



 本文介绍了一种基于线性表和二叉排序树实现的低频词过滤系统,该系统能够处理英文文章,统计单词频率并过滤出现次数少于五次的单词。通过对比两种数据结构的效率,展示了不同场景下的适用性和性能表现。
本文介绍了一种基于线性表和二叉排序树实现的低频词过滤系统,该系统能够处理英文文章,统计单词频率并过滤出现次数少于五次的单词。通过对比两种数据结构的效率,展示了不同场景下的适用性和性能表现。
基于线性表和二叉排序树的低频词过滤系统
实验内容
- 对于一篇给定的英文文章,分别利用线性表和二叉排序树来实现单词频率的统计,实现低频词的过滤,并比较两种方法的效率。具体要求如下:
- 读取英文文章文件(Infile.txt),识别其中的单词。
- 分别利用线性表和二叉排序树构建单词的存储结构。当识别出一个单词后,若线性表或者二叉排序树中没有该单词,则在适当的位置上添加该单词;若该单词已经被识别,则增加其出现的频率。
- 统计结束后,删除出现频率低于五次的单词,并显示该单词和其出现频率。
- 其余单词及其出现频率按照从高到低的次序输出到文件中(Outfile.txt),同时输出用两种方法完成该工作所用的时间。
- 计算查找表的ASL值,分析比较两种方法的效率。
各个数据结构的定义
创建链表的结点
struct Node
{
//单词的名字
string wordName;
//单词出现的频率
int count = 1;
Node* next=NULL;
};
创建链表
class List
{
public:
//默认构造函数
List();
//带参构造函数
List(string* p, int n);
//列表的长度
int GetLen();
//得到pos位置的单词
string GetData(int pos);
//移动节点到pos位置
Node* MoveTo(int pos);
//在pos位置插入节点
void Insert(string data, int pos);
//输出列表信息
void Cout();
//在列表中查找单词,返回单词的下标
int Search(string data);
//删除pos位置节点
void Delete(int pos);
//在列表末尾插入节点
void Insert(string data);
//列表转数组
Node* ListToArray(int& arrayLength);
//插入节点
void Insert(Node* node);
private:
Node* first;
};
创建链表过滤单词类
class ListFiltrate
{
public:
//单词过滤
void Filtrate(string article);
//void Print();
//列表转数组
Node* ListToArray(int& arrayLength);
//统计输出所有单词
void CountAllWord(string article);
void ASL();//计算ASL
private:
List words;
//把文章拆分为各个单词,进行统计出现频率
void GetWord(string article);
//对得到的单词进行处理
void DeleteLowFrequencyWord();
//删除出现频率小于5的单词
string WordChange(string word);
};
创建查找二叉树结点类
struct BiSortNode
{
//单词的名字
string wordName;
//单词出现的频率
int count = 1;
BiSortNode* lChild=NULL;
BiSortNode* rChild=NULL;
};
创建查找二叉树
class BiSortTree
{
public:
BiSortTree();//构造函数
BiSortNode* Search(BiSortNode* root, string key);//在树中递归查找key
void Insert(string word);//在树中插入一个节点
void Delete(BiSortNode* node);//删除一个节点
BiSortNode* GetRoot();//得到树的根节点
void InorderPrint(BiSortNode* root);//中序遍历输入树
Node* TreeToArray(int& length);//查找二叉树转数组
int* GetEveryLevelNodeNumber();//返回树每一层不为Null的结点个数
int* GetEveryLevelNodeNullNumber();//返回树每一层为Null的结点个数
int GetTreeHeight();//返回树的高度
private:
BiSortNode* root;//根节点
BiSortNode* Insert(BiSortNode* root, BiSortNode* node);//递归插入节点
void NextReplace(BiSortNode* node);//删除时遇到节点有左右子树时,用直接后继代替该节点
