






 本文深入讲解前端核心概念,包括事件循环、作用域链、闭包、原型和原型链、继承方式、异步处理、跨域解决方案、Promise实现、事件委托等,帮助开发者全面掌握前端编程技巧。
本文深入讲解前端核心概念,包括事件循环、作用域链、闭包、原型和原型链、继承方式、异步处理、跨域解决方案、Promise实现、事件委托等,帮助开发者全面掌握前端编程技巧。
-
<div id="s1">s1 <div id="s2">s2</div> </div> <script> s1.addEventListener("click",function(e){ console.log("s1 冒泡事件"); },false); s2.addEventListener("click",function(e){ console.log("s2 冒泡事件"); },false); s1.addEventListener("click",function(e){ console.log("s1 捕获事件"); },true); s2.addEventListener("click",function(e){ console.log("s2 捕获事件"); },true); </script>当我们点击s2的时候,执行结果如下:
s1捕获事件-> s2冒泡事件 -> s2捕获事件 -> s1冒泡事件这里大体分析下执行结果
- 点击s2,click事件从document->html->body->s1->s2(捕获前进)
这里在s1上发现了捕获注册事件,则输出"s1 捕获事件" - 到达s2,已经到达目的节点,s2上注册了冒泡和捕获事件,先注册的冒泡后注册的捕获,则先执行冒泡,输出"s2 冒泡事件"
- 再在s2上执行后注册的事件,即捕获事件,输出"s2 捕获事件"
- 下面进入冒泡阶段,按照s2->s1->body->html->documen(冒泡前进),在s1上发现了冒泡事件,则输出"s1 冒泡事件"
- 点击s2,click事件从document->html->body->s1->s2(捕获前进)
-
事件委托
利用事件冒泡和事件捕获的特点,我们可以使用事件委托减少事件处理函数的绑定数量。
好处: 1. 减少事件注册;2. 新增子对象无需再次绑定事件,对我们动态增加子元素的时候很友好。
用法:利用事件冒泡原理 => 父元素进行事件响应=> 通过e.target可以找到子元素
假设有以下情况:
<html>
<body>
<ul id="s1" style="background: red; padding: 20px;">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
</body>
</html>
<script>
// 分别点击item获取其value
var list = document.getElementById('s1').getElementsByTagName('li');
Array.prototype.forEach.call(list, element => {
element.addEventListener('click', function (e) {
console.log(e.target.innerText)
}, true)
});
</script>
我们可以使用事件代理进行优化
<html>
<body>
<ul id="s1" style="background: red; padding: 20px;">
<li data-index="1">1</li>
<li data-index="2">2</li>
<li data-index="3">3</li>
</ul>
</body>
</html>
<script>
// 分别点击item获取其value
var s1 = document.getElementById('s1');
s1.addEventListener('click', function (e) {
if (e.target.nodeName.toLowerCase() === 'li') {
console.log(e.target.innerText, e.target.dataset.index)
}
}, false)
</script>
对于事件代理来说,在事件捕获或者事件冒泡阶段处理并没有明显的优劣之分,但是由于事件冒泡的事件流模型被所有主流的浏览器兼容,从兼容性角度来说还是建议大家使用事件冒泡模型。
- 节流throttle和防抖debounce
- 节流:规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。
常用场景:监听滚动事件判断滚动是否到底部,若不使用节流,则会触发很多次判断,我们使用节流,每500ms只触发一次判断,极大优化性能。 - 防抖:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。
- 常用场景:输入框监听用户输入,获取用户输入内容调用后台接口。若直接使用input事件,用户还没打完字就多次调用接口,造成服务器压力过大。使用防抖,用户输入后500ms再次触发input事件,则再等500ms,直到500ms内无新输入,发送数据至服务器端。
function debounce (fn, delay = 300) {
var timeout = 0;
return function () {
if (timeout) {
clearTimeout(timeout);
}
timeout = setTimeout(fn.bind(this, ...arguments), delay);
}
}
function throttle (fn, delay = 300) {
var last = 0;
return function () {
var now = +new Date();
if (!last || now >= last + delay) {
fn.apply(this, arguments);
last = now;
}
}
}
throttle优化
function throttle (fn, delay = 300) {
var last = 0;
var timeout = 0
return function () {
clearTimeout(timeout);
var now = +new Date();
if (!last || now >= last + delay) {
fn.apply(this, arguments);
last = now;
} else {
timeout = setTimeout(fn.bind(this, ...arguments), delay); // 确保最后再调用一次函数
}
}
}
-
定义函数时用 var foo = function () {} 和 function foo() 有什么区别?
