Node 的异步特性实现良好的性能
- 但如果在服务端使用 Node 对接数据库层面,数据库是同步操作,并非异步数据库
- 那么,如何让数据库利用本地服务器的多线程特性呢?很多服务器是多核的,多核意味着可以实现多线程
- 我们可以利用本地的多核多线程特性,让数据库拥有一个连接池,连接池说白了就是有多个数据库连接实例
-
我们通过 Node 操作这个连接池,就像同时有十条线路连接到数据库,这十条线路可以处理数据库的查询请求,并响应 Node 侧使用的 ORM 库
-
需要注意的是,连接池并非越大越好,因为 CPU 的核数是一定的,而且每个实例都需要占用一定的内存,实际上,市面上现有的 ORM 库,包括数据库本身都支持连接池,所以我们无需单独维护连接池,只要设置一个属性,ORM 库就能实现数据库连接池的特性
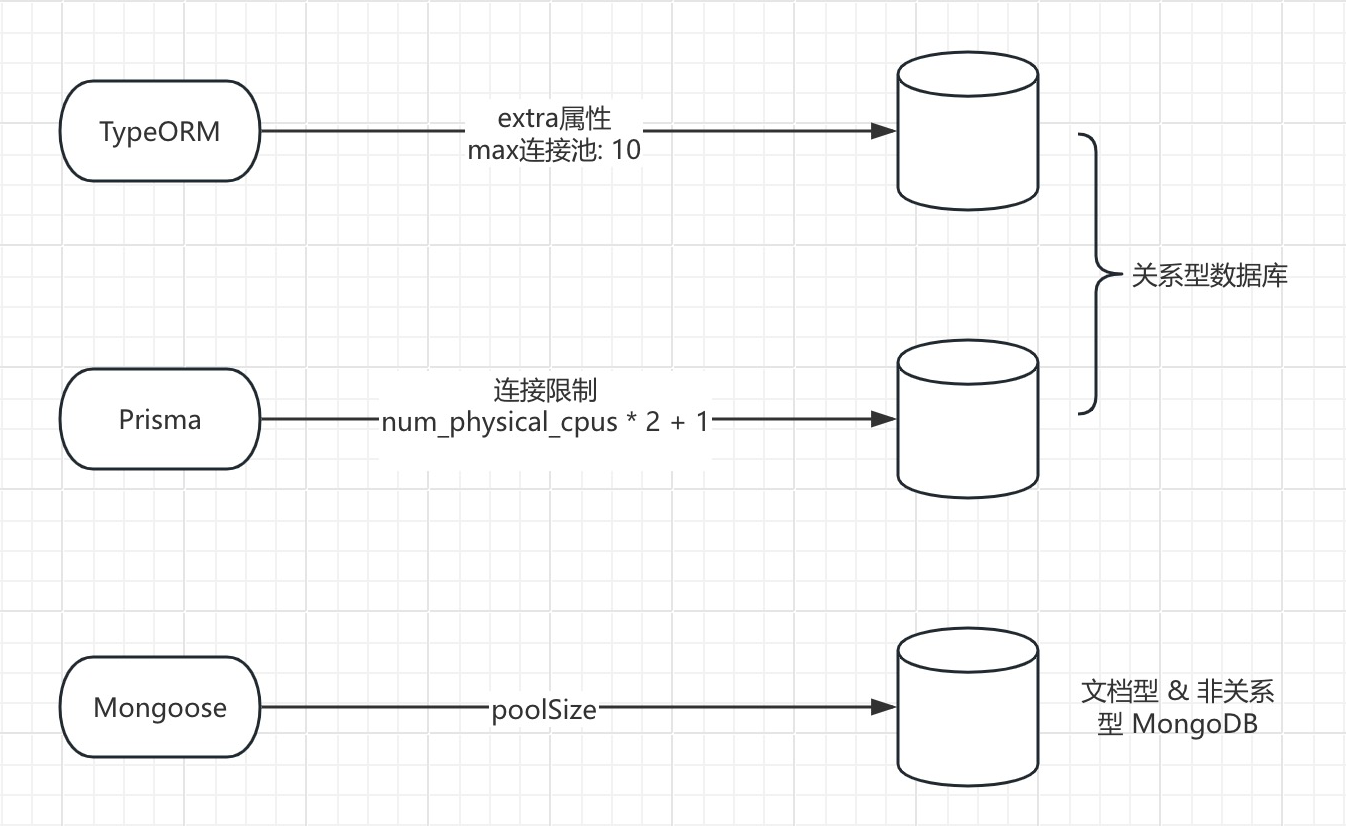
1 )Typeorm 连接池
- 文档:data-source-options/#common-data-source-options
- 里面有一个属性叫
poolSize,设置最大连接池属性即可,无需再关注其他方面 - 之后直接操作 ORM 就行,它会管理连接池,有自己的一套机制
2 ) Prisma 连接池
- 文档: databases-connections/connection-pool
- 文档中有句话提到“the query engine manages connection pool of database connections”,即查询引擎会自行管理整个连接池。当 Prisma Client 客户端首次连接到数据库时,会创建一个连接池
- 可能通过两种方式出现
- 一是进行具体的数据库查询或调用
$connect() - 二是首次进行查询(
query)时,也会自动调用connect
- 一是进行具体的数据库查询或调用
- 关于连接池的配置,点击 connection-pool#connection-pool-size
- 通常建议的连接池大小或数量是根据 CPU 的物理核数乘以二再加一
num_physical_cpus * 2 + 1
- 比如数据库服务器的 CPU 是四核(这里指的是物理 CPU 核数,而非线程数)
- 我们可以通过连接字符串传递一个叫
connectionLimit的参数来配置连接池,非常方便datasource db { provider = "postgresql" url = "postgresql://johndoe:mypassword@localhost:5432/mydb?connection_limit=5" }
- 通常建议的连接池大小或数量是根据 CPU 的物理核数乘以二再加一
3 ) Mongoose 连接池
-
官网: connections
-
点击下面的 connections.html#connection_pools
// With object options mongoose.createConnection(uri, { maxPoolSize: 10 }); // With connection string options const uri = 'mongodb://127.0.0.1:27017/test?maxPoolSize=10'; mongoose.createConnection(uri);- 里面有个属性叫