BiSortNode* FindParentNode(BiSortNode*root, BiSortNode* node);//寻找节点的父节点
void TreeToList(BiSortNode* root);//树结构转列表
List list;
void CountEveryLevelNode(BiSortNode* root, int depth,int& count);//递归计算树每一层不为Null的结点个数
void CountEveryLevelNullNode(BiSortNode* root, int depth, int& count);//递归计算树每一层为Null的结点个数
int TreeHeight(BiSortNode* root);//递归计算树的高度
int* everyLevelNodeNumber;//树中每一层不为Null的结点个数
int* everyLevelNullNodeNumber;//树中每一层为Null的结点个数
};
创建查找二叉树过滤单词类
class BiSortTreeFiltrate
{
public:
//单词过滤
void Filtrate(string article);
//树结构转数组
Node* TreeToArray(int& length);
//统计输出所有单词
void CountAllWord(string article);
void ASL();//计算ASL
private:
BiSortTree words;
//把文章拆分为各个单词,进行统计出现频率
void GetWord(string article);
//对得到的单词进行处理
string WordChange(string word);
//删除出现频率小于5的单词
void DeleteLowFrequencyWord(BiSortNode* root);
};
各项功能具体实现代码
默认构造函数
List::List()
{
//默认构造函数
this->first = new Node[1];
this->first->next = NULL;
}
带参构造函数
List::List(string* p, int n)
{
//带参构造函数
this->first = new Node[1];
this->first->next = NULL;
for (int i = 0; i < n; i++)
{
this->Insert(p[i], i + 1);
}
}
列表的长度
int List::GetLen()
{
//列表的长度
Node* p = this->first->next;
int Len = 0;
while (p != NULL)
{
Len++;
p = p->next;
}
return Len;
}
得到pos位置的单词
string List::GetData(int pos)
{
//得到pos位置的单词
Node* p = this->first;
for (int i = 0; i < pos; i++)
{
p = p->next;
}
return p->wordName;
}
移动节点到pos位置
Node* List::MoveTo(int pos)
{
//移动节点到pos位置
Node* p = this->first;
for (int i = 0; i < pos; i++)
{
p = p->next;
}
return p;
}
在pos位置插入节点
void List::Insert(string data, int pos)
{
//在pos位置插入节点
Node* p = new Node;
p->wordName = data;
Node* q = MoveTo(pos - 1);
p->next = q->next;
q->next = p;
}
输出列表信息
void List::Cout()
{
//输出列表信息
for (Node* p = this->first->next; p != NULL; p = p->next)
{
cout << p->wordName << ":" << p->count << endl;
}
}
在列表中查找单词,返回单词的下标
int List::Search(string data)
{
//在列表中查找单词,返回单词的下标
int pos = 0;
for (Node* p = this->first->next; p != NULL; p = p->next)
{
pos++;
if (p->wordName==data)
{
return pos;
}
}
return -1;
}
删除pos位置节点
void List::Delete(int pos)
{
//删除pos位置节点
Node* p = MoveTo(pos - 1);
Node* q = p->next;
p->next = q->next;
delete q;
}
在列表末尾