https://www.zhihu.com/question/19878052
https://www.cnblogs.com/coco1s/p/3959927.html -
延长作用域链(with、try-catch)
https://www.jianshu.com/p/a9e3a605f4ab
面向对象的设计思想是从自然界中来的,因为在自然界中,类(Class)和实例(Instance)的概念是很自然的。Class是一种抽象概念,比如我们定义的Class——Student,是指学生这个概念,而实例(Instance)则是一个个具体的Student,比如,Bart Simpson和Lisa Simpson是两个具体的Student:
所以,面向对象的设计思想是抽象出Class,根据Class创建Instance。
面向对象的抽象程度又比函数要高,因为一个Class既包含数据,又包含操作数据的方法
-
作用域链
作用: 保证对执行环境有权访问的所有变量和函数的有序访问。(标识符解析是沿着作用域链一级一级地搜索标识符的过程) -
闭包
意义:1.从函数外部读取函数内部声明的变量。
2.让被读取的变量的值始终保持在内存中。(由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。)
实现方法:在函数内部再定义一个函数然后return出去!
```
function f1(){
var n=999;
function f2(){
alert(n);
}
return f2;
}
var result=f1();
result(); // 999
```
在上面的代码中,函数f2就被包括在函数f1内部,这时f1内部的所有局部变量,对f2都是可见的。但是反过来就不行,f2内部的局部变量,对f1就是不可见的。这就是Javascript语言特有的"链式作用域"结构(chain scope),子对象会一级一级地向上寻找所有父对象的变量。所以,父对象的所有变量,对子对象都是可见的,反之则不成立。
```
function f1(){
var n=999;
nAdd=function(){n+=1}
function f2(){
alert(n);
}
return f2;
}
var result=f1();
result(); // 999
nAdd();
result(); // 1000
```
在这段代码中,result实际上就是闭包f2函数。它一共运行了两次,第一次的值是999,第二次的值是1000。这证明了,函数f1中的局部变量n一直保存在**内存**中,并没有在f1调用后被自动清除。
为什么会这样呢?原因就在于f1是f2的父函数,而f2被赋给了一个全局变量,这导致f2始终在内存中,而f2的存在依赖于f1,因此f1也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
这段代码中另一个值得注意的地方,就是"nAdd=function(){n+=1}"这一行,首先在nAdd前面没有使用var关键字,因此nAdd是一个全局变量,而不是局部变量。其次,nAdd的值是一个匿名函数(anonymous function),而这个匿名函数本身也是一个闭包,所以nAdd相当于是一个setter,可以在函数外部对函数内部的局部变量进行操作。
-
使用闭包定义私有变量
function ProV () { var name; this.setName = function (value) { name = value; }; this.getName = function () { return name; }; } var p = new ProV(); //定义ProV的实例对象 p.setName("Tom"); console.log(p.name); //undefined 对象p的name是私有变量,不能直接访问。 console.log(p.getName()); //Tom -
setTimeout函数之循环和闭包
https://blog.youkuaiyun.com/huakaiwuxing/article/details/78968642
https://www.jianshu.com/p/e5225ba4a025 -
call、apply和bind的区别
- call和apply是为了改变函数运行时的上下文而存在的,不同的是使用apply时函数参数以数组形式传参,而使用call时函数参数以单独形式传参。注意call和apply方法都会使函数立即执行。
https://github.com/lin-xin/blog/issues/7func.call(this, arg1,arg2,...) func.apply(this, [arg1,arg2,...]) - bind()方法会创建一个新函数,称为绑定函数,传入this可以修改该函数的上下文,原函数的上下文没有改变,多次调用bind()方法是无效的。
bind()本身可以带函数参数,而调用绑定函数时候带的参数则是在 bind 中参数的基础上再往后排。 - 例子
