




这篇文章提出了一种通过细粒度AI反馈来检测和缓解大型视觉语言模型(LVLMs)中幻觉现象的方法。主要内容如下:
-
问题背景:LVLMs在多模态任务中表现出色,但生成的文本常与视觉输入不符,即出现幻觉现象,限制了其应用。现有方法多为粗粒度检测或依赖昂贵的人工标注。
-
方法概述:
-
细粒度AI反馈:利用专有模型(如GPT-4/GPT-4V)生成小规模句子级幻觉标注数据集,涵盖对象、属性和关系幻觉。
-
幻觉检测模型:基于细粒度反馈训练模型,能够进行句子级幻觉检测,并评估幻觉的严重程度。
-
检测-重写管道:自动构建偏好数据集,通过检测模型识别幻觉,并由重写模型生成非幻觉响应。
-
幻觉严重程度感知的直接偏好优化(HSA-DPO):将幻觉严重程度纳入偏好学习,优先缓解关键幻觉。
-
-
实验与结果:
-
幻觉检测:在MiHaluBench等基准上,检测模型取得了最先进的结果,超越了GPT-4V和Gemini。
-
幻觉缓解:HSA-DPO在Object HalBench和AMBER等基准上显著降低了幻觉率,优于现有方法,同时保持了多模态能力。
-
-
贡献:
-
首次利用闭源模型生成细粒度AI反馈,减少人工标注。
-
提出自动构建偏好数据集的管道,降低标注成本。
-
引入HSA-DPO,优先缓解严重幻觉。
-
通过大量实验验证了方法的有效性。
-
该文章通过细粒度AI反馈和HSA-DPO,有效检测和缓解了LVLMs中的幻觉现象,提升了模型的生成质量和应用可靠性。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
快速发展的大型视觉语言模型(LVLMs)在多模态任务中展现了显著的能力,但仍面临幻觉现象,即生成的文本与给定上下文不符,这严重限制了LVLMs的应用。大多数先前的工作在粗粒度水平上检测和缓解幻觉,或需要昂贵的标注(例如,由专有模型或人类专家标注)。为了解决这些问题,我们提出通过细粒度AI反馈来检测和缓解LVLMs中的幻觉。基本思路是通过专有模型生成一个小规模的句子级幻觉标注数据集,并训练一个幻觉检测模型,该模型能够进行句子级幻觉检测,涵盖主要的幻觉类型(即对象、属性和关系)。然后,我们提出一个检测-重写的自动管道来构建偏好数据集,用于训练幻觉缓解模型。此外,我们提出区分幻觉的严重程度,并引入幻觉严重程度感知的直接偏好优化(HSA-DPO),通过将幻觉的严重程度纳入偏好学习来缓解LVLMs中的幻觉。大量实验证明了我们方法的有效性。
关键词: 大型视觉语言模型,幻觉检测,幻觉缓解,直接偏好优化
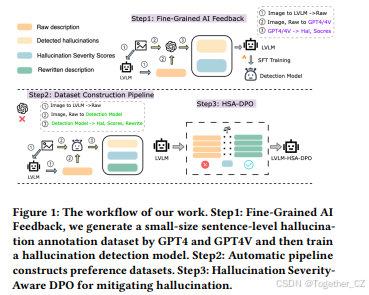
图1:我们工作的流程。
步骤1:细粒度AI反馈,我们通过GPT4和GPT4V生成一个小规模的句子级幻觉标注数据集,然后训练一个幻觉检测模型。
步骤2:自动管道构建偏好数据集。
**步骤3:幻觉严重程度感知的直接偏好优化(HSA-DPO)**用于缓解幻觉。
1. 引言