void List::Insert(string data)
{
//在列表末尾插入节点
Node* p = new Node;
p->wordName = data;
p->next = NULL;
Node* q = MoveTo(this->GetLen());
q->next = p;
}
列表转数组
Node* List::ListToArray(int& arrayLength)
{
//列表转数组
int length = this->GetLen();
Node* array = new Node[length];
for (int i = 1; i < length+1; i++)
{
array[i-1].wordName = this->MoveTo(i)->wordName;
array[i-1].count =this->MoveTo(i)->count;
/*cout << array[i-1].wordName << " " << array[i].count<<endl;*/
}
arrayLength = length;
return array;
}
插入节点
void List::Insert(Node* node)
{
//插入节点
Node* q = MoveTo(this->GetLen());
q->next = node;
}
列表单词过滤
void ListFiltrate::Filtrate(string article)
{
//单词过滤
//把文章拆分为各个单词,进行统计出现频率
this->GetWord(article);
//删除出现频率小于5的单词
this->DeleteLowFrequencyWord();
}
列表转数组
Node* ListFiltrate::ListToArray(int& arrayLength)
{
//列表转数组
return this->words.ListToArray(arrayLength);
}
统计输出所有单词
void ListFiltrate::CountAllWord(string article)
{
//统计输出所有单词
this->GetWord(article);
this->words.Cout();
}
把文章拆分为各个单词,进行统计出现频率
void ListFiltrate::GetWord(string article)
{
//把文章拆分为各个单词,进行统计出现频率
string temp = article;
while (temp.size()>0)
{
int startWordIndex = 0;//查找单词开始字母的下标
while ((temp[startWordIndex] < 'a' || temp[startWordIndex]>'z') && (temp[startWordIndex] < 'A' || temp[startWordIndex]>'Z'))
{
startWordIndex++;
if (startWordIndex > temp.size())
{
return;
}
}
int endWordIndex = startWordIndex;//查找单词结束字母的下标
while ((temp[endWordIndex] >= 'a' && temp[endWordIndex] <= 'z') || (temp[endWordIndex] >= 'A'&& temp[endWordIndex] <= 'Z')||temp[endWordIndex]=='-'||temp[endWordIndex]=='\'')
{
endWordIndex++;
}
//得到单词
string word = this->WordChange(temp.substr(startWordIndex, endWordIndex - startWordIndex));
//在树中查找单词,统计频率
if (this->words.Search(word) != -1)
{
this->words.MoveTo(this->words.Search(word))->count++;
}
else
{
this->words.Insert(word);
}
//文章删除该单词
temp = temp.substr(endWordIndex );
}
}
删除出现频率小于5的单词
void ListFiltrate::DeleteLowFrequencyWord()
{
//删除出现频率小于5的单词
int length = this->words.GetLen() + 1;
for (int i = 1; i < length; i++)
{
if (this->words.MoveTo(i)->count < 5)
{
cout << this->words.MoveTo(i)->wordName << ":" << this->words.MoveTo(i)->count << endl;
this->words.Delete(i);
i--;
length--;
