




这篇文章的主要内容可以总结如下:
-
研究问题:在给定的计算预算下,如何最优地分配模型大小和训练token数量,以实现最佳的语言模型性能。
-
主要发现:
-
当前的大型语言模型(如GPT-3、Gopher等)通常训练不足,原因是模型规模增加时,训练token数量保持不变。
-
通过训练超过400个不同规模的模型,作者发现模型大小和训练token数量应等比例扩展:每当模型大小翻倍时,训练token数量也应翻倍。
-
基于这一发现,作者训练了一个名为Chinchilla的模型,其参数为700亿,训练token数量为1.4万亿,使用与Gopher(2800亿参数)相同的计算预算。
-
Chinchilla在多个下游任务中显著优于Gopher、GPT-3、Jurassic-1和Megatron-Turing NLG等更大的模型,并且在MMLU基准测试中达到了67.5%的最新准确率。
-
-
方法:
-
作者提出了三种不同的方法来估计模型大小和训练token数量的最优分配,并通过实验验证了这些方法的有效性。
-
所有方法都表明,随着计算预算的增加,模型大小和训练token数量应等比例增加。
-
-
意义:
-
Chinchilla的成功表明,更小的模型但更多的训练数据可以在相同的计算预算下实现更好的性能。
-
这一发现挑战了当前大型语言模型领域“越大越好”的普遍观念,强调了训练数据量的重要性。
-
此外,Chinchilla的较小模型规模使其在推理和微调时更加高效,便于实际应用。
-
-
未来工作:
-
作者指出,未来的研究应更加关注数据集的扩展,尤其是在确保数据质量的前提下。
-
随着训练token数量的增加,数据集的伦理和隐私问题也需要更加重视。
-
核心结论:
模型大小和训练token数量应等比例扩展,Chinchilla的成功证明了在相同计算预算下,更小的模型但更多的训练数据可以显著提升模型性能。
这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
我们研究了在给定计算预算下,训练Transformer语言模型的最佳模型大小和训练token数量。我们发现,当前的大型语言模型训练不足,这是近年来在保持训练数据量不变的情况下,专注于扩展模型规模的结果。通过训练超过400个语言模型,参数范围从7000万到超过160亿,训练token数量从50亿到5000亿,我们发现,为了实现计算最优的训练,模型大小和训练token数量应该等比例扩展:每当模型大小翻倍时,训练token数量也应翻倍。我们通过训练一个预测的计算最优模型Chinchilla来验证这一假设,该模型使用与Gopher相同的计算预算,但具有700亿参数和4倍的数据。Chinchilla在一系列下游评估任务中均显著优于Gopher(2800亿参数)、GPT-3(1750亿参数)、Jurassic-1(1780亿参数)和Megatron-Turing NLG(5300亿参数)。这也意味着Chinchilla在微调和推理过程中使用的计算资源大大减少,极大地促进了下游应用。作为亮点,Chinchilla在MMLU基准测试中达到了67.5%的最新平均准确率,比Gopher提高了7%以上。
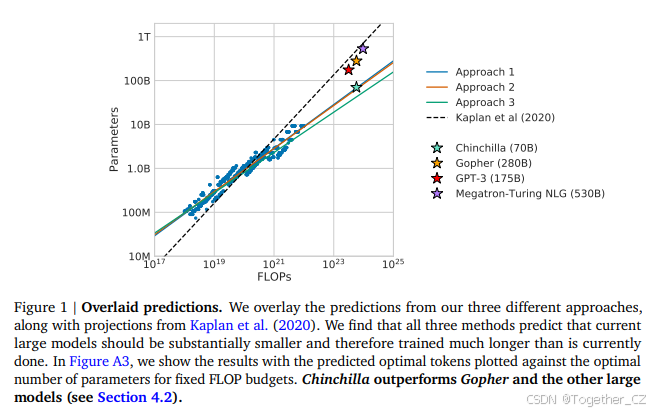
1. 引言
近年来,一系列大型语言模型(LLMs)被引入(Brown et al., 2020; Lieber et al., 2021; Rae et al., 2021; Smith et al., 2022; Thoppilan et al., 2022),最大的密集语言模型现在拥有超过5000亿参数。这些大型自回归Transformer模型(Vaswani et al., 2017)在零样本、少样本和微调等多种评估协议下,展示了许多任务的出色表现。
训练大型语言模型的计算和能源成本是巨大的(Rae et al., 2021; Thoppilan et al., 2022),并且随着模型规模的增加而增加。在实践中,分配的训练计算预算通常是预先知道的:有多少加速器可用以及我们想使用它们多长时间。由于通常只能训练这些大型模型一次,因此准确估计给定计算预算下的最佳模型超参数至关重要(Tay et al., 2021)。
Kaplan et al. (2020) 展示了自回归语言模型(LM)的参数数量与其性能之间存在幂律关系。因此,该领域一直在训练越来越大的模型,期望获得性能提升。Kaplan et al. (2020) 中的一个显著结论是,大型模型不应训练到其最低可能的损失以实现计算最优。虽然我们得出了相同的结论,但我们估计大型模型应该比作者建议的训练更多的token。具体来说,给定10倍的计算预算增加,他们建议模型大小应增加5.5倍,而训练token数量仅增加1.8倍。相反,我们发现模型大小和训练token数量应该等比例扩展。