大型语言模型(LLMs)在自然语言处理领域取得了显著进展,并进一步扩展到涵盖多模态数据,如语言和视觉,从而催生了大型视觉语言模型(LVLMs)。尽管LVLMs在广泛的视觉语言任务中表现出色,但它们仍然面临幻觉现象,即生成的文本与给定上下文不符。换句话说,生成的文本包含与视觉输入相关的错误对象、属性和关系,这严重限制了LVLMs的应用。
针对LVLMs中的幻觉现象,研究主要集中在幻觉检测和幻觉缓解两个方面。幻觉检测旨在识别LVLM输出中的幻觉,以防止潜在的恶意使用。例如,UNIHD利用GPT-4V或Gemini从响应中提取可验证的声明,然后使用外部视觉工具检测这些声明中是否存在幻觉。幻觉缓解则旨在使LVLMs生成更忠实的响应,主要分为无训练和基于训练的方法。无训练方法通过后处理LVLMs的输出来解决潜在的幻觉问题,虽然不需要额外的训练成本,但往往会降低推理速度。基于训练的方法则通过进一步的指令微调或偏好学习来减少LVLMs中的幻觉。
尽管已有诸多努力,但在检测和缓解LVLMs中的幻觉方面仍存在一些挑战。首先,用于基于训练的缓解方法的偏好数据需要昂贵的标注,无论是通过人类专家还是专有商业模型。其次,偏好数据通常是在响应级别上构建的,这对于彻底检测和缓解幻觉来说是次优的。最后,现有研究通常将所有幻觉同等对待,导致在处理较不重要的幻觉时,更关键的幻觉被忽视。
为了解决这些问题,我们提出通过细粒度AI反馈来检测和缓解LVLMs中的幻觉。如图2所示,我们的框架包括四个关键组件:(1)细粒度AI反馈:通过专有模型生成一个小规模的句子级幻觉标注数据集,用于全面的幻觉检测和缓解;(2)基于细粒度AI反馈的幻觉检测模型训练:训练一个幻觉检测模型,该模型能够进行句子级幻觉检测,涵盖主要的幻觉类型(即对象、属性和关系);(3)检测-重写管道用于构建偏好数据集:通过检测模型和重写模型自动构建偏好数据集;(4)幻觉严重程度感知的直接偏好优化(HSA-DPO):区分幻觉的严重程度,并引入HSA-DPO,将幻觉严重程度纳入偏好学习,优先缓解关键幻觉。
我们在一系列幻觉检测和缓解基准上进行了大量实验,实验结果证明了我们方法的有效性。在幻觉检测方面,我们的检测模型在MiHaluBench上取得了新的最先进结果,超越了GPT-4V和Gemini。在幻觉缓解方面,HSA-DPO在AMBER上将幻觉率降低了36.1%,在Object HalBench上将CHAIRs降低了76.3%,优于竞争性闭源LVLMs。这些结果证明了细粒度AI反馈和HSA-DPO的有效性。
2. 相关工作
尽管LVLMs取得了显著进展,但它们仍然面临严重的幻觉问题。针对这一问题,已有大量研究,主要分为幻觉检测和幻觉缓解两个方面。
2.1 检测LVLMs中的幻觉
当前的幻觉检测方法主要利用现成工具的能力,如闭源LLMs、LVLMs或视觉工具。GAVIE利用GPT-4来评估对象幻觉。Zhao等人提出了句子级幻觉度量SHR,利用GPT-4确定LVLM输出中是否存在幻觉。UNIHD利用GPT-4V或Gemini从LVLM生成中提取可验证的声明,然后使用视觉工具进行幻觉检测。