}
}
}
对得到的单词进行处理
string ListFiltrate::WordChange(string word)
{
//对得到的单词进行处理
string result=word;
//大写换小写
for (int i = 0; i < word.size(); i++)
{
//大写换小写
if (result[i] >='A' && result[i] <= 'Z')
{
result[i] = result[i] + 32;
}
//格助词处理
if (result[i] == '\'')
{
result = result.substr(0, i );
break;
}
}
return result;
}
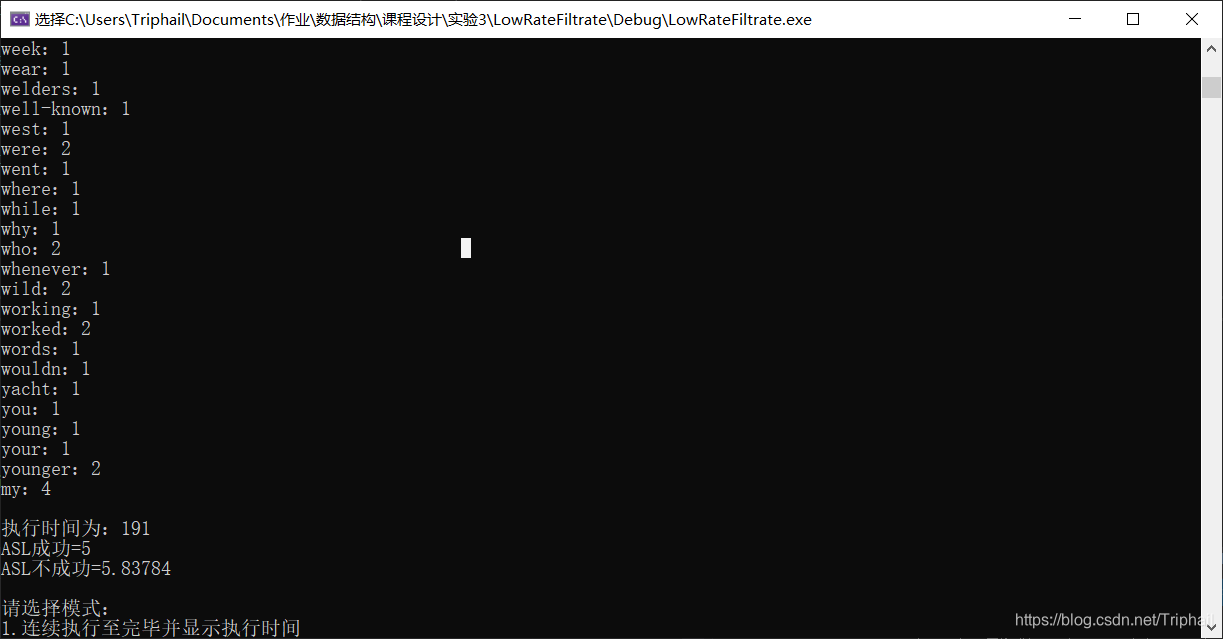
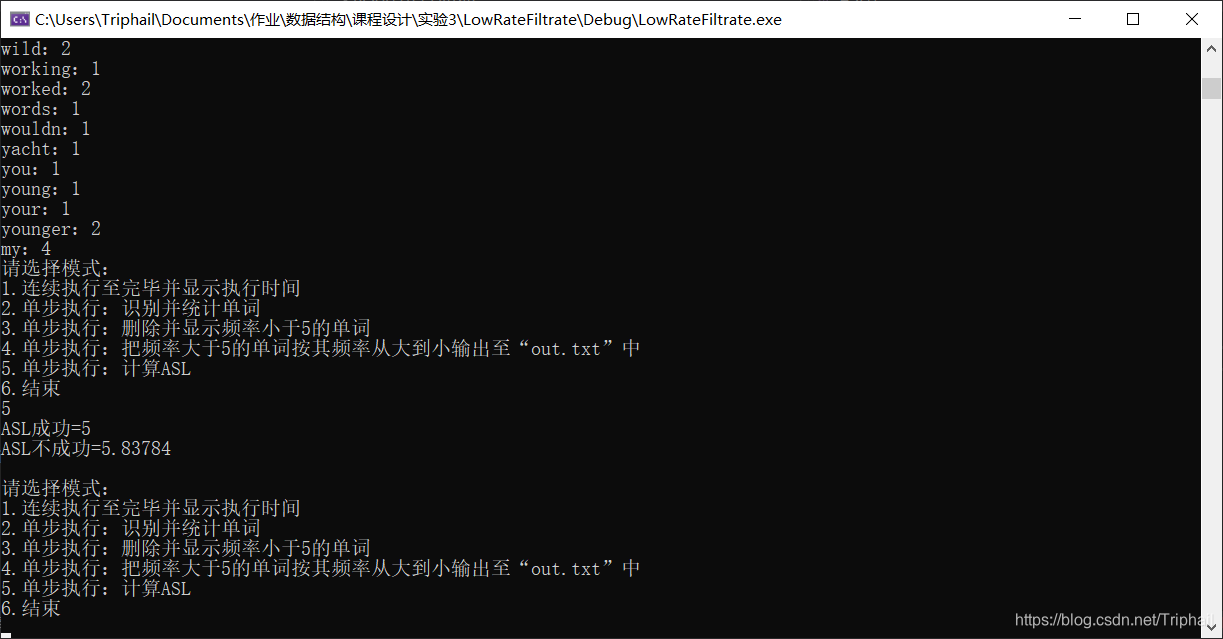
计算列表查找ASL
void ListFiltrate::ASL()
{
cout << "ASL成功=" << (this->words.GetLen() + 1) / 2;
cout << "ASL失败=" << this->words.GetLen();
}
构造函数
BiSortTree::BiSortTree()
{
//构造函数
this->root = NULL;
this->everyLevelNodeNumber = NULL;
this->everyLevelNullNodeNumber = NULL;
}
在树中递归查找key
BiSortNode* BiSortTree::Search(BiSortNode* root, string key)
{
//在树中递归查找key
if (root == NULL)
{
return NULL;
}
if (root->wordName == key)
{
//查找成功
return root;
}
if (root->wordName > key)
{
//查找左子树
return this->Search(root->lChild, key);
}
else
{
//查找右子树
return this->Search(root->rChild, key);
}
}
在树中插入一个节点
void BiSortTree::Insert(string word)
{
//在树中插入一个节点
BiSortNode* node = new BiSortNode[1];
node->wordName = word;
this->root = this->Insert(this->root, node);
}
递归插入节点
BiSortNode* BiSortTree::Insert(BiSortNode* root, BiSortNode* node)
{
//递归插入节点
if (root == NULL)
{
//当数为空,插入节点为根节点
return node;
}
if (node->wordName < root->wordName)
{
root->lChild = this->Insert(root->lChild, node);//插入左子树
}
else
{
root->rChild = this->Insert(root->rChild, node);//插入右子树
}
return root;
}
删除一个节点
void BiSortTree::Delete(BiSortNode* node)
{
//删除一个节点
if (node->rChild == NULL && node->lChild == NULL)
{
//当该节点为叶子节点时
BiSortNode* temp = this->FindParentNode(root, node);
if (temp->rChild == node)
{
temp->rChild = NULL;
}
else
{
temp->lChild = NULL;
}
delete[] node;
}
else if (node->rChild == NULL && node->lChild != NULL)
{
//右子树为空,左子树不为空
//子节点的值赋给该节点
BiSortNode* temp = node->lChild;
node->wordName = temp->wordName;
node->count = temp->count;
node->lChild = temp->lChild;
node->rChild = temp->rChild;
//删除子节点
delete[] temp;
}
else if (node->lChild == NULL && node->rChild != NULL)
{
//左子树为空,右子树不为空
//子节点的值赋给该节点
BiSortNode* temp = node->rChild;
node->wordName = temp->wordName;
node->count = temp->count;