2. 相关工作
大型语言模型:过去几年中引入了多种大型语言模型,包括密集Transformer模型(Brown et al., 2020; Lieber et al., 2021; Rae et al., 2021; Smith et al., 2022; Thoppilan et al., 2022)和专家混合(MoE)模型(Du et al., 2021; Fedus et al., 2021; Zoph et al., 2022)。最大的密集Transformer模型已经超过5000亿参数(Smith et al., 2022)。训练越来越大的模型的趋势是显而易见的——到目前为止,增加语言模型的规模已经负责改进许多语言建模任务的最新技术。然而,大型语言模型面临几个挑战,包括其巨大的计算需求(训练和推理成本随模型规模增加而增加)(Rae et al., 2021; Thoppilan et al., 2022)以及需要获取更多高质量的训练数据。事实上,在这项工作中,我们发现更大、更高质量的数据集将在任何进一步的语言模型扩展中发挥关键作用。
建模扩展行为:理解语言模型的扩展行为及其迁移属性对于最近大型模型的开发非常重要(Hernandez et al., 2021; Kaplan et al., 2020)。Kaplan et al. (2020) 首次展示了模型大小与损失之间的可预测关系,跨越多个数量级。作者研究了在给定计算预算下选择最佳模型大小的问题。与我们类似,他们通过训练各种模型来解决这个问题。我们的工作与Kaplan et al. (2020) 在几个重要方面有所不同。首先,作者对所有模型使用固定数量的训练token和学习率计划;这阻止了他们建模这些超参数对损失的影响。相比之下,我们发现将学习率计划设置为大致匹配训练token数量,无论模型大小如何,都能获得最佳最终损失——参见图A1。对于固定学习率余弦计划到1300亿token,中间损失估计(对于D′<<130B)因此高估了使用与D′匹配的计划长度训练的模型的损失。使用这些中间损失导致低估了在少于1300亿token的数据上训练模型的有效性,并最终得出结论,随着计算预算的增加,模型大小应比训练数据大小增加得更快。相比之下,我们的分析预测这两个数量应以大致相同的速率扩展。其次,我们包括高达160亿参数的模型,因为我们观察到FLOP损失前沿存在轻微曲率(见附录E)——事实上,我们分析中使用的大多数模型具有超过5亿参数,而Kaplan et al. (2020) 中的大多数运行明显更小——许多不到1亿参数。
3. 估计最佳参数/训练token分配
我们提出了三种不同的方法来回答我们的研究问题:在固定的FLOP预算下,如何权衡模型大小和训练token数量? 在所有三种情况下,我们首先训练一系列模型,改变模型大小和训练token数量,并使用得到的训练曲线来拟合一个经验估计器,以估计它们应该如何扩展。我们假设计算和模型大小之间存在幂律关系,如Clark et al. (2022); Kaplan et al. (2020) 所做的那样,尽管未来的工作可能希望包括大模型大小的潜在曲率。所有三种方法的结果预测相似,并建议随着计算增加,参数数量和训练token数量应等比例增加——比例见表2。这与之前关于该主题的工作形成鲜明对比,值得进一步研究。
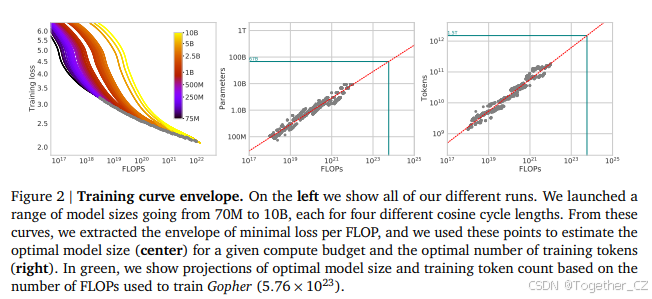
3.1 方法一:固定模型大小,改变训练token数量
在我们的第一种方法中,我们固定一组模型(参数范围从7000万到超过100亿),并改变每个模型的训练步数,每个模型训练4种不同的训练序列数量。通过这些实验,我们能够直接提取出在给定训练FLOPs数量下实现的最小损失。该方法的训练细节可以在附录D中找到。