与先前研究相比,我们的检测模型基于专有LVLMs的细粒度反馈进行训练,涵盖主要幻觉类型(即对象、属性和关系),并能评估幻觉的严重程度并提供详细原因。
2.2 缓解LVLMs中的幻觉
幻觉缓解主要分为无训练和基于训练的方法。无训练方法通过后处理LVLMs的输出来解决潜在的幻觉问题。例如,Woodpecker引入了一种检测-纠正的幻觉缓解方法,借助ChatGPT和VQA模型。然而,无训练方法往往会降低推理速度。基于训练的方法则通过进一步训练来减少LVLMs中的幻觉,例如指令微调或偏好学习。例如,LRV在视觉指令上进行长度控制的微调以缓解幻觉。其他研究则考虑通过偏好学习使LVLMs偏向于生成非幻觉响应。
与先前研究相比,我们提出了一种自动构建偏好数据集的管道,并引入了幻觉严重程度感知的偏好学习算法,优先缓解关键幻觉。
3. 方法论
3.1 来自LVLMs的细粒度反馈
在本小节中,我们介绍了用于从LVLMs构建细粒度AI反馈数据集的任务和数据源。
3.1.1 任务
我们研究了两种典型的图像到文本任务中的幻觉现象。第一个任务是详细描述生成,要求模型对视觉内容进行全面的叙述。第二个任务是视觉复杂推理,评估模型在给定图像内容的情况下回答复杂问题的能力。
3.1.2 数据源
我们选择了**Visual Genome(VG)**数据集作为数据源,因为其中的图像清晰、内容丰富,并且与多个边界框相关联,这些边界框指定了图像内容中的各种对象、每个对象的属性及其空间关系。
3.1.3 幻觉响应生成
在收集了VG数据集中的图像和提示后,我们生成幻觉描述以收集AI反馈。具体来说,给定目标LVLM M,对于详细描述生成,我们从VG数据集中随机选择5000张图像,并从RLHF-V的指令集中随机选择指令输入M,生成可能包含幻觉的响应。对于视觉复杂推理,我们将图像和相关问题输入M,生成可能包含幻觉的响应。
3.1.4 来自GPT-4/GPT-4V的细粒度幻觉检测
尽管当前的LVLMs具有出色的视觉和理解能力,但在生成长篇详细描述和复杂推理响应时,它们往往会产生一个或多个幻觉。手动标注大规模视觉语言数据集耗时、昂贵且具有挑战性。我们利用专有模型GPT-4和GPT-4V对生成的6000个幻觉描述进行细粒度幻觉检测。
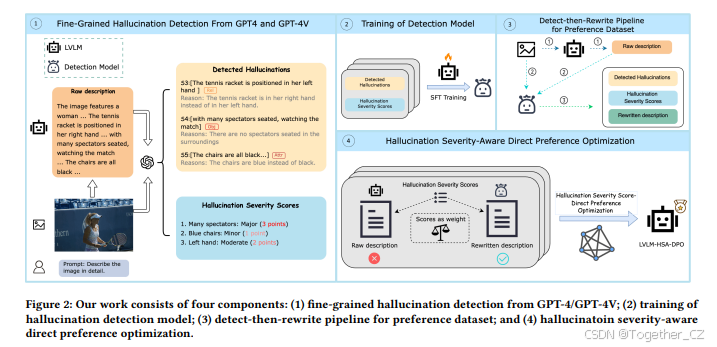
图2:我们的工作包括四个组成部分:
(1) 从GPT-4/GPT-4V进行细粒度幻觉检测;
(2) 幻觉检测模型的训练;
(3) 检测-重写管道用于构建偏好数据集;
(4) 幻觉严重程度感知的直接偏好优化(HSA-DPO)。
具体来说,对于详细描述生成,我们将幻觉响应和相关的对象边界框输入GPT-4以生成反馈。对于视觉复杂推理,输入包括原始图像和LVLM生成的幻觉响应。反馈包括以下方面:
-
句子级幻觉及其解释:反馈的第一部分是在严格句子级别上识别响应中的幻觉,并提供解释。如果在一个句子中检测到幻觉,将在句子末尾插入一个占位符作为幻觉指示。以下是三种幻觉类型及其对应的占位符:(i)**-object-表示对象幻觉,例如感知到实际不存在的物理实体;(ii)-relationship-表示关系幻觉,例如对对象之间关系的描述不准确;(iii)-attribute-**表示属性幻觉,例如对对象特征的感知不准确。