node->lChild = temp->lChild;
node->rChild = temp->rChild;
//删除子节点
delete[] temp;
}
else
{
//左右子树皆不为空
//直接后继代替该节点
this->NextReplace(node);
}
}
得到树的根节点
BiSortNode* BiSortTree::GetRoot()
{
//得到树的根节点
return this->root;
}
中序遍历输入树
void BiSortTree::InorderPrint(BiSortNode* root)
{
//中序遍历输入树
if (root == NULL)
{
return;
}
this->InorderPrint(root->lChild);
cout << root->wordName << ":" << root->count << endl;
this->InorderPrint(root->rChild);
}
查找二叉树转数组
Node* BiSortTree::TreeToArray(int& length)
{
//查找二叉树转数组
//树结构转列表
this->TreeToList(this->root);
//列表转数组
return this->list.ListToArray(length);
}
树结构转列表
void BiSortTree::TreeToList(BiSortNode* root)
{
//树结构转列表
if (root == NULL)
{
return;
}
//this->InorderPrint(root->lChild);
this->TreeToList(root->lChild);
Node* node = new Node[1];
node->wordName = root->wordName;
node->count = root->count;
this->list.Insert(node);
this->TreeToList(root->rChild);
}
直接后继取代删除节点
void BiSortTree::NextReplace(BiSortNode* node)
{
//直接后继取代删除节点
BiSortNode* temp = node;//后继节点的父节点
BiSortNode* subNode = node->rChild;//直接后继节点
while (subNode->lChild != NULL)
{
temp = subNode;
subNode = subNode->lChild;
}
node->wordName = subNode->wordName;
node->count = subNode->count;
if (node == temp)
{
//被删除节点右孩子节点的左子树为空
temp->rChild = subNode->rChild;
}
else
{
//被删节点右孩子的左子树为空
temp->lChild = subNode->rChild;
}
delete[] subNode;
subNode = NULL;
}
寻找节点的父节点
BiSortNode* BiSortTree::FindParentNode(BiSortNode* root, BiSortNode* node)
{
//寻找节点的父节点
if (root == NULL)
{
return NULL;
}
if (root->lChild == node || root->rChild == node)
{
return root;
}
if (root->wordName < node->wordName)
{
root = this->FindParentNode(root->rChild, node);
}
else
{
root = this->FindParentNode(root->lChild, node);
}
}
递归计算树每一层不为Null的结点个数
void BiSortTree::CountEveryLevelNode(BiSortNode* root, int depth,int& count)
{
//递归计算树每一层不为Null的结点个数
if (root == NULL || depth == 0)
{
return;
}
if (depth == 1)
{
//当层的深度为1时,说明已经递归到指定深度
count++;
}
this->CountEveryLevelNode(root->lChild, depth - 1, count );
this->CountEveryLevelNode(root->rChild, depth - 1, count);
}
递归计算树每一层为Null的结点个数
void BiSortTree::CountEveryLevelNullNode(BiSortNode* root, int depth, int& count)
{
//递归计算树每一层为Null的结点个数
if (depth == 1 &&root==NULL)