// 代理console.log function log() { console.log.apply(console, arguments) } log(1,2) // 1,2 log(1) // 1
ES6中的箭头函数没有自己的 arguments 对象,不过在大多数情形下,rest参数可以给出一个解决方案:
var a;
const fn = () => Array.prototype.slice.call(arguments);
a = fn(1, 2); // [1, 2]
arguments.callee
好处: 自己调用自己的时候去除函数名的耦合性。
现在已经不推荐使用arguments.callee(),访问 arguments 是个很昂贵的操作,因为它是个很大的对象,每次递归调用时都需要重新创建。影响现代浏览器的性能,还会影响闭包。
-
apply实现bind
ie8不兼容bind,但兼容apply和call
准备知识:关于[ ].slice.call()
简单版=>实现改变this指向以及传参Function.prototype.bind = function(context){ //保存this,也就是调用bind的那个函数 var self = this; var args = [].slice.call(arguments, 1);// arguments没有数组的slice方法,此方法可以把传进来的参数变为数组 // 第二个参数为1,剔除context return function(){ //将第一次的参数与此次传入的参数合并,调用self函数 return self.apply(context,args.concat([].slice.call(arguments))); } } -
JavaScript之this指向
当一个函数作为函数而不是方法来调用的时候,this指向的是全局对象
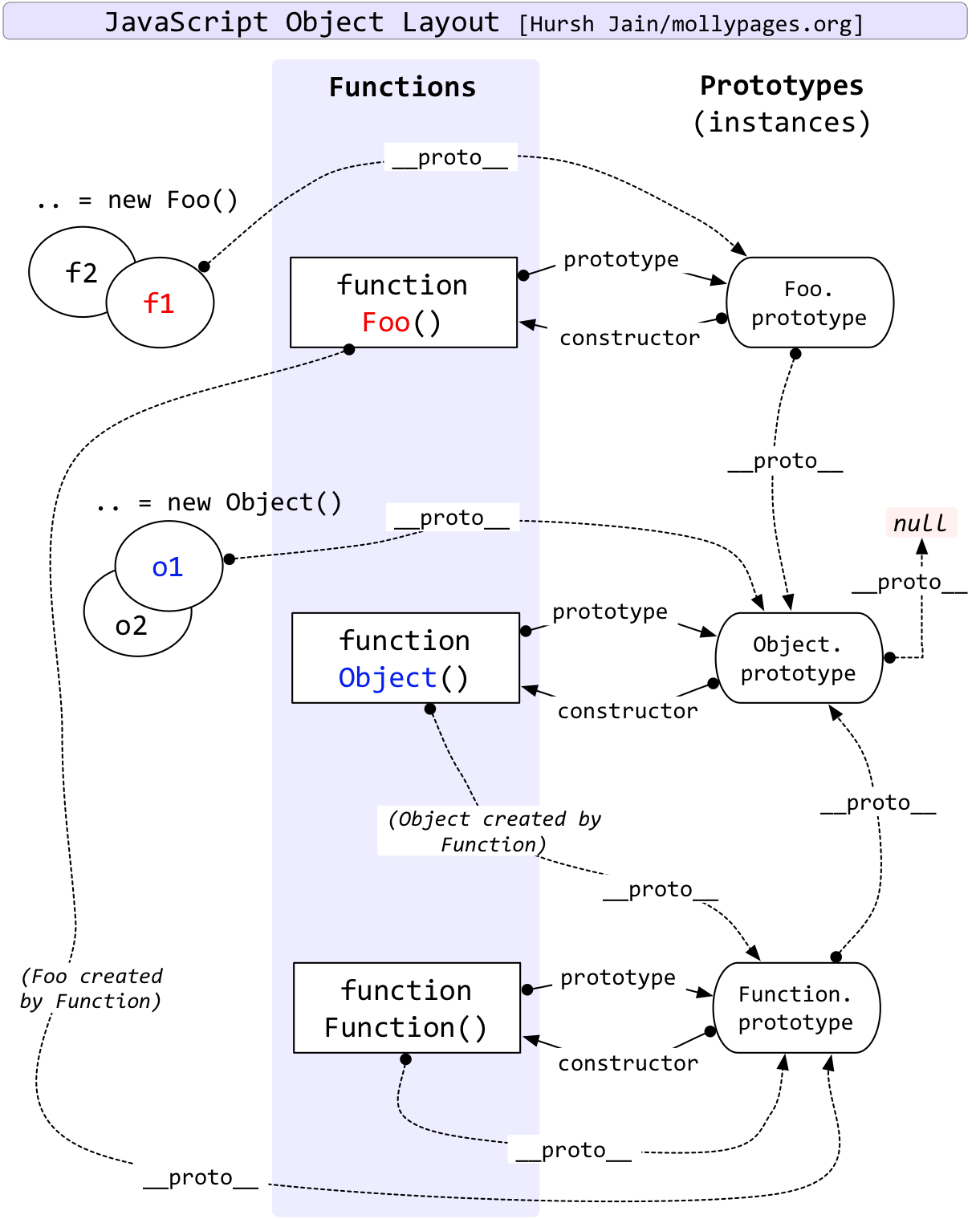
在读取对象的属性时候,首先查找自身的属性。如果没有找到,则会进一步查找构造函数的prototype对象的属性。这就是原型链的基本原理。这样一来,在通过构造函数生成的对象之间就实现了对其prototype对象的属性的共享。
这种共享用面向对象的术语来说就是继承。通过继承可以生成具有同样执行方式的对象,不过请注意,如果修改构造函数的prototype,已经生成的对象也会发生相应的改变。
- 输出顺序-考察变量提升、原型链、运算符优先级
答案是 2 4 1 1 2 3 3
function Foo() {
getName = function () { console.log(1); };
return this;
}
Foo.getName = function () { console.log(2);};
Foo.prototype.getName = function () { console.log(3);};
var getName = function () { console.log(4);};
function getName() { console.log(5);}
// 请写出以下输出结果:
Foo.getName(); // 函数属性
getName(); // 变量提升
Foo().getName(); // 调用Foo时, window上的getName变成1
getName();
new Foo.getName();
new Foo().getName(); // new的时候返回实例,查找到原型链上有getName
new new Foo().getName(); // .运算符的优先级大于new
-
instance运算与isPrototypeOf方法虽然也可以用constructor属性来判断对象类型,不过更为常见的做法是使用instanceof运算来进行判断。对于通过原型链进行派生继承的情况,instanceof运算也是有效的。
var d = new Date() d instanceof Date // true d instanceof Object // true function Derived() {} function Base() {} Derived.prototype = new Base() var obj = new Derived() obj instanceof Derived // true obj instanceof Base // true obj instanceof Object // true Derived.prototype.isPrototypeOf(obj) // true Base.prototype.isPrototypeOf(obj) // true Object.prototype.isPrototypeOf(obj) //true -
为什么在JavaScript中“Object instanceof Function”和“Function instanceof Object”都返回true?
https://codeday.me/bug/20171204/102055.html
