




本文是节选自陈云《深度学习框架PyTorch入门与实践》第四章,我有在自己电脑上亲自测试其代码
因为使用autograd可实现深度学习模型,但其抽象程度较低,如果用其来实现深度学习模型,则需要编写的代码量极大。在这种情况下,torch.nn应运而生,其是专门为深度学习设计的模块。torch.nn和核心数据结构是Module,它是一个抽象的概念,既可以表示神经网络中的某个层(layer),也可以表示一个包含很多层的神经网络。在实际使用中,最常见的做法是继承nn.Module,撰写自己的网络层。下面来先看看如何用nn.Module实现自己的全连接层。全连接层,又名仿射层,输出y和输入x满足y=Wx + b,W和b是可学习的参数。
先看代码:
import torch as t
from torch import nn
from torch.autograd import Variable as V
class Linear (nn.Module):
def __init__(self,in_features,out_features):
super(Linear,self).__init__()
self.w = nn.Parameter(t.randn(in_features,out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self,x):
x = x.mm(self.w)
return x + self.b.expand_as(x)
layer = Linear(4,3)
input = V(t.randn(2,4))
output = layer(input)
output
for name,Parameter in layer.named_parameters():
print(name,Parameter) # w and b
输出如下:
output
Out[6]:
tensor([[-1.7864, 2.4755, -1.8025],
[-0.9060, 1.6661, -0.1183]], grad_fn=<AddBackward0>)
for name,Parameter in layer.named_parameters():
print(name,Parameter) # w and b
w Parameter containing:
tensor([[-0.1576, 1.5763, 0.9441],
[ 0.5559, -0.1769, 1.3767],
[-0.7356, 1.7642, -0.4010],
[ 0.3247, -0.7567, 0.4535]], requires_grad=True)
b Parameter containing:
tensor([-0.1011, -0.2682, 0.1915], requires_grad=True)
可见,全连接层的实现非常简单,其代码量不超过10行,但须注意以下几点:
a.自定义层Linear必须继承nn.Module,并且在其构造函数中需要用nn.Module的构造函数,即:
super(Linear,self). init()或nn.Module.init(self)。
b.在构造函数—init—中必须自己定义可学习的参数,并封装成Parameter,如在本例我们把w和b封装成parameter。parameter是一种特殊的Variable,但其默认需要求导(requires_grad = True),感兴趣的读者可以通过查询nn.parameter查看parameter类的源代码。
c.forward函数实现前向传播过程,其输入可以是一个或多个variable,对x的任何操作也必须是variable支持的操作。
d.无需写反向传播函数,因其前向传播都是对variable进行操作,nn.Module能够利用autograd自动实现反向传播,这一点比Function简单地多。
e.使用时,直观上可将layer看成数学概念中的函数,调用layer(input)即可得到input对应的结果。它等价于layers.–call–(input),在–call–函数中,主要调用的是layer.forward(x),另外还对钩子做了一些处理。所以在实际使用中应尽量使用layer(x)而不是使用layer.forward(x)。
f.Module中的可学习参数可以通过named_parameters()或者parameter()返回迭代器,前者会给每个parameter附上名字,使其更具有辨识度。
可见利用Module实现的全连接层,比利用Function实现的更简单,因其不再需要写反向传播函数。
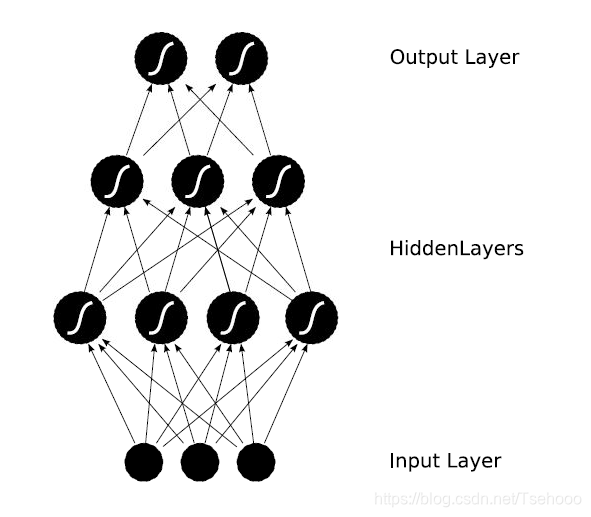
Module能够自动检测到自己的parameter,并将其作为学习参数。除了parameter,Module还包含子Module,主Module能够递归查找子Module中的parameter。下面再来看看稍微复杂一点的网络:多层感知机。
多层感知机的网络结构如下图所示,它由两个全连接层组成,采用sigmoid函数作为激活函数()
为了方便用户使用,PyTorch实现了神经网络中绝大多数的layer,这些layer都继承于nn.Module,封装了可学习参数parameter,并实现了forward函数,且专门针对GPU运算进行了CuDNN优化,其速度和性能都十分优异。具体内容可参照文档,阅读文档时主要关注以下几点
1.构造函数的参数。
2.属性、可学习参数和子module。
3.输入输出的形状。
这些自定义layer对输入形状都有假设:输入的不是单个数据,而是一个batch。若想输入一个数据,必须调用unsqueeze(0)函数将数据伪装成batch_size = 1的batch。
如果想要更深入地理解nn.Module,研究其原理是很有必要的。首先来看看nn,Module基类的构造函数:
def __init__(self):
self._parameters = OrderedDict()
self._modules = OrderedDict()
self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1033
1033




 到【灌水乐园】发言
到【灌水乐园】发言







