 Pytorch学习:环境、基础与数据集应用
Pytorch学习:环境、基础与数据集应用





1 Pytorch 初始
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用。与Tensorflow的静态计算图不同,pytorch的计算图是动态的,可以根据计算需要实时改变计算图。但由于Torch语言采用 Lua,导致在国内一直很小众,并逐渐被支持 Python 的 Tensorflow 抢走用户。作为经典机器学习库 Torch 的端口,PyTorch 为 Python 语言使用者提供了舒适的写代码选择。
1.1 环境配置
Anaconda
便于后续开发 先安装 Anaconda Anaconda | Built to Advance Open Source AI
安装
首先确保你已经安装了GPU环境,即Anaconda、CUDA和CUDNN
利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学)[通俗易懂]-腾讯云开发者社区-腾讯云
win10安装带CUDA的Pytorch看这篇就够了-腾讯云开发者社区-腾讯云
cuda环境配置(anaconda虚拟环境版,含pytorch-gpu安装)_虚拟环境安装cuda-优快云博客
CUDA 版本
python 3.7.16
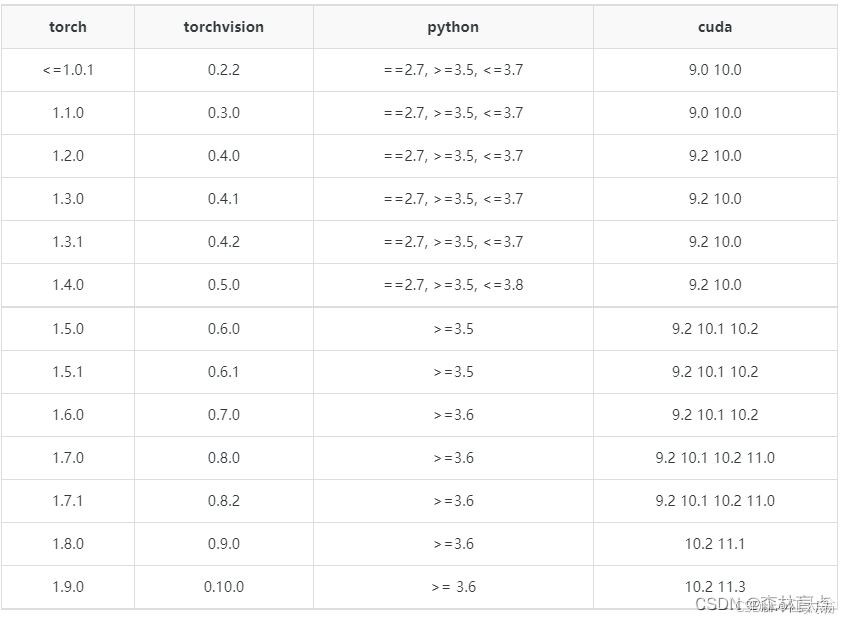
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.htmlPrevious PyTorch Versions | PyTorch
官网会自动显示符合你电脑配置的Pytorch版本,复制指令到conda环境中运行即可
测试是否安装成功
import torch
print(torch.__version__) # pytorch版本
print(torch.version.cuda) # cuda版本
print(torch.cuda.is_available()) # 查看cuda是否可用1.2 API 设计理念对比
-
PyTorch
- 动态计算图:API 支持运行时动态构建计算图,允许灵活修改模型结构,调试时可直接使用 Python 原生调试工具13。
- 直观的类定义:通过继承
nn.Module定义模型,forward方法显式声明前向传播逻辑,代码可读性高23。
-
TensorFlow
- 静态计算图:需预先定义完整计算图(早期版本),适合生产环境优化和部署,但对动态调整模型的支持较弱1。
- Keras 集成:通过高阶 API(如
tf.keras)简化层定义和训练流程,支持快速搭建标准网络
1.3 配置 VSCode 使用 Conda 环境
vscode 选择 配置好的 env_cuda内核环境
2 PyTorch核心基础
2.1 张量(Tensor)
- 定义与创建:张量是PyTorch的基础数据结构,支持多种初始化方式(随机、零矩阵等),并兼容GPU加速计算
- 运算与广播:支持加减乘除、矩阵乘法(
torch.matmul)、索引切片等操作,与NumPy语法高度兼容
2.1 .1 基础数据创建
-
直接数据转换
-
torch.tensor(data):根据已有数据(如标量、列表、元组、numpy.ndarray)创建 Tensor,默认自动推断数据类型,支持手动指定dtype和device。
特性:完全拷贝数据,不与原数据共享内存15。# 示例:从列表创建
a = torch.tensor([2, 3.4]) # 推断为 float32
b = torch.tensor([[1, 2], [3, 4]]) # 推断为 int64 -
torch.as_tensor(data):与torch.tensor()类似,但若输入为numpy.ndarray或已有 Tensor 时共享内存5。n = np.array([1, 2]) t = torch.as_tensor(n) # 共享内存,修改 t 会影响 n
-
-
从 NumPy 转换
torch.from_numpy(ndarray):将numpy.ndarray转换为 Tensor,共享内存
arr = np.array([[1, 2], [3, 4]]) tensor = torch.from_numpy(arr)
2.1.2、指定形状或数值的初始化
-
无初始化创建
torch.Tensor(shape)/torch.FloatTensor(shape):根据形状创建未初始化的 Tensor(数值随机)x = torch.Tensor(3, 4) # 3×4 未初始化的 float32 Tensor y = torch.IntTensor(2, 2) # 2×2 未初始化的 int32 Tensor
-
全值初始化
-
torch.zeros(shape)/torch.ones(shape):创建全 0 或全 1 Tensorz = torch.zeros(2, 3) # 2×3 全 0 Tensor o = torch.ones(5) # 长度为 5 的全 1 Tensor -