instanceof 主要的实现原理就是只要右边变量的 prototype 在左边变量的原型链上(__proto__)即可。Object.getPrototypeOf(obj) === AAA.prototype Object.getPrototypeOf(Object.getPrototypeOf(obj)) === AAA.prototype ... //一直到原型链尽头 -
关于constructor
可以通过constructor属性来从对象处获取其构造函数,constructor不是对象的直接属性,而是通过原型链查找到的属性。function A() {} function B() {} A.prototype = new B() var obj = new A() obj.constructor // function B(){} A.prototype.constructor = A obj.constructor // function A() {} -
js实现继承的几种方式以及优缺点
JavaScript深入之继承的多种方式和优缺点 -
js创建对象的7种方式及其优缺点
JavaScript 创建对象的 7 种方法 -
new创建对象过程发生了什么
创建新对象person={}
新对象的__proto__属性指向构造函数的原型对象
构造函数的this指向新对象
执行构造函数内部代码,给person(this)添加属性
返回新对象personfunction new2 (func, ...rest) { var o= {}; o._proto_ = Person.prototype; //引用构造函数的原型对象 func.apply(person, rest); return o; }https://blog.youkuaiyun.com/h15882065951/article/details/69913881
-
判断变量类型
- typeof
typeof 可以判断number, string, object, boolean, function, undefined, symbol 这七种类型,但是,很遗憾的一点是,typeof 在判断一个 object的数据的时候只能告诉我们这个数据是 object, 而不能细致的具体到是哪一种 object。let s = new String('abc'); typeof s === 'object'// true s instanceof String // true - instanceof
// 缺点 [] instanceof Array // true [] instanceof Object //true - Object.prototype.toString.call可以比较准确判断类型
https://juejin.im/post/5b0b9b9051882515773ae714
-
js数组常见方法
slice(生成新数组)、splice(在原数组上操作)、concat(新数组)、shift(从原数组删除第一个元素)、unshift(从原数组头部增加元素)、pop(删除最后一个元素)、map(遍历,return的数值组成新数组)、reduce(遍历,return的数值参与到遍历中,最后返回结果)、filter(return值为true时加入新数组)、join(转为字符串)
slice和splice的区别 -
数组去重
object键值对+filter
考虑键值对的key为字符串类型,object[typeof item + item]=true
object[‘1’] 和 object[1]相同,使用typeof区分。 -
DOM操作
https://blog.youkuaiyun.com/qq_22944825/article/details/78047070
parentElement、children(数组)、removeChild、innerHTML、firstElementChild、lastElementChild、nextElementSibling、previousElementSibling等等 -
跨域处理
图像ping相类似的,由于img标签也是不受跨域约束。但是需要注意的是图像PING和JSONP的区别。
图像ping的数据是通过查询字符串的形式发送的,而响应可以是任意内容,而通常是图或者204响应。通过图像ping,浏览器得不到任何具体的数据,但可以通过侦听onload和error事件知道响应是什么时候接收到的,利用这一特性,图像ping非常适合跟踪用户点击或动态广告曝光次数.JSONP
JSONP优缺点
JSONP安全防范-decodeURIComponent防止XSS漏洞
前端解决跨域问题的8种方案(最新最全)
ajax跨域,这应该是最全的解决方案了 -
箭头函数的this指向
“箭头函数”的this,总是指向定义时所在的对象,而不是运行时所在的对象。“箭头函数”的this,总是指向定义时所在的对象,而不是运行时所在的对象。(封闭词法上下文)
https://segmentfault.com/a/1190000015087728
不能做构造函数:因为没有自己的this
call和apply无效
没有prototype
不适用于作为对象的方法 -
异步同步加载javascript(堵塞和非堵塞)