{
//当层的深度为1时,说明已经递归到指定深度
count++;
}
if (root == NULL || depth == 0)
{
return;
}
this->CountEveryLevelNullNode(root->lChild, depth - 1, count);
this->CountEveryLevelNullNode(root->rChild, depth - 1, count);
}
返回树每一层不为Null的结点个数
int* BiSortTree::GetEveryLevelNodeNumber()
{
//返回树每一层不为Null的结点个数
//根据树的高度创建数组
int height = this->TreeHeight(this->root)+1;
this->everyLevelNodeNumber = new int[height];
for (int i = 1; i < height; i++)
{
int count = 0;
this->CountEveryLevelNode(this->root, i, count);
//计算depth层中不为Null的结点个数
this->everyLevelNodeNumber[i] =count;
}
return this->everyLevelNodeNumber;
}
返回树每一层为Null的结点个数
int* BiSortTree::GetEveryLevelNodeNullNumber()
{
//返回树每一层为Null的结点个数
//根据树的高度创建数组
int height = this->TreeHeight(this->root) + 2;
this->everyLevelNullNodeNumber= new int[height];
for (int i = 1; i < height; i++)
{
int count = 0;
this->CountEveryLevelNullNode(this->root, i, count);
//计算depth层中为Null的结点个数
this->everyLevelNullNodeNumber[i] = count;
}
return everyLevelNullNodeNumber;
}
递归计算树的高度
int BiSortTree::TreeHeight(BiSortNode* root)
{
//递归计算树的高度
if (root == NULL)
{
//当根结点为空时返回
return 0;
}
//递归计算左子树的高度
int leftLength = this->TreeHeight(root->lChild);
//递归计算右子树的高度
int rightLength =this->TreeHeight(root->rChild);
//返回左子树和右子树中的最大者
return max(leftLength, rightLength) + 1;
}
返回树的高度
int BiSortTree::GetTreeHeight()
{
//返回树的高度
return this->TreeHeight(this->root);
}
查找二叉树单词过滤
void BiSortTreeFiltrate::Filtrate(string article)
{
//单词过滤
//把文章拆分为各个单词,进行统计出现频率
this->GetWord(article);
//删除出现频率小于5的单词
this->DeleteLowFrequencyWord(this->words.GetRoot());
}
树结构转数组
Node* BiSortTreeFiltrate::TreeToArray(int& length)
{
//树结构转数组
return this->words.TreeToArray(length);
}
统计输出所有单词
void BiSortTreeFiltrate::CountAllWord(string article)
{
//统计输出所有单词
this->GetWord(article);
this->words.InorderPrint(this->words.GetRoot());
}
把文章拆分为各个单词,进行统计出现频率
void BiSortTreeFiltrate::GetWord(string article)
{
//把文章拆分为各个单词,进行统计出现频率
string temp = article;
while (temp.size() > 0)
{
int startWordIndex = 0;//查找单词开始字母的下标
while ((temp[startWordIndex] < 'a' || temp[startWordIndex]>'z') && (temp[startWordIndex] < 'A' || temp[startWordIndex]>'Z'))
{
startWordIndex++;
if (startWordIndex > temp.size())
