




 本文介绍了订单系统的架构设计,包括实体类定义与数据库表结构。详细解析了如何通过两层加载方式实现从数据库中获取用户订单及其包含的商品详情。
本文介绍了订单系统的架构设计,包括实体类定义与数据库表结构。详细解析了如何通过两层加载方式实现从数据库中获取用户订单及其包含的商品详情。
1.环境:
1.1首先有三个实体类
Order.java:
package com.tencent.bookstore.order.domain;
import java.util.Date;
import java.util.List;
import com.tencent.bookstore.user.domain.User;
/**
* 订单类
* @author TypantK
*
*/
public class Order {
private String oid;
private Date ordertime;
private double total;
private int state; //四种订单状态:1未付款 2已付款未发货 3已发货未确认 4已确认
private User owner; //订单所有者
private String address;
private List<OrderItem> orderItemList; //当前订单下所有条目
//省略get/set等方法
}
OrderItem.java
package com.tencent.bookstore.order.domain;
import java.util.List;
import com.tencent.bookstore.book.domain.Book;
/**
* 订单条目
* @author TypantK
*
*/
public class OrderItem {
private String iid;
private int count;
private double subtotal;
private Order order; //所属订单
private Book book; //所购买的书
//省略get/set等方法
}
Book.java
package com.tencent.bookstore.book.domain;
import com.tencent.bookstore.category.domain.Category;
public class Book {
private String bid;
private String bname;
private double price;
private String author;
private String image;
private Category category;
//省略get/set等方法
}
1.2数据库表架构设计
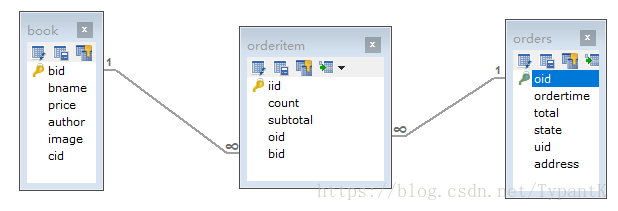
2.实现:
在Dao层写一个方法,通过传入的uid(用户的编号,上面类没写)来查询出当前用户所有的orders(订单)
因为要给orders对象的orderItemList(即订单中的条目)赋值,所以这里需要第一层加载
public List<Order> findByUid(String uid) {
/*
* 通过uid查询出当前用户的所有order
* 循环遍历每个order 为其加载所有的orderitem
*/
try {
String sql = "select * from orders where uid=?";
List<Order> orderList = qr.query(sql, new BeanListHandler<Order>(Order.class), uid);
for(Order order : orderList) { //一个用户有多个订单
loadOrderItems(order);
}
return orderList;
}catch(SQLException e) {
throw new RuntimeException(e);
}
}
而要给List里面的每个orderItem赋值,就要给orderItem里面的每个Book类赋一个对象,所以这里需要第二层加载
/**
* 加载指定订单所有的订单条目
* @param order
*/
private void loadOrderItems(Order order) throws SQLException{
/*
* 要查询两张表:orderitem和book(因为orderitem里面有bid,要用到book表里面的信息)
*/
String sql = "select * from orderitem i, book b where i.bid=b.bid and oid=?";
/*
* 因为一行结果集对应的不再是一个javabean(OrderItem+Book),所以不能再使用BeanListHandler
* 而是使用MapListHandler
* mapList是多个map,每个map对应一行结果集
*/
List<Map<String,Object>> mapList = qr.query(sql, new MapListHandler(), order.getOid());
/*
* 用map生成两个对象:OrderItem Book 然后建立两者的关系(将Book设置给OrderItem
*/
List<OrderItem> orderItemList = toOrderItemList(mapList);
order.setOrderItemList(orderItemList);
}
/**
* 将mapList中每个map转换成两个对象并建立关系
* @param mapList
* @return
*/
private List<OrderItem> toOrderItemList(List<Map<String, Object>> mapList) {
List<OrderItem> orderItemList = new ArrayList<OrderItem>(); //用来装已经加载好Book类的orderItem的集合
for(Map<String,Object> map : mapList) {
OrderItem item = toOrderItem(map);
orderItemList.add(item);
}
return orderItemList;
}
/**
* 把一个Map转化成一个OrderItem对象和Book对象,并将Book对象赋值给OrderItem对象(即建立关系)
*/
private OrderItem toOrderItem(Map<String, Object> map) {
OrderItem orderItem = CommonUtils.toBean(map, OrderItem.class);
Book book = CommonUtils.toBean(map, Book.class);
orderItem.setBook(book);
return orderItem;
}
/**
* 把map转换成对象
* @param map
* @param clazz
* @return
*
* 把Map转换成指定类型
*/
@SuppressWarnings("rawtypes")
public static <T> T toBean(Map map, Class<T> clazz) {
try {
/*
* 1. 通过参数clazz创建实例
* 2. 使用BeanUtils.populate把map的数据封闭到bean中
*/
T bean = clazz.newInstance();
ConvertUtils.register(new DateConverter(), java.util.Date.class);
BeanUtils.populate(bean, map);
return bean;
} catch(Exception e) {
throw new RuntimeException(e);
}
}
3.总结:
主要难点就是 加载+循环 之间的交融
第一层循环:遍历指定用户的所有order(订单)
for(Order order : orderList) { //一个用户有多个订单
loadOrderItems(order);
}
第二层循环:遍历指定order的所有orderItem(订单条目)
for(Map<String,Object> map : mapList) { //一个订单有多个订单项
OrderItem item = toOrderItem(map);
orderItemList.add(item);
}
第一层加载:给每一个order的orderItemList赋对象,通过每一次的第二层循环来对每一个orderItem赋对象
第二层加载:给每一个orderItem的book赋对象

















 172万+
172万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