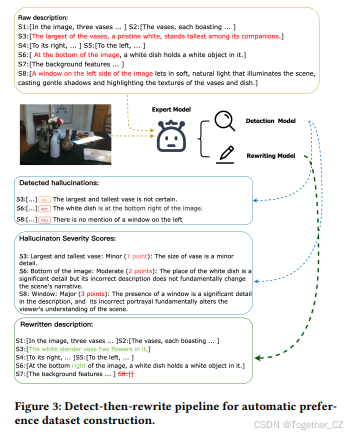
图3:用于自动构建偏好数据集的检测-重写管道。
对于每个识别的幻觉,反馈还提供了解释其被视为幻觉的原因,从而提高幻觉检测过程的可解释性。
-
幻觉严重程度评分及其解释:反馈的第二部分是幻觉严重程度评分,用于区分不同幻觉的影响。具体来说,我们定义了以下评分:(i)轻微(1分):幻觉涉及次要细节,不会显著影响场景的整体描述;(ii)中等(2分):幻觉涉及场景中明显的错误细节,但场景的整体理解仍得以保持;(iii)严重(3分):幻觉引入了显著错误或完全虚构的元素,从根本上改变了观众对场景的理解。
评分过程量化了幻觉的严重程度,促进了对描述准确性的细致评估。这些评分有助于评估幻觉的严重程度,并在训练阶段增强检测专家与AI反馈之间关于幻觉严重程度的一致性。
3.2 用于幻觉检测的细粒度反馈
在收集了细粒度AI反馈后,我们现在可以训练一个幻觉检测模型,该模型不仅能够进行细粒度幻觉检测,还能为检测到的幻觉提供严重程度评分。
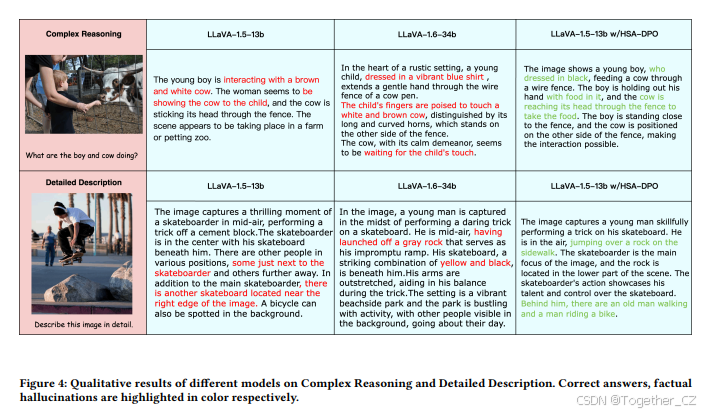
图4:不同模型在复杂推理和详细描述任务上的定性结果。 正确答案和事实幻觉分别用颜色高亮标注。

3.3 用于自动构建偏好数据集的检测-重写管道
如引言所述,构建用于缓解幻觉的偏好数据集通常需要昂贵的标注,无论是通过人类专家还是专有商业模型,且偏好数据通常是在响应级别上构建的。为了更有效地构建大规模偏好数据集,我们提出了一种检测-重写的自动管道。
具体来说,给定一个包含幻觉的响应,检测模型首先识别响应中每个句子中的幻觉。然后,重写模型将检测到的幻觉重写为非幻觉响应,从而形成用于偏好学习的数据集。该管道使我们能够以更低的成本标注大规模偏好数据集,用于训练缓解模型。
3.4 幻觉严重程度感知的直接偏好优化(HSA-DPO)
为了进一步缓解LVLMs中的幻觉,我们提出了一种幻觉严重程度感知的直接偏好优化(HSA-DPO),将幻觉的严重程度纳入偏好学习。具体来说,HSA-DPO的动作评分公式如下:

4. 实验
在本节中,我们通过实验评估了我们的方法在检测和缓解LVLM幻觉方面的有效性。
4.1 数据集和指标
我们介绍了用于评估幻觉检测和缓解的数据集和指标。对于幻觉检测,我们使用以下基准:
-
MHaluBench:一个用于统一评估图像到文本和文本到图像设置中幻觉检测的新元评估基准。我们采用图像到文本部分来评估我们的检测模型。
-
细粒度幻觉检测数据集:我们提出了一个由54张图像和150个片段组成的人工标注数据集,涵盖对象、属性和关系幻觉。我们评估其二元分类(即幻觉片段)和多分类(即不同类型的幻觉)。
对于幻觉缓解,我们使用以下基准:
-
Object HalBench:一个广泛采用的基准,用于评估详细图像描述中的对象幻觉。我们遵循Yu等人使用8个不同的提示生成详细图像描述。使用CHAIRs(即具有幻觉的响应百分比)和CHAIRi(即所有对象提及中幻觉对象提及的百分比)作为指标。