torch.full(shape, value):填充指定数值的 Tensorf = torch.full((2, 2), 5) # 2×2 全 5 的 Tensor
-
-
序列生成
-
torch.arange(start, end, step):生成等差数列a = torch.arange(0, 10, 2) # tensor([0, 2, 4, 6, 8]) -
torch.linspace(start, end, steps):生成等间隔数值序列b = torch.linspace(0, 1, 5) # tensor([0.0, 0.25, 0.5, 0.75, 1.0])
-
2.1.3、特殊类型与设备指定
-
数据类型控制
- 通过
dtype参数显式指定类型(如torch.float32、torch.int64)t = torch.tensor([1, 2], dtype=torch.float16)
- 通过
-
设备切换
- 使用
device参数将 Tensor 分配至 GPU 或 CPUgpu_tensor = torch.tensor([1, 2], device='cuda') cpu_tensor = gpu_tensor.cpu() # 移回 CPU
- 使用
-
布尔与稀疏 Tensor
torch.BoolTensor(data):创建布尔类型 Tensor。torch.sparse_coo_tensor(indices, values, shape):创建稀疏 Tensor
2.1.4、API 对比与适用场景
| 方法 | 特点 | 适用场景 |
|---|---|---|
torch.tensor() | 安全拷贝数据,避免内存共享 | 需独立数据副本时使用 |
torch.as_tensor() | 共享内存,提升效率 | 处理大规模数据且无需修改原数据时 |
torch.from_numpy() | 与 NumPy 无缝交互 | 快速转换已有 NumPy 数据 |
torch.Tensor(shape) | 快速创建未初始化 Tensor | 需后续填充数据时 |
2.2 Tensor 运算
所有的带_符号的函数都会对原数据进行修改
2.2.1、基本数学运算
-
逐元素运算
加法/减法/乘法/除法:直接使用运算符或函数
a = torch.tensor([1, 2])
b = torch.tensor([3, 4])# 运算符形式
c = a + b # tensor([4, 6])
d = a * b # tensor([3, 8])# 函数形式
e = torch.add(a, b) # tensor([4, 6])
f = torch.mul(a, b) # tensor([3, 8])
2. 绝对值与幂运算
x = torch.tensor([-2, 3])
y = torch.abs(x) # tensor([2, 3])
z = torch.pow(x, 2) # tensor([4, 9])
2.2.2、矩阵与高维运算
-
矩阵乘法
-
二维矩阵乘法:
torch.mm或@运算符m1 = torch.randn(2, 3)m2 = torch.randn(3, 4)result = torch.mm(m1, m2) # 2×4 矩阵result_alt = m1 @ m2 # 等价写法 -
批量矩阵乘法:
torch.bmm(要求输入为三维张量)batch1 = torch.randn(5, 2, 3)batch2 = torch.randn(5, 3, 4)output = torch.bmm(batch1, batch2) # 5×2×4 -
高维通用乘法:
torch.matmul(支持广播机制)a = torch.randn(3, 4) b = torch.randn(4, 5) c = torch.matmul(a, b) # 3×5
-
-
张量拼接与分割
-
拼接:
torch.cat(沿指定维度拼接)t1 = torch.tensor([[1, 2], [3, 4]])t2 = torch.tensor([[5, 6]])combined = torch.cat([t1, t2], dim=0) # 3×2 -
分割:
torch.split(按尺寸分割)t = torch.arange(10).reshape(2, 5)chunks = torch.split(t, 2, dim=1) # 分割为 2×2 和 2×3
-
2.2.3、归并与索引运算
-
归并操作
- 求和/均值:
torch.sum、torch.meanx = torch.tensor([[1, 2], [3, 4]], dtype=torch.float)sum_all = torch.sum(x) # 10.0sum_dim0 = torch.sum(x, dim=0) # tensor([4., 6.])mean_dim1 = torch.mean(x, dim=1) # tensor([1.5, 3.5])
- 求和/均值:
-
条件索引
-
布尔掩码:
torch.masked_selectdata = torch.tensor([[1, 2], [3, 4]])mask = data > 2selected = torch.masked_select(data, mask) # tensor([3, 4]) -
索引收集:
torch.gather(按索引聚合)t = torch.tensor([[1, 2], [3, 4]])indices = torch.tensor([[0, 0], [1, 0]])gathered = torch.gather(t, dim=1, index=indices) # [[1, 1], [4, 3]]
-
2.2.4、梯度相关运算
-
自动微分
x = torch.tensor(2.0, requires_grad=True)y = x**2 + 3 y.backward()print(x.grad) # 输出梯度值:4.0 -
梯度清零
optimizer = torch.optim.SGD([x], lr=0.1)optimizer.zero_grad() # 清空历史梯度
注:上述 API 需结合张量设备和数据类型使用(如 dtype=torch.float32 或 device='cuda'),避免计算错误
2.3 CUDA
- CUDA Toolkit:提供 GPU 计算驱动和编译器(如 NVCC)
- cuDNN:专为深度学习的加速库,需与 CUDA 版本匹配
2.3.1 CUDA 初始化与设备管理
- 设备检测:使用
torch.cuda.is_available()验证 GPU 是否可用,并通过torch.cuda.device_count()获取设备数量 - 设备切换:通过
tensor.to("cuda:0")或model.cuda()将数据/模型迁移至 GPU
# 示例:CUDA 初始化
if torch.cuda.is_available():
device = torch.device("cuda:0")
tensor = torch.randn(3, 3).to(device)
2.3.2、CUDA 加速技术与性能优化
-
自定义 CUDA 内核
- 应用场景:针对特定算子(如矩阵乘法、归约操作)编写高性能内核,替代 PyTorch 原生实现
- 实现流程:
- 使用 C++/CUDA 编写内核,通过 PyBind11 封装为 Python 接口
- 调用
torch.utils.cpp_extension.load()动态编译内核
# 示例:加载自定义 CUDA 算子from torch.utils.cpp_extensionimport loadcuda_module = load(name="custom_op", sources=["custom_op.cpp", "custom_op.cu"])
-
混合精度训练
- 半精度(FP16)加速:通过
torch.cuda.amp自动管理精度转换,减少显存占用并提升计算速度# 示例:混合精度训练scaler = torch.cuda.amp.GradScaler()with torch.autocast(device_type="cuda", dtype=torch.float16): outputs = model(inputs) loss = criterion(outputs, labels) scaler.scale(loss).backward()
- 半精度(FP16)加速:通过
-
多 GPU 并行
- 数据并行:
torch.nn.DataParallel或torch.nn.DistributedDataParallel实现多卡训练 - 流水线并行:适用于超大模型,分割模型至不同 GPU
- 数据并行:
2.4 Transforms 预处理与数据增强
数据预处理和增强对于提高模型的性能至关重要。
PyTorch 提供了 torchvision.transforms 模块来进行常见的图像预处理和增强操作,如旋转、裁剪、归一化等。
常见的图像预处理操作:
import torchvision.transforms as transforms
from PIL import Image
# 定义数据预处理的流水线
transform = transforms.Compose([
transforms.Resize((128, 128)), # 将图像调整为 128x128
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 加载图像
image = Image.open('image.jpg')
# 应用预处理
image_tensor = transform(image)
print(image_tensor.shape) # 输出张量的形状2.5 数据集
在深度学习任务中,数据加载和处理是至关重要的一环。
2.5.1 数据加载和处理工具
PyTorch 提供了强大的数据加载和处理工具,主要包括:
-
torch.utils.data.Dataset:数据集的抽象类,需要自定义并实现__len__(数据集大小)和__getitem__(按索引获取样本)。 -
torch.utils.data.TensorDataset:基于张量的数据集,适合处理数据-标签对,直接支持批处理和迭代。 -