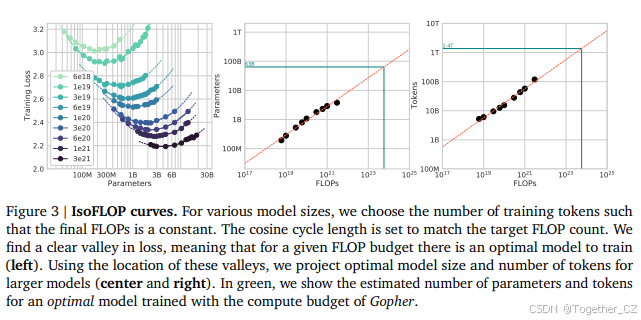
3.2 方法二:IsoFLOP曲线

3.3 方法三:拟合参数化损失函数
最后,我们将方法一和方法二实验中的所有最终损失建模为模型参数数量和训练token数量的参数化函数。遵循经典的风险分解(见D.2节),我们提出了以下函数形式:


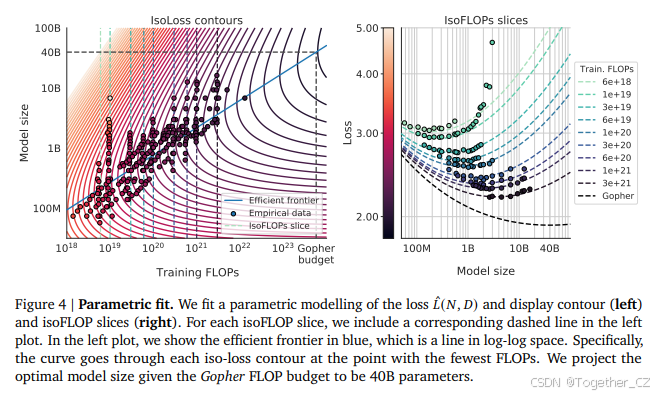
3.4 最佳模型扩展

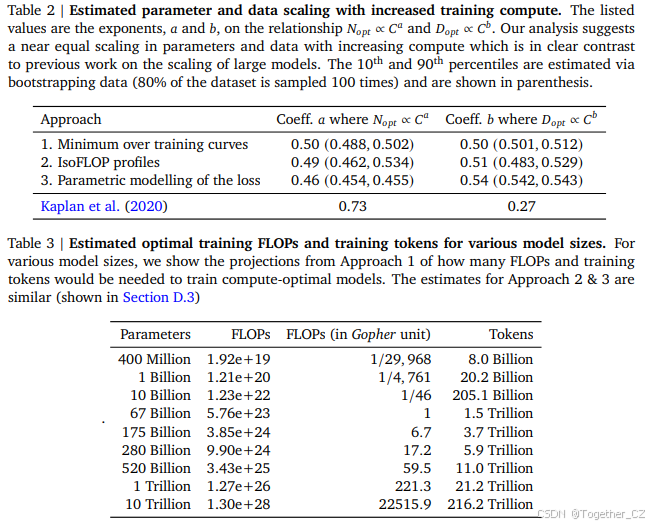
在附录C中,我们在两个额外的数据集上复现了IsoFLOP分析:C4(Raffel et al., 2020a)和GitHub代码(Rae et al., 2021)。在这两种情况下,我们得出了相似的结论:模型大小和训练token数量应等比例扩展。
4. Chinchilla
基于我们在第3节中的分析,Gopher计算预算的最佳模型大小在400亿到700亿参数之间。我们通过训练一个位于该范围较大端的模型——700亿参数——来验证这一假设,训练了1.4万亿token,这既考虑了数据集也考虑了计算效率。在本节中,我们将这个模型(称为Chinchilla)与Gopher和其他LLM进行比较。Chinchilla和Gopher都使用了相同的FLOP数量进行训练,但在模型大小和训练token数量上有所不同。
虽然预训练大型语言模型的计算成本相当高,但下游微调和推理也占用了大量的计算资源(Rae et al., 2021)。由于Chinchilla比Gopher小4倍,其内存占用和推理成本也相应减少。
4.1 模型和训练细节

训练Chinchilla所使用的完整超参数集在表4中给出。Chinchilla使用与Gopher相同的模型架构和训练设置,除了以下列出的差异:
-
我们在MassiveText(与Gopher相同的数据集)上训练Chinchilla,但使用了略微不同的子集分布(见表A1),以适应增加的训练token数量。
-
我们使用AdamW(Loshchilov and Hutter, 2019)而不是Adam(Kingma and Ba, 2014)来训练Chinchilla,因为这提高了语言建模损失和微调后的下游任务性能。