https://www.jianshu.com/p/055b0ea0d03c异步(async) 脚本将在其加载完成后立即执行,而 延迟(defer) 脚本将等待 HTML 解析完成后,并按加载顺序执行。
-
匿名函数,仅在调用时,才临时创建函数对象和作用域链对象;调用完,立即释放,所以匿名函数比非匿名函数更节省内存空间
-
关于es6
https://juejin.im/post/59c8aec0f265da065c5e965e
https://www.cnblogs.com/fengxiongZz/p/8191503.html
const PENDING = 'pending';
const FULFILLED = 'fulfilled';
const REJECTED = 'rejected';
function Promiseh (fn) {
let self = this;
self.value = null;
self.error = null;
self.status = PENDING;
self.onFulfilled = [];
self.onRejected = [];
function resolve (value) {
if (self.status === PENDING) {
setTimeout(() => {
self.status = FULFILLED;
self.value = value;
self.onFulfilled.forEach(onFulfilled => {
onFulfilled(self.value);
});
}, 0);
}
}
function reject (error) {
if (self.status === PENDING) {
setTimeout(() => {
self.status = REJECTED;
self.error = error;
self.onRejected.forEach(onRejected => {
onRejected(self.error);
});
}, 0);
}
}
fn(resolve, reject);
}
Promiseh.prototype.then = function (onFulfilled, onRejected) {
let self = this;
let bridgePromise = null;
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value
onRejected = typeof onRejected === 'function' ? onRejected : error => { throw error; }
if (self.status === PENDING) {
return bridgePromise = new Promiseh((resolve, reject) => {
self.onFulfilled.push((value) => {
try {
let x = onFulfilled(value);
resolvePromise(bridgePromise, x, resolve, reject);
} catch (e) {
reject(e);
}
});
self.onRejected.push(error => {
try {
let x = onRejected(error);
resolvePromise(bridgePromise, x, resolve, reject);
} catch (e) {
reject(e);
}
})
});
} else if (self.status === FULFILLED) {
return bridgePromise = new Promiseh((resolve, reject) => {
try {
let x = onFulfilled(self.value);
resolvePromise(bridgePromise, x, resolve, reject);
} catch (e) {
reject(e);
}
});
} else {
return bridgePromise = new Promiseh((resolve, reject) => {
try {
let x = onRejected(self.error);
resolvePromise(bridgePromise, x, resolve, reject);
} catch (e) {
reject(e);
}
})
}
}
Promiseh.prototype.catch = function (onRejected) {
return this.then(null, onRejected);
}
// 一直到promise调用的最后一个才返回
function resolvePromise (bridgePromise, x, resolve, reject) {
if (x instanceof Promiseh) { // 函数返回值为promise
if (x.status === PENDING) {