torch.utils.data.DataLoader:封装 Dataset 的迭代器,提供批处理、数据打乱、多线程加载等功能,便于数据输入模型训练。 -
torchvision.datasets.ImageFolder:从文件夹加载图像数据,每个子文件夹代表一个类别,适用于图像分类任务。
2.5.2 内置数据集
PyTorch 通过 torchvision.datasets 模块提供了许多常用的数据集,例如:
- MNIST:手写数字图像数据集,用于图像分类任务。
- CIFAR:包含 10 个类别、60000 张 32x32 的彩色图像数据集,用于图像分类任务。
- COCO:通用物体检测、分割、关键点检测数据集,包含超过 330k 个图像和 2.5M 个目标实例的大规模数据集。
- ImageNet:包含超过 1400 万张图像,用于图像分类和物体检测等任务。
- STL-10:包含 100k 张 96x96 的彩色图像数据集,用于图像分类任务。
- Cityscapes:包含 5000 张精细注释的城市街道场景图像,用于语义分割任务。
- SQUAD:用于机器阅读理解任务的数据集。
以上数据集可以通过 torchvision.datasets 模块中的函数进行加载,也可以通过自定义的方式加载其他数据集。
2.5.3 torchvision 和 torchtext
- torchvision: 一个图形库,提供了图片数据处理相关的 API 和数据集接口,包括数据集加载函数和常用的图像变换。
- torchtext: 自然语言处理工具包,提供了文本数据处理和建模的工具,包括数据预处理和数据加载的方式。
2.5.4 自定义数据集
torch.utils.data.Dataset
Dataset 是 PyTorch 中用于数据集抽象的类。
自定义数据集需要继承 torch.utils.data.Dataset 并重写以下两个方法:
__len__:返回数据集的大小。__getitem__:按索引获取一个数据样本及其标签。
import torch
from torch.utils.data import Dataset
# 自定义数据集
class MyDataset(Dataset):
def __init__(self, data, labels):
# 数据初始化
self.data = data
self.labels = labels
def __len__(self):
# 返回数据集大小
return len(self.data)
def __getitem__(self, idx):
# 按索引返回数据和标签
sample = self.data[idx]
label = self.labels[idx]
return sample, label
# 生成示例数据
data = torch.randn(100, 5) # 100 个样本,每个样本有 5 个特征
labels = torch.randint(0, 2, (100,)) # 100 个标签,取值为 0 或 1
# 实例化数据集
dataset = MyDataset(data, labels)
# 测试数据集
print("数据集大小:", len(dataset))
print("第 0 个样本:", dataset[0])2.6 DataLoader
torch.utils.data.DataLoader
DataLoader 是 PyTorch 提供的数据加载器,用于批量加载数据集。
提供了以下功能:
- 批量加载:通过设置
batch_size。 - 数据打乱:通过设置
shuffle=True。 - 多线程加速:通过设置
num_workers。 - 迭代访问:方便地按批次访问数据。
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# 自定义数据集
class MyDataset(Dataset):
def __init__(self, data, labels):
# 数据初始化
self.data = data
self.labels = labels
def __len__(self):
# 返回数据集大小
return len(self.data)
def __getitem__(self, idx):
# 按索引返回数据和标签
sample = self.data[idx]
label = self.labels[idx]
return sample, label
# 生成示例数据
data = torch.randn(100, 5) # 100 个样本,每个样本有 5 个特征
labels = torch.randint(0, 2, (100,)) # 100 个标签,取值为 0 或 1
# 实例化数据集
dataset = MyDataset(data, labels)
# 实例化 DataLoader
dataloader = DataLoader(dataset, batch_size=10, shuffle=True, num_workers=0)