{
return;
}
}
int endWordIndex = startWordIndex;//查找单词结束字母的下标
while ((temp[endWordIndex] >= 'a' && temp[endWordIndex] <= 'z') || (temp[endWordIndex] >= 'A' && temp[endWordIndex] <= 'Z') || temp[endWordIndex] == '-' || temp[endWordIndex] == '\'')
{
endWordIndex++;
}
//得到单词
string word = this->WordChange(temp.substr(startWordIndex, endWordIndex - startWordIndex));
//在树中查找单词,统计频率
BiSortNode* tempNode = this->words.Search(this->words.GetRoot(), word);
if (tempNode != NULL)
{
tempNode->count++;
}
else
{
this->words.Insert(word);
}
//文章删除该单词
temp = temp.substr(endWordIndex);
}
}
删除出现频率小于5的单词
void BiSortTreeFiltrate::DeleteLowFrequencyWord(BiSortNode* root)
{
//删除出现频率小于5的单词
if (root == NULL)
{
return;
}
this->DeleteLowFrequencyWord(root->lChild);
this->DeleteLowFrequencyWord(root->rChild);
if (root->count < 5)
{
cout << root->wordName << ":" << root->count << endl;
this->words.Delete(root);
}
}
主函数代码
使用文件流读取文章
string ReadArticle()
{
//读取文章
ifstream file;
file.open("Infile.txt");
stringstream buffer;
buffer << file.rdbuf();
string article = buffer.str();
file.close();
return article;
}
显示执行时间
void PrintWorkTime(clock_t start, clock_t end)
{
//显示执行时间
cout << "执行时间为:" << (double)(end - start);
}
输入的模式选择
int ModelChoose()
{
int chooseModel;
cout << "请选择模式:" << endl;
cout << "1.连续执行至完毕并显示执行时间" << endl;
cout << "2.单步执行:识别并统计单词" << endl;
cout << "3.单步执行:删除并显示频率小于5的单词" << endl;
cout << "4.单步执行:把频率大于5的单词按其频率从大到小输出至“out.txt”中" << endl;
cout << "5.单步执行:计算ASL" << endl;
cin >> chooseModel;
return chooseModel;
}
列表模式
void ListModel(int chooseModel, string article)
{
//输入模式选择
chooseModel = ModelChoose();
ListFiltrate list;
switch (chooseModel)
{
case 1:
{
//连续执行至全部完成,并显示执行时间
//记录执行开始的时间
clock_t start = clock();
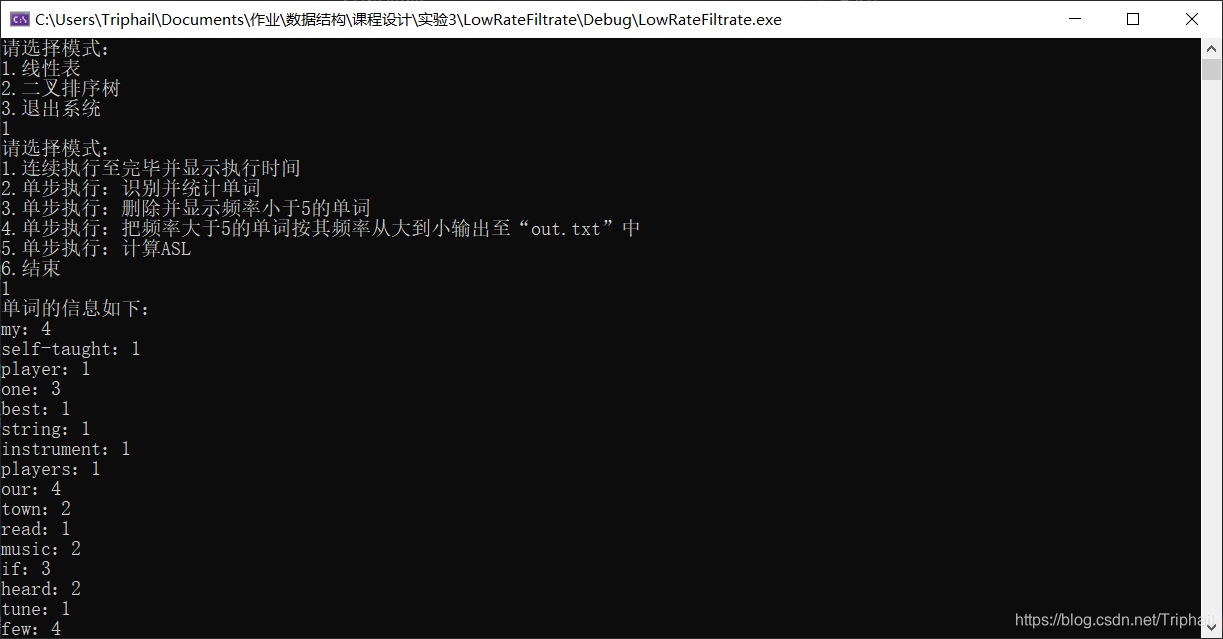
cout << "单词的信息如下:" << endl;
//低频词语删除
list.Filtrate(article);
int length = 0;
//把高频词汇写入txt中
WriteWords(list.ListToArray(length), length);
//记录执行结束的时间
clock_t end = clock();
cout << endl;
//打印执行时间
PrintWorkTime(start, end);
list.ASL();
}
case 2:
{
//识别并统计单词
list.CountAllWord(article);
break;
}
case 3:
{
//删除并显示频率小于5的单词
list.Filtrate(article);
break;
}
case 4:
{
//把频率大于5的单词按其频率从大到小输出至“out.txt”中
int length = 0;