-
AMBER:一个多维幻觉基准。我们使用AMBER的生成部分,并报告以下指标:CHAIR、Cover、Hal和Cog。
-
MMHal-Bench:由LLaVa-RLHF引入,使用GPT-4检测一些预定义的对象幻觉,并将模型输出与标注响应进行比较。我们报告GPT-4评分的总体分数和幻觉率。
-
POPE:一个通过问答形式测试LVLMs的对象幻觉评估基准。我们选择POPE的对抗部分,并报告其F1分数。
除了上述幻觉检测和缓解基准外,我们还采用了广泛使用的LLava Bench in the wild来评估缓解训练后的多模态能力。
幻觉严重程度评分是我们提出的一个指标,用于评估模型响应中细粒度幻觉的严重程度。严重程度评分范围从0到3。
4.2 基线
我们将我们的方法与一系列领先的LVLMs进行了比较。
-
InstructBLIP:在26个公共数据集的聚合上微调BLIP。
-
LLaVA 1.5:在558K选定的图像-文本对上进行预训练,并在665K多模态指令上进行微调。
-
Qwen-VL-Chat:在14亿图像-文本对上进行预训练,然后在50M高质量多模态指令上进行微调。
-
GPT-4V:OpenAI开发的知名商业模型。
我们还采用了以下特定的幻觉缓解方法作为基线:
-
LRV:在GPT-4创建的指令上进行长度控制的指令微调,以减少幻觉。
-
LLaVA-RLHF:使用10,000个人工标注的偏好数据集训练奖励模型,然后使用近端策略优化(PPO)算法优化策略模型。
-
RLHF-V:在片段级别收集人类偏好,然后使用密集直接偏好优化(DDPO)来缓解幻觉。
-
Silkie:利用GPT-4V评估12个LVLMs生成的响应的有用性、视觉忠实度和伦理考虑,然后通过直接偏好优化(DPO)将LVLMs与GPT-4V的偏好数据对齐,以生成非幻觉响应。
4.3 实施细节
我们基于InternVL-ChatPlus-v1.2训练幻觉检测模型,该模型使用InternVit-6B作为视觉模块,Nous-Hermes-2-Yi-34B作为语言模型。我们使用LoRA进行高效训练。我们采用LLaVA-1.6-34B进行零样本提示作为重写模型。对于HSA-DPO,我们使用LoRA对LLaVA-1.5-13b进行2个epoch的微调。
4.4 主要结果
我们分别报告了幻觉检测和缓解的主要结果。
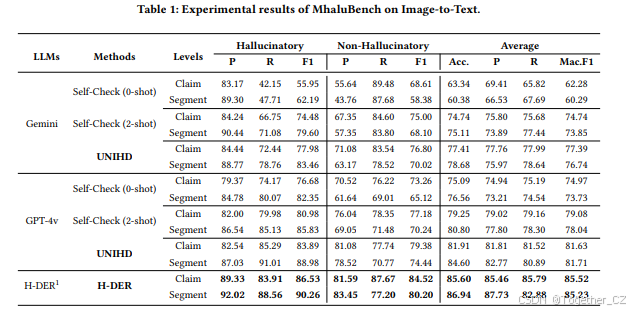
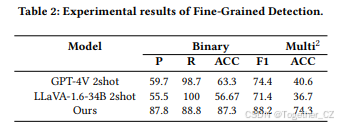
幻觉检测:表1和表2报告了在幻觉检测基准上的主要实验结果。我们可以得出以下结论。首先,在MHaluBench上,我们的检测模型(Hallucination DElectoR, H-DER)在平均上取得了最先进的结果,超越了GPT-4V和Gemini。具体来说,在声明级别上,我们的检测模型在Mac. F1分数上超越了UNIHD 4.7%,在Mac. F1分数上超越了GPT-4V Self-Check 2-shot 8.1%。在片段级别上的改进与声明级别一致。其次,在我们构建的细粒度检测数据集上,我们的检测模型在二元分类中取得了88.2%的F1分数,在细粒度分类中取得了74.3%的准确率,超越了GPT-4V 2-shot和LLaVA-1.6-34b 2-shot。