maxPoolSize,可以很方便地进行设置 - 也可以通过 URL 的方式设置
maxPoolSize属性来设置连接池
- 里面有个属性叫
-
甚至在 Mongoose 的官方网站上,还介绍了多租户的连接方式 connections.html#multi-tenant-connections
-
这是一篇专门的文章讲解如何 使用 Mongoose 对接多租户场景
-
下面多租户的示例只是在当前链接上切换不同的数据库,是在当前的
27017数据库上创建数据库,而非链接到不同端口或位置的数据库const express = require('express'); const mongoose = require('mongoose'); mongoose.connect('mongodb://127.0.0.1:27017/main'); mongoose.set('debug', true); mongoose.model('User', mongoose.Schema({ name: String })); const app = express(); app.get('/users/:tenantId', function(req, res) { const db = mongoose.connection.useDb(`tenant_${req.params.tenantId}`, { // `useCache` tells Mongoose to cache connections by database name, so // `mongoose.connection.useDb('foo', { useCache: true })` returns the // same reference each time. useCache: true }); // Need to register models every time a new connection is created if (!db.models['User']) { db.model('User', mongoose.Schema({ name: String })); } console.log('Find users from', db.name); db.model('User').find(). then(users => res.json({ users })). catch(err => res.status(500).json({ message: err.message })); }); app.listen(3000); -
其实这个逻辑可以进一步丰富,我们可以重新调用
mongoose.connect,再使用mongoose.model, 再去使用mongoose.connection.useDb -
相当于链接到不同位置,然后将
mongoose.connect的实例存储起来,根据不同用户(租户)连接到不同的主库上去



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