x.then(y => {
resolvePromise(bridgePromise, y, resolve, reject);
}, error => {
reject(error);
});
} else {
x.then(resolve, reject); // 执行结束直接把resolve和reject传进去
}
} else {
resolve(x);
}
}
new Promiseh((resolve, reject) => {
setTimeout(() => {
resolve('88');
}, 100);
}).then(aa => {
console.log(aa, 'hhhh')
return 99
}).then(bb => {
console.log(bb, 'hhhh')
return new Promiseh((resolve, reject) => {
setTimeout(() => {
reject(100);
}, 1000);
})
}).then(d => {
console.log(d ,'kkk')
}, d => {
console.log(d, dd)
}).catch(e => {
console.log(e)
})
<html>
<body>
<h1>hello</h1>
</body>
</html>
<script>
console.log('script start')
new Promise((resolve, reject) => {
resolve('promise1')
}).then(() => {
console.log('promise1 then')
setTimeout(() => {
console.log('settimeout4')
}, 0);
})
console.log('script will end')
setTimeout(() => {
console.log('settimeout1')
}, 0);
setTimeout(() => {
console.log('settimeout3')
}, 0);
</script>
<script>
console.log('script end')
setTimeout(() => {
console.log('settimeout2')
}, 0);
</script>
<script>
console.log('last script')
</script>
解析
script标签属于宏任务,所以当前队列三个宏任务
1. 执行第一个宏任务script,输出—script start, 存储一个微任务then
2. 输出—script will end, 存储两个宏任务settimeout1和settimeout3
3. 下一个宏任务script执行前,必须清空微任务队列,输出—promise1 then, 存储宏任务settimeout4
4. 没有微任务了,查看宏任务队列,排在前面的是第二个script标签,输出—script end, 存储宏任务settimeout2
5. 执行下一个宏任务,输出—last script
6.依次执行剩下的宏任务,输出settimeout1、settimeout3、ettimeout4、settimeout2
node.js的事件循环
console.log(1);
setTimeout(() => {
console.log(2);
process.nextTick(() => {
console.log(3);
});
new Promise((resolve) => {
console.log(4);
resolve();
}).then(() => {
console.log(5);
});
});
new Promise((resolve) => {
console.log(7);
resolve();
}).then(() => {
console.log(8);
});
process.nextTick(() => {
console.log(6);
});
setTimeout(() => {
console.log(9);
process.nextTick(() => {
console.log(10);
});
new Promise((resolve) => {
console.log(11);
resolve();
}).then(() => {
console.log(12);
});
});
答案 node <11:1 7 6 8 2 4 9 11 3 10 5 12 node>=11:1 7 6 8 2 4 3 5 9 11 10 12
解析
宏任务和微任务
宏任务:macrotask,包括setTimeout、setInerVal、setImmediate(node独有)、requestAnimationFrame(浏览器独有)、I/O、UI rendering(浏览器独有)
微任务:microtask,包括process.nextTick(Node独有)、Promise.then()、Object.observe、MutationObserver
