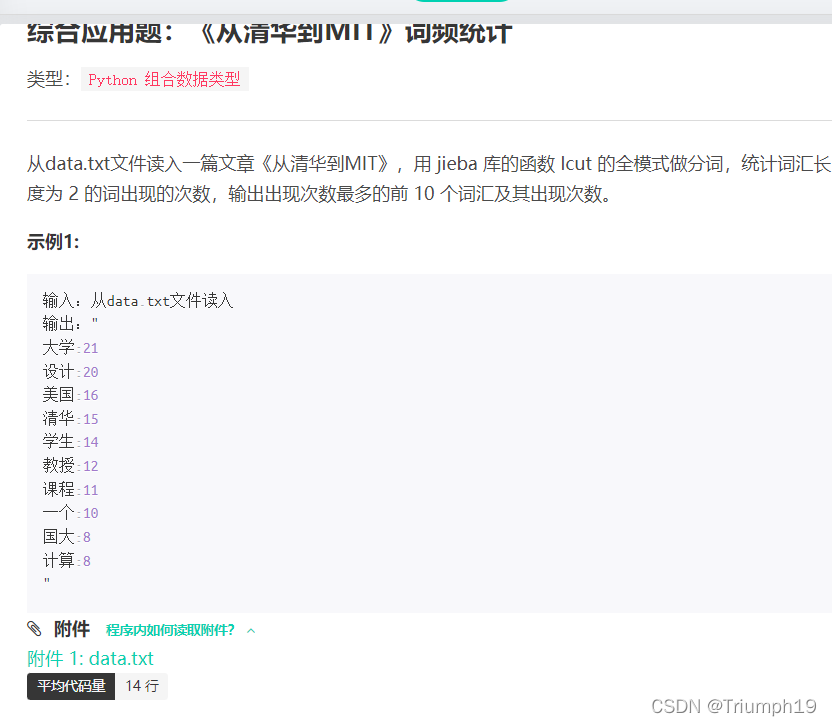
j01词频的统计
f.read()和f.readlines()数据类型
- 前者是字符串类型,后者是列表类型;而jieba.lcut(‘str’)
lcut()和lcut(,True)的区别
- jieba.lcut()函数返回精确模式,输出的分词能够完整且不多余地组成原始文本;jieba.lcut(,True)函数返回全模式,输出原始文本中可能产生的所有词组,冗余性太大
- 以本人代码和书上参考答案说明二者的具体区别:
import jieba
dk = {
}
with open('data.txt','r',encoding='utf8') as f:
words = f.read()
print(type(words))
word1 = jieba.lcut(words,True)
for word in word1:
if len(word) == 2:
dk[word] = dk.get(word,0) + 1
dp = list(dk.items())
dp.sort(key= lambda x:int(x[1]), reverse = True)
for i in range(10):
print(dp[i][0],dp[i][1],end='\n')
<class 'str'>
大学 21
设计 20
美国 16
清华 15
学生 14
教授 12
课程 11
一个 10
国大 8
计算 8
import jieba
dk = {
}
with open('data.txt','r',encoding='utf8') as f:
sl = f.readlines()
print(type(sl))
for s in sl:
k=jieba.lcut(s, cut_all = True)
for wo in k:
if len(wo)==2:
dk[wo





 本文探讨了jieba库的lcut()函数在精确模式(精确分词)与全模式(所有可能词组)的区别,以及如何使用set去重技术。实例展示了字符串分词、词频统计和去重操作,重点关注了核心技术和应用场景。
本文探讨了jieba库的lcut()函数在精确模式(精确分词)与全模式(所有可能词组)的区别,以及如何使用set去重技术。实例展示了字符串分词、词频统计和去重操作,重点关注了核心技术和应用场景。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2527
2527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