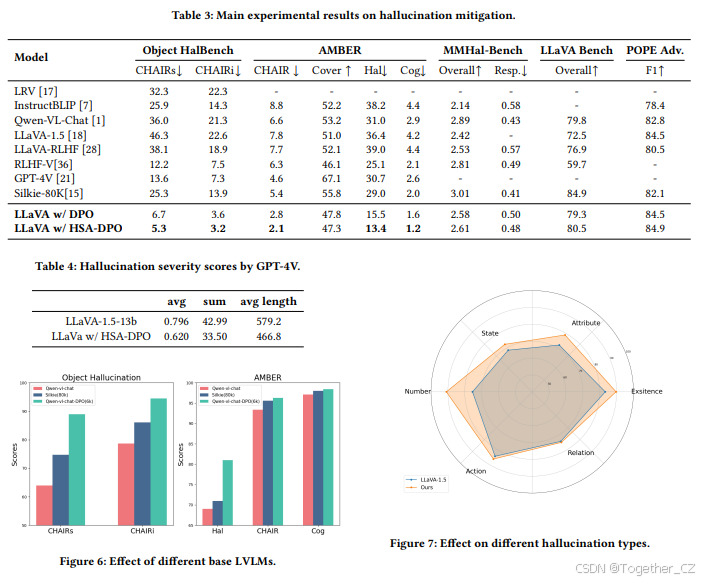
幻觉缓解:表3报告了在幻觉缓解基准上的主要结果。我们可以得出以下结论。首先,HSA-DPO在Object Halbench上取得了最先进的结果,甚至超越了领先的LVLMs GPT-4V。其次,HSA-DPO将LLaVA-1.5的幻觉率在Object HalBench上降低了76.3%,在AMBER上降低了36.1%,超越了强大的闭源模型。第三,在偏好学习后,HSA-DPO仍能保持其多模态能力,这通过MMHal-Bench和LLaVA Bench in the wild的总体指标得到了证明。第四,与在大规模AI反馈或人工标注数据集上训练的模型相比,我们也给出了更好的幻觉缓解结果,这证明了使用细粒度AI反馈检测和缓解LVLMs中幻觉的有效性。
4.5 分析
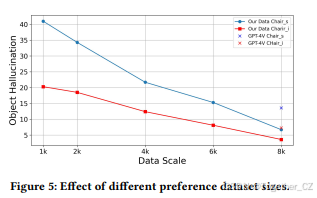
偏好数据集大小的影响:我们进行了实验,研究了不同偏好数据集大小对Object HalBench的影响。如图5所示,我们观察到随着偏好数据集大小的增加,HSA-DPO的幻觉率下降,这证明了我们管道的重要性,因为它能够以更低的成本标注偏好数据集。此外,当训练数据集大小达到8k时,我们的模型在CHAIRs和CHAIRi上均超越了GPT-4V。
不同基础LVLMs的影响:为了评估不同基础模型的影响,我们在Qwen-VL-Chat上训练HSA-DPO。我们使用提出的管道构建了一个大小为6k的偏好数据集来训练Qwen-VL-Chat。我们还与Silkie进行了比较,后者也在Qwen-VL-Chat上训练,但使用了80k的粗粒度偏好数据集。图6中的结果表明,我们的模型在Qwen-VL-Chat上取得了显著改进。这些结果表明,我们的方法可以应用于各种LVLMs基础模型,以缓解幻觉。
对不同幻觉类型的影响:为了评估我们的方法对不同幻觉类型(例如,对象、属性和关系)的影响,我们在Amber基准上进行了实验,并报告了不同幻觉类型的F1分数。如图7所示,HSA-DPO在LLaVA-1.5上在所有六种幻觉类型上均优于LLaVA-1.5。
5. 结论
在本工作中,我们提出通过细粒度AI反馈来检测和缓解LVLMs中的幻觉。该方法包括三个关键组件:(1)细粒度AI反馈生成句子级幻觉标注数据集;(2)通过细粒度AI反馈训练幻觉检测模型;(3)幻觉严重程度感知的直接偏好优化(HSA-DPO),将幻觉严重程度纳入偏好学习,优先缓解关键幻觉。在检测和缓解基准上的大量实验证明了我们方法的有效性。



















 2280
2280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