Promise构造函数中的代码是同步执行的,new Promise()构造函数中的代码是同步代码,并不是微任务
Node.js中的EventLoop执行宏队列的回调任务有6个阶段
1.timers阶段:这个阶段执行setTimeout和setInterval预定的callback
2.I/O callback阶段:执行除了close事件的callbacks、被timers设定的callbacks、setImmediate()设定的callbacks这些之外的callbacks
3.idle, prepare阶段:仅node内部使用
4.poll阶段:获取新的I/O事件,适当的条件下node将阻塞在这里
5.check阶段:执行setImmediate()设定的callbacks
6.close callbacks阶段:执行socket.on(‘close’, …)这些callbacks
NodeJs中宏队列主要有4个
1.Timers Queue
2.IO Callbacks Queue
3.Check Queue
4.Close Callbacks Queue
这4个都属于宏队列,但是在浏览器中,可以认为只有一个宏队列,所有的macrotask都会被加到这一个宏队列中,但是在NodeJS中,不同的macrotask会被放置在不同的宏队列中。
NodeJS中微队列主要有2个
1.Next Tick Queue:是放置process.nextTick(callback)的回调任务的
2.Other Micro Queue:放置其他microtask,比如Promise等
在浏览器中,也可以认为只有一个微队列,所有的microtask都会被加到这一个微队列中,但是在NodeJS中,不同的microtask会被放置在不同的微队列中。
Node.js中的EventLoop过程
1.执行全局Script的同步代码
2.执行microtask微任务,先执行所有Next Tick Queue中的所有任务,再执行Other Microtask Queue中的所有任务
3.开始执行macrotask宏任务,共6个阶段,从第1个阶段开始执行相应每一个阶段macrotask中的所有任务,注意,这里是所有每个阶段宏任务队列的所有任务,在浏览器的Event Loop中是只取宏队列的第一个任务出来执行,每一个阶段的macrotask任务执行完毕后,开始执行微任务,也就是步骤2
4.Timers Queue -> 步骤2 -> I/O Queue -> 步骤2 -> Check Queue -> 步骤2 -> Close Callback Queue -> 步骤2 -> Timers Queue …
5.这就是Node的Event Loop
Node 11.x新变化
现在node11在timer阶段的setTimeout,setInterval…和在check阶段的immediate都在node11里面都修改为一旦执行一个阶段里的一个任务就立刻执行微任务队列。为了和浏览器更加趋同.
- indexedDB(数据库,大部分浏览器不支持)、userData(只有ie支持)、flash cookie、 http cookie(cookie)、session storage(浏览器会话)、local storage(永久)
cookie篇
document.cookie = “name=value[; expires=GMTDate][; domain=domain][; path=path][; secure]”
我们知道 cookie 是存在用户硬盘中,用户每次访问站点时,Web应用程序都可以读取 Cookie 包含的信息。当用户再次访问这个站点时,浏览器就会在本地硬盘上查找与该 URL 相关联的 Cookie。如果该 Cookie 存在,浏览器就将它添加到request header的Cookie字段中,与http请求一起发送到该站点。
当然,用户也可以通过expries设置删除时间。这个值是个GMT格式的日期,类似例三中的Sat, 04 Nov 2017 16:00:00 GMT,这表明这个 cookie 将在2017-11-04的16时整失效,在此期间浏览器关闭后此cookie仍会保存在用户的机器中。GMT格式可以通过 toGMTString() 和 toUTCString() 获得。如果设置的失效时间是个以前的时间,则 cookie 会被立即删除,这也是用来删除 cookie 的方法。
在新的http协议中已经使用 max-age 属性来取代 expries。expries 表示的是失效时间,准确讲是「时刻」,max-age表示的是生效的「时间段」,以「秒」为单位。若 max-age 为正值,则表示 cookie 会在 max-age 秒后失效。如例四中设置"max-age=10800;",也就是生效时间是3个小时,那么 cookie 将在三小时后失效。若 max-age 为负值,则cookie将在浏览器会话结束后失效,即 session,max-age的默认值为-1。若 max-age 为0,则表示删除cookie。

















 3602
3602




 到【灌水乐园】发言
到【灌水乐园】发言