WriteWords(list.ListToArray(length), length);
break;
}
case 5:
{
list.Filtrate(article);
list.ASL();
break;
}
default:
break;
}
}
查找二叉树模式
void BiSortTreeModel(int chooseModel, string article)
{
//输入模式选择
chooseModel = ModelChoose();
BiSortTreeFiltrate tree;
switch (chooseModel)
{
case 1:
{
//连续执行至全部完成,并显示执行时间
//记录执行开始的时间
clock_t start = clock();
cout << "单词的信息如下:" << endl;
//低频词语删除
tree.Filtrate(article);
//把高频词汇写入txt中
int length = 0;
WriteWords(tree.TreeToArray(length), length);
//记录执行结束的时间
clock_t end = clock();
cout << endl;
//打印执行时间
PrintWorkTime(start, end);
tree.ASL();
}
case 2:
{
//识别并统计单词
tree.CountAllWord(article);
break;
}
case 3:
{
//删除并显示频率小于5的单词
tree.Filtrate(article);
break;
}
case 4:
{
//把频率大于5的单词按其频率从大到小输出至“out.txt”中
int length = 0;
WriteWords(tree.TreeToArray(length), length);
break;
}
case 5:
{
//计算ASL
tree.Filtrate(article);
tree.ASL();
break;
}
default:
break;
}
}
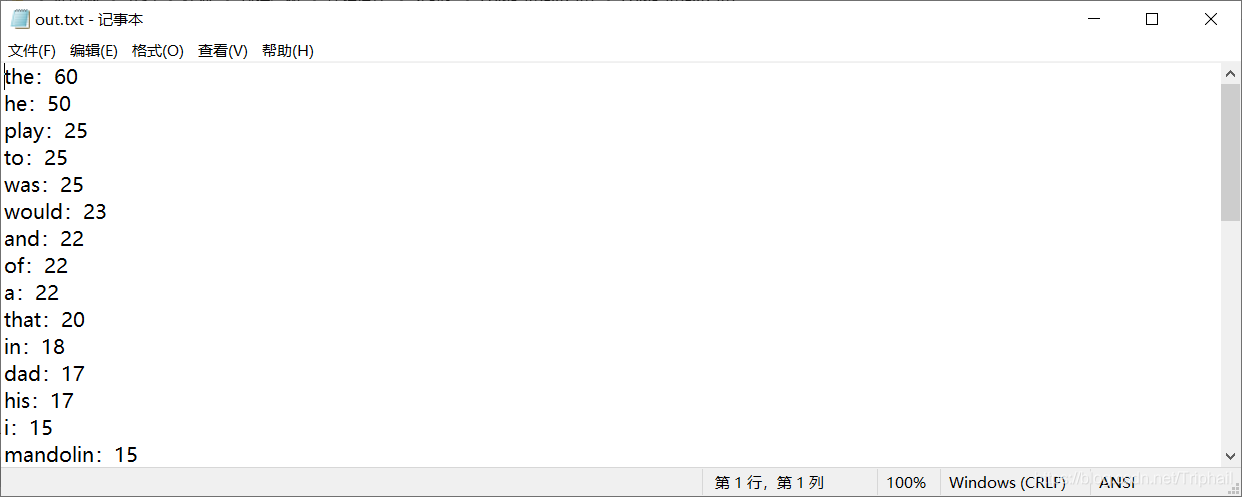
把单词写入txt中
void WriteWords(Node* array, int& length)
{
//把单词写入txt中
//单词按照频率从高到底进行排序
Sort(array, length);
//写入单词
OutputWords(length, array);
}
写入单词
void OutputWords(int length, Node* array)
{
//把单词写入txt中
ofstream outFile("out.txt");
for (int i = 0; i < length; i++)
{
//cout << b[i]<<" ";
outFile << array[i].wordName << ":" << array[i].count << endl;
}
}
单词按照从大到小进行排序
void Sort(Node* array, int length)
{
//单词按照从大到小进行排序
for (int i = 0; i < length; i++)
{
int temp = i;
for (int j = i + 1; j < length; j++)
{
if (array[temp].count < array[j].count)
{
temp = j;
}
}
if (temp != i)
{
Node tempNode;
tempNode.wordName = array[temp].wordName;
tempNode.count = array[temp].count;
array[temp].wordName = array[i].wordName;
array[temp].count = array[i].count;
array[i].wordName = tempNode.wordName;
array[i].count = tempNode.count;
}
}
}
实验结果
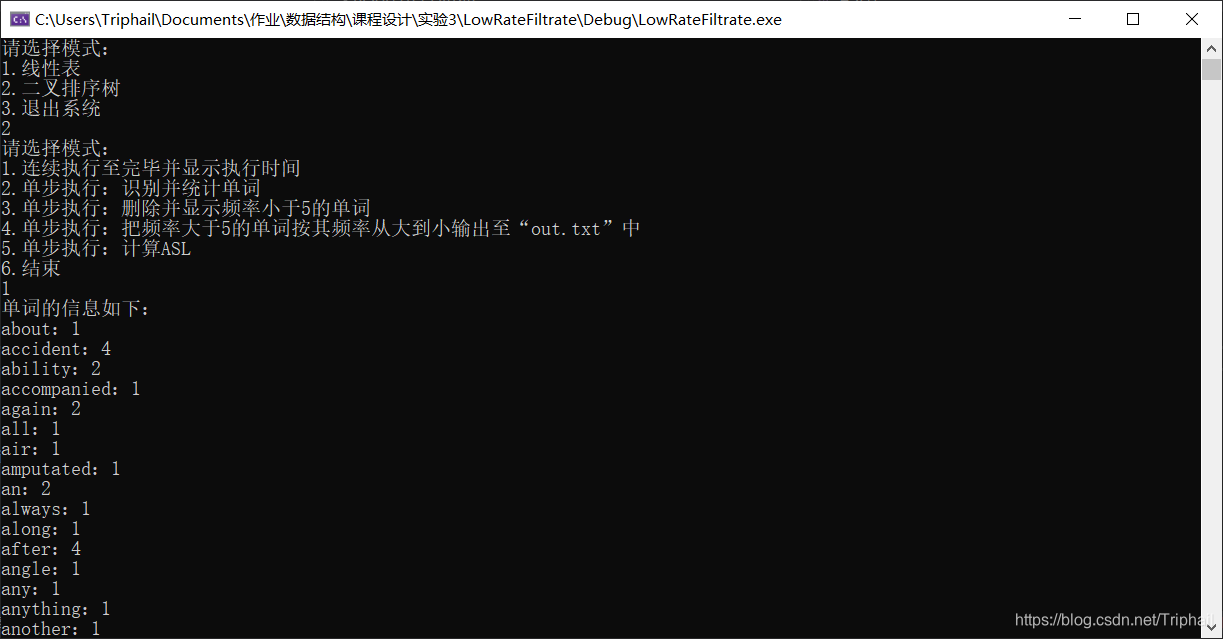
主菜单
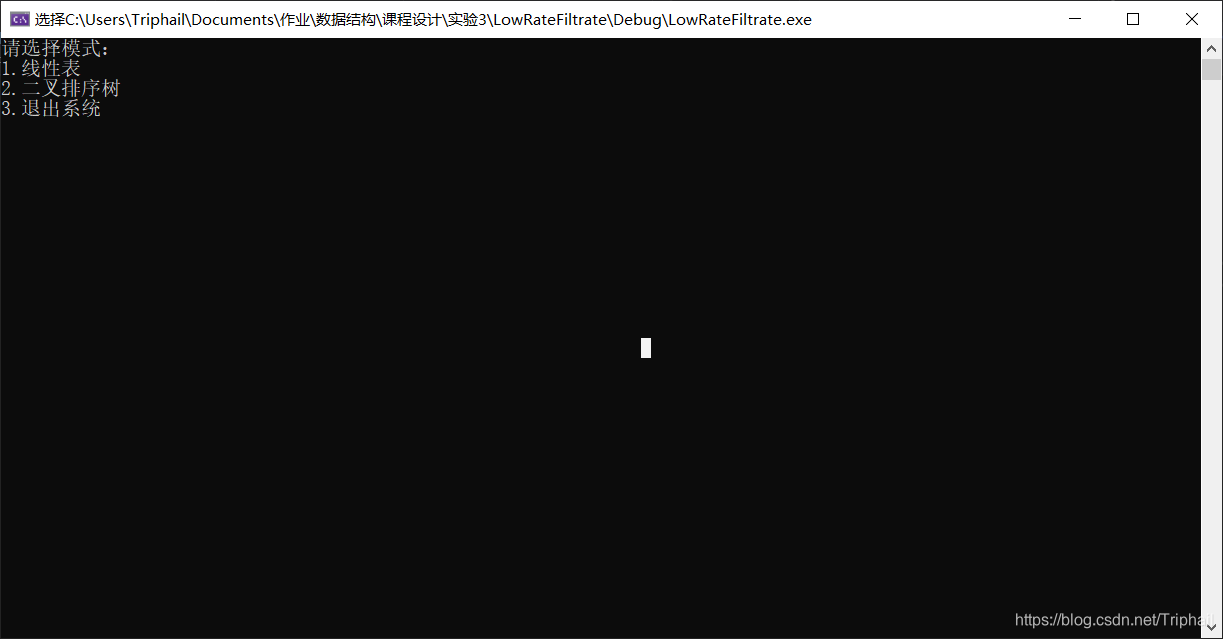
线性表模式
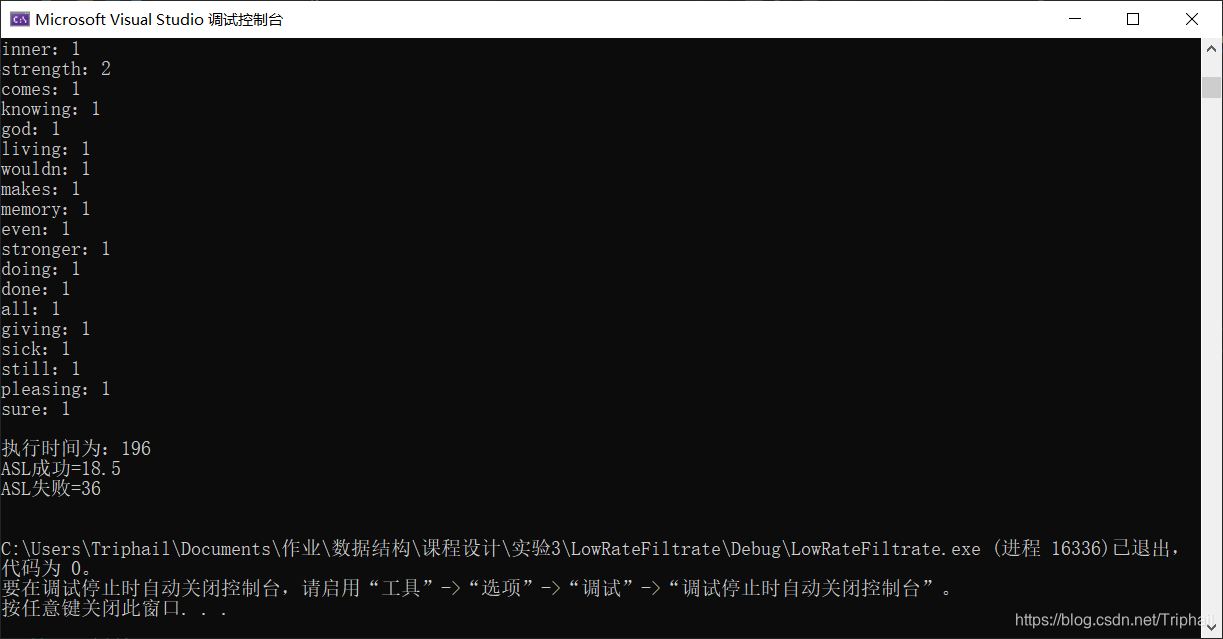
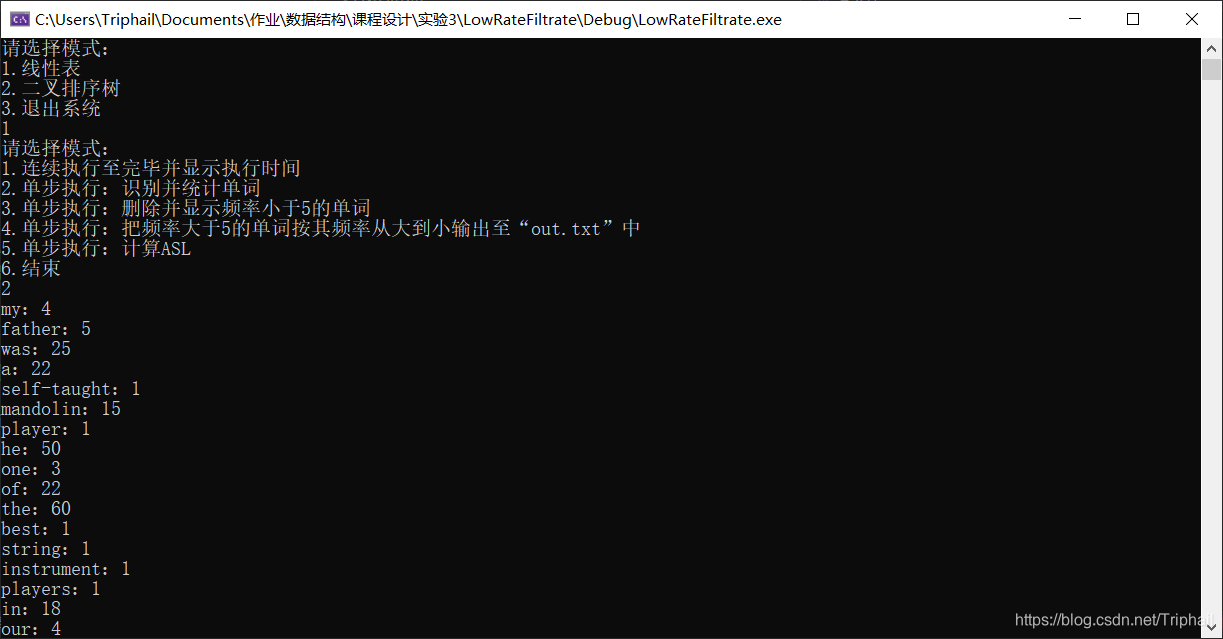
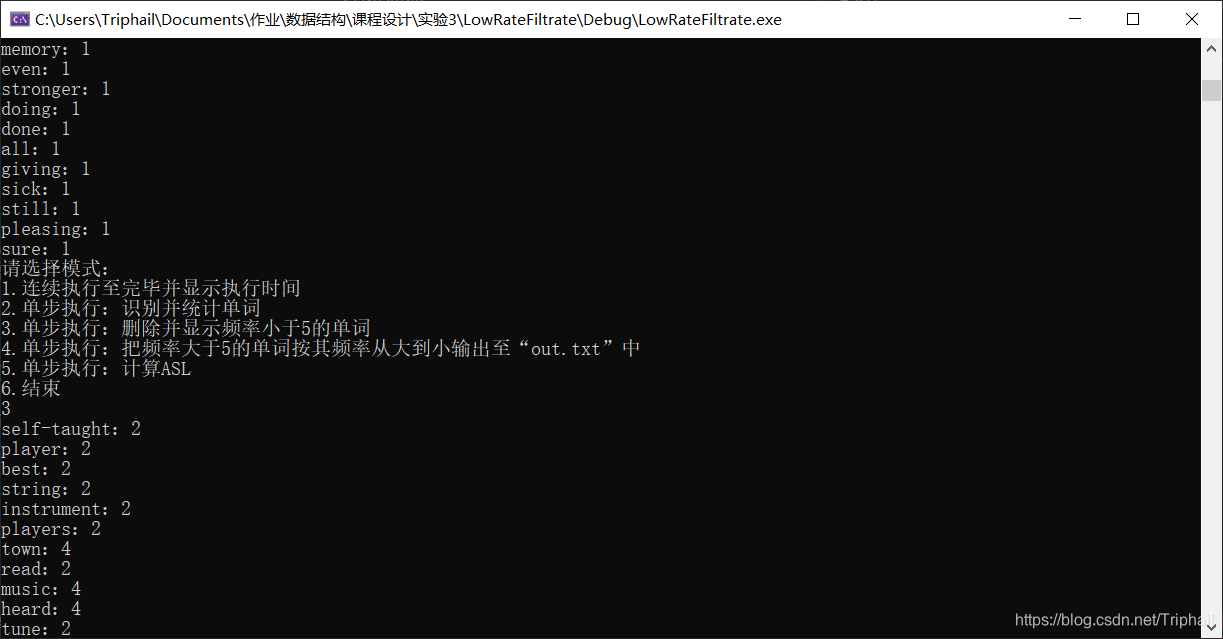
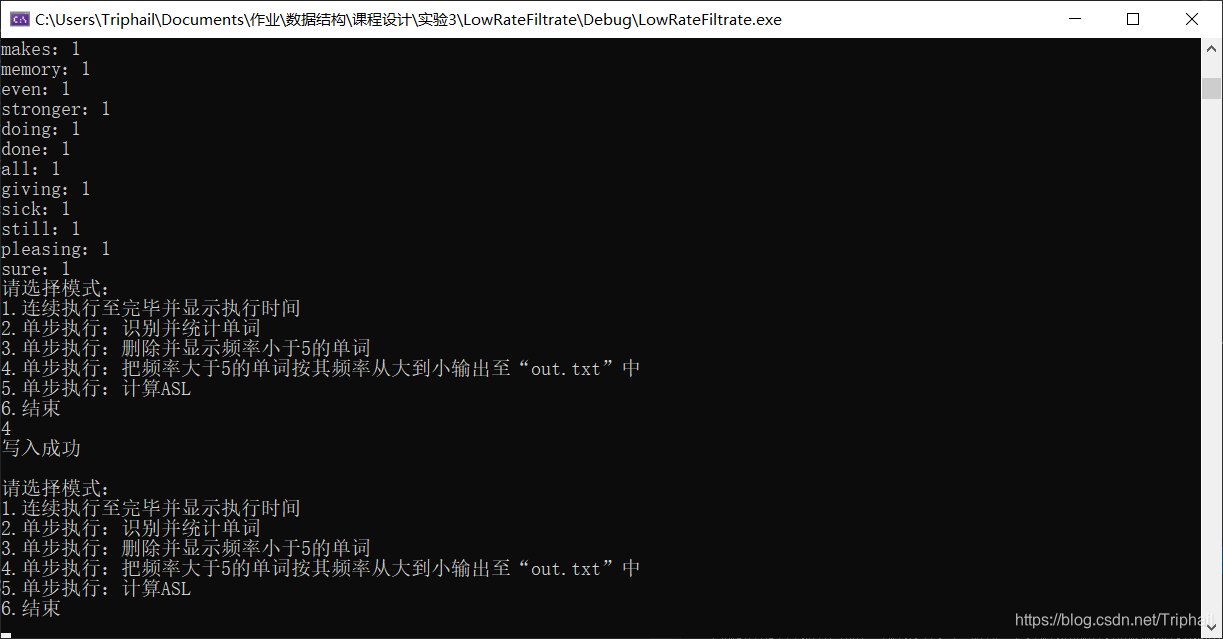

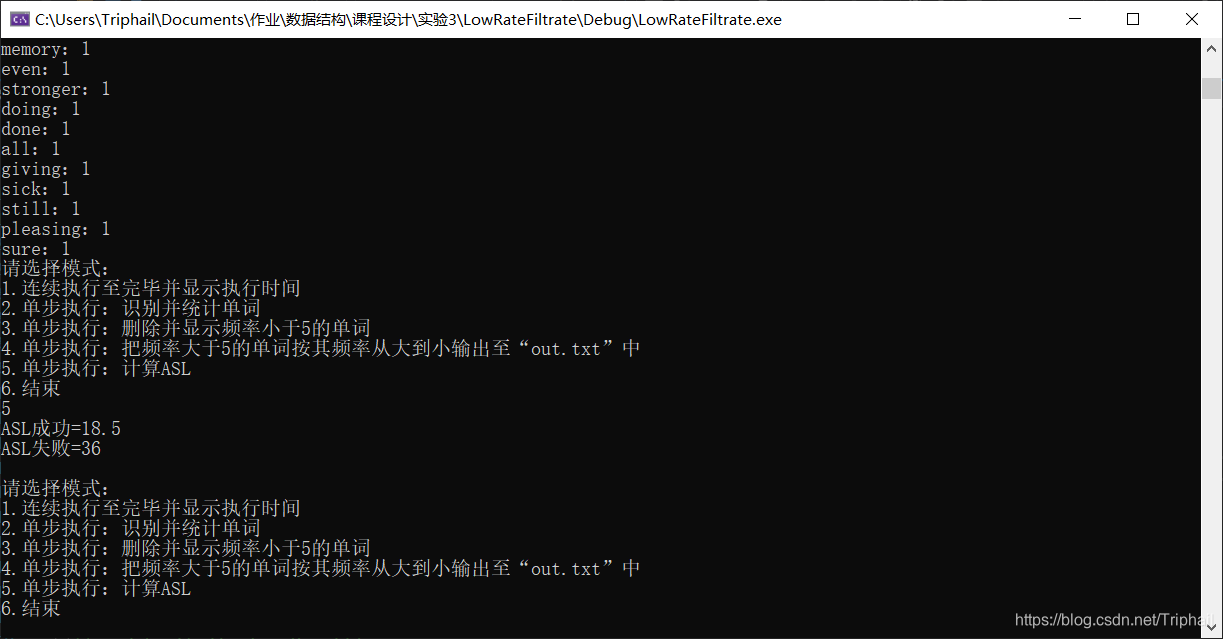
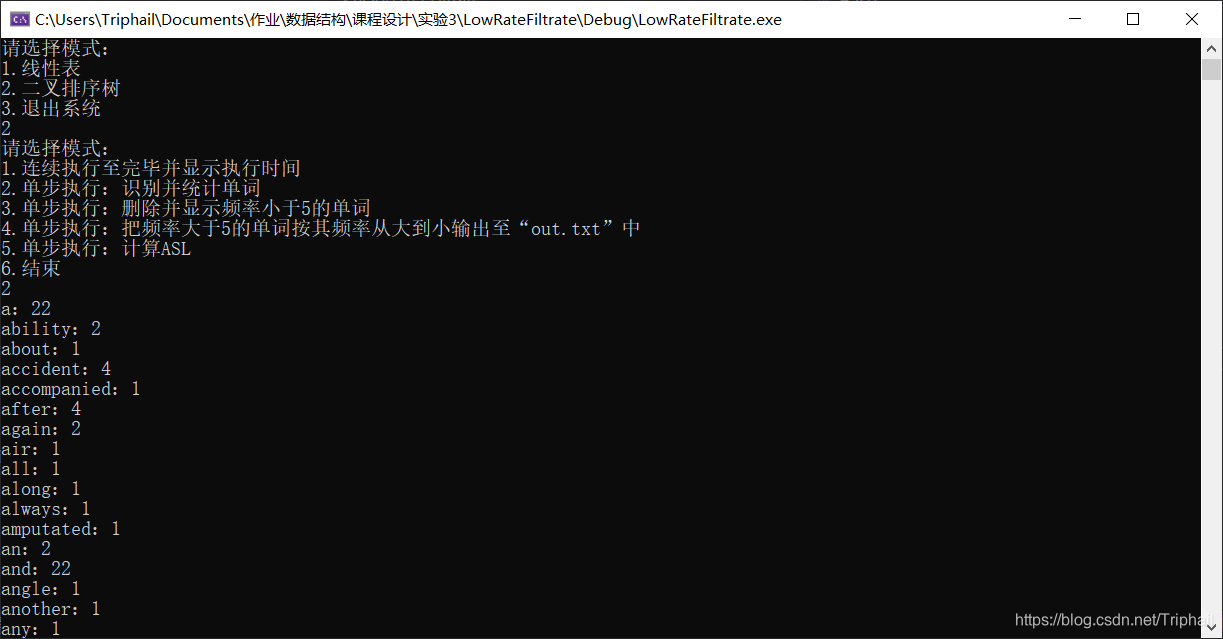
查找二叉树模式

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