# 遍历 DataLoader
for batch_idx, (batch_data, batch_labels) in enumerate(dataloader):
print(f"批次 {batch_idx + 1}")
print("数据:", batch_data)
print("标签:", batch_labels)
if batch_idx == 2: # 仅显示前 3 个批次
break2.7 Dataset 与 DataLoader 的自定义应用
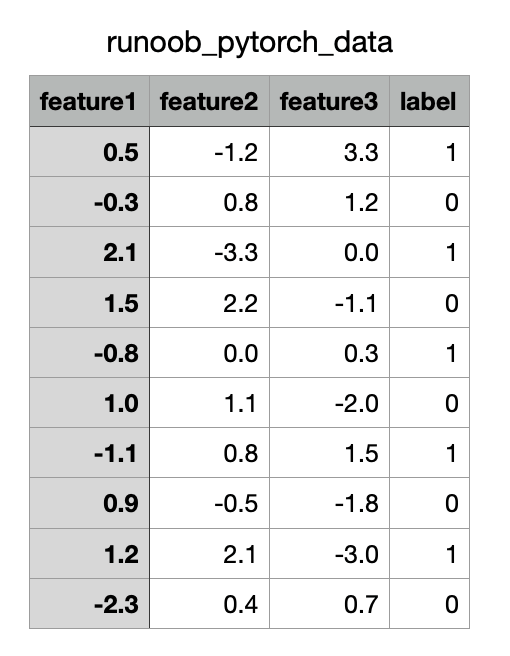
以下是一个将 CSV 文件 作为数据源,并通过自定义 Dataset 和 DataLoader 读取数据。
CSV 文件内容如下(下载runoob_pytorch_data.csv):
import torch
import pandas as pd
from torch.utils.data import Dataset, DataLoader
# 自定义 CSV 数据集
class CSVDataset(Dataset):
def __init__(self, file_path):
# 读取 CSV 文件
self.data = pd.read_csv(file_path)
def __len__(self):
# 返回数据集大小
return len(self.data)
def __getitem__(self, idx):
# 使用 .iloc 明确基于位置索引
row = self.data.iloc[idx]
# 将特征和标签分开
features = torch.tensor(row.iloc[:-1].to_numpy(), dtype=torch.float32) # 特征
label = torch.tensor(row.iloc[-1], dtype=torch.float32) # 标签
return features, label
# 实例化数据集和 DataLoader
dataset = CSVDataset("runoob_pytorch_data.csv")
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
# 遍历 DataLoader
for features, label in dataloader:
print("特征:", features)
print("标签:", label)
break输出结果:
特征: tensor([[ 1.2000, 2.1000, -3.0000],
[ 1.0000, 1.1000, -2.0000],
[ 0.5000, -1.2000, 3.3000],
[-0.3000, 0.8000, 1.2000]])
标签: tensor([1., 0., 1., 0.])
tianqixin@Mac-mini runoob-test % python3 test.py
特征: tensor([[ 1.5000, 2.2000, -1.1000],
[ 2.1000, -3.3000, 0.0000],
[-2.3000, 0.4000, 0.7000],
[-0.3000, 0.8000, 1.2000]])
标签: tensor([0., 1., 0., 0.])
2.8 其他
torchvision
conda install torchvision==0.8.2
3 CNN torch.nn
torch.nn 是 PyTorch 中构建和训练神经网络的核心模块,提供了一系列预定义层、损失函数及模型管理工具。以下是其核心功能与使用方法的总结:
【PyTorch】深度学习实践之 CNN基础篇——卷积神经网络跑Minst数据集_pytorch cnn-优快云博客
3.1 MINIST数据集训练
# 导入PyTorch相关模块和函数
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
# transforms用于对图像数据进行预处理,比如将图像转换为张量(tensor)
# import matplotlib.pyplot as plt
import numpy as np
# 全连接层:输入数据格式为batch*28*28,全连接层中各个像素点之间没有关联
# cnn(卷积神经网络):输入数据格式为batch*1*28*28,多了一个channel参数。卷积操作会综合考虑一个窗口内像素点之间的关系,所以各个像素点不是独立的,卷积网络更适合处理图像数据
# 定义超参数
input_size = 28 # 图像的总尺寸是28*28
num_classes = 10 # 标签的种类数,即数字0 - 9共10类
num_epochs = 3 # 训练的总循环周期数
batch_size = 64 # 一个批次(batch)的大小,即每次处理64张图片
# 根据是否有可用的GPU来选择设备,如果有GPU则使用,否则使用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
print('GPU is available!')
else:
print('GPU is not available!')
# 加载训练数据集
# root指定数据集存储的根目录,train=True表示加载训练集,transform将数据转换为张量,download=True表示如果数据集不存在则下载
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
# 加载测试数据集,train=False表示加载测试集
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# 构建训练数据的DataLoader,用于按批次加载训练数据
# dataset指定数据集,batch_size指定批次大小,shuffle=True表示在每个epoch打乱数据顺序
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
# 构建测试数据的DataLoader,用于按批次加载测试数据
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
# 卷积网络模块构建
# 一般卷积层、relu激活层、池化层可以组合成一个处理套餐
# 注意卷积操作最后得到的结果还是一个特征图,需要将其转换为向量才能进行分类或回归任务
# 定义一个卷积神经网络类
class CNN(nn.Module):
def __init__(self):
# 构造函数
# 卷积网络一般是多个操作组合进行的:conv、pool、relu可以看作一个组合
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28),这里1表示灰度图通道数,28*28是图像尺寸
nn.Conv2d( # 2d卷积操作
in_channels=1, # 输入通道数,灰度图为1
out_channels=16, # 要得到的特征图个数,也就是卷积核的个数,这里有16个卷积核
kernel_size=5, # 卷积核大小为5*5
stride=1, # 步长为1
padding=2, # 如果希望卷积后图像大小跟原来一样(当stride=1时),一般按此公式设置padding=(kernel_size - 1) / 2,若不能整除pytorch采用向下取整
), # 输出的特征图为 (16, 28, 28),16个通道,每个通道28*28大小
nn.ReLU(), # relu激活层
nn.MaxPool2d(kernel_size=2), # 进行2x2区域的最大池化操作,输出结果为: (16, 14, 14),池化后尺寸一般是之前的一半
)
self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14),32个通道,每个通道14*14大小
nn.ReLU(), # relu激活层
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2), # 进行池化,输出 (32, 7, 7)
)
self.conv3 = nn.Sequential( # 下一个套餐的输入 (32, 7, 7)
nn.Conv2d(32, 64, 5, 1, 2), # 输出 (64, 7, 7)
nn.ReLU(), # 输出 (64, 7, 7)
)
# 只有池化(pool)操作时才会筛选特征
self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层,将卷积后的特征图转换为10个输出,用于10分类任务,进行wx + b的线性操作来做分类
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # flatten操作,将多维张量转换为二维,结果为:(batch_size, 32 * 7 * 7),和reshape操作类似
# reshape操作:总的元素大小是不变的,给定一个维度后,其他维度自动计算
# 比如当前的x:64*7*7,x.size(0)是64,也就是要从三维转成两维,总的元素个数不变,就变为64*49这样,-1可以简单看成一个占位符号,让系统自动计算维度
# 变换维度,开始是64*7*7,转成batchsize*特征个数,比如64*49
output = self.out(x)
return output
# 定义准确率计算函数
def accuracy(predictions, labels):
pred = torch.max(predictions.data, 1)[1] # 获取预测结果中最大值的索引(预测的类别),只取索引即可
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels)
# 训练网络模型
# 实例化卷积神经网络,并将其移动到指定的设备(GPU或CPU)上
net = CNN().to(device)
# 定义损失函数,这里使用交叉熵损失函数,并将其移动到指定设备上
criterion = nn.CrossEntropyLoss().to(device)
# 定义优化器,使用Adam优化器,学习率为0.001,传入网络的参数
optimizer = optim.Adam(net.parameters(), lr=0.001) # 普通的随机梯度下降算法
# 开始训练循环,遍历每个epoch
for epoch in range(num_epochs):
# 用于保存当前epoch每个batch训练结果的列表
train_rights = []
# 遍历训练数据加载器中的每个批次
for batch_idx, (data, target) in enumerate(train_loader): # 针对容器中的每一个批进行循环
net.train()
data = data.to(device)
target =target.to(device)
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = accuracy(output, target)
train_rights.append(right)
# 每一百个batch进行一次在测试集上的评估
if batch_idx % 100 == 0:
net.eval()
val_rights = []
# 在测试集上进行评估,遍历测试数据加载器中的每个批次
for (data, target) in test_loader:
data = data.to(device)
target =target.to(device)
output = net(data)
right = accuracy(output, target)
val_rights.append(right)
# 计算训练集和测试集的准确率
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data,
100. * train_r[0].cpu().numpy() / train_r[1],
100. * val_r[0].cpu().numpy() / val_r[1]))


















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