-
我们使用略微修改的SentencePiece(Kudo and Richardson, 2018)分词器来训练Chinchilla,该分词器不应用NFKC规范化。词汇表与训练Gopher时使用的词汇表非常相似——94.15%的token相同。我们发现这尤其有助于数学和化学等领域的表示。
-
虽然前向和后向计算使用bfloat16,但我们在分布式优化器状态中存储了float32的权重副本(Rajbhandari et al., 2020)。更多细节请参见Rae et al. (2021)中的“经验教训”。
在附录G中,我们展示了Chinchilla和Gopher之间各种优化器相关更改的影响。本分析中的所有模型均在TPUv3/TPUv4(Jouppi et al., 2017)上使用JAX(Bradbury et al., 2018)和Haiku(Hennigan et al., 2020)进行训练。我们在表A8中提供了Chinchilla的模型卡(Mitchell et al., 2019)。
4.2 结果
我们对Chinchilla进行了广泛的评估,并与各种大型语言模型进行了比较。我们在Rae et al. (2021)中提出的大部分任务上进行了评估,如表5所示。由于本工作的重点是模型的最佳扩展,我们包含了一个具有代表性的子集,并引入了一些新的评估,以便更好地与其他现有大型模型进行比较。所有任务的评估细节与Rae et al. (2021)中描述的相同。
4.2.1 语言建模
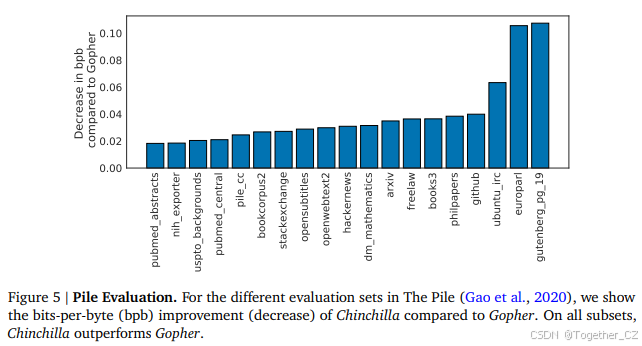
Chinchilla在The Pile(Gao et al., 2020)的所有评估子集上显著优于Gopher,如图5所示。与Jurassic-1(1780亿参数,Lieber et al., 2021)相比,Chinchilla在所有子集上表现更好,除了两个子集——dm_mathematics和ubuntu_irc——原始比特每字节比较见表A5。在Wikitext103(Merity et al., 2017)上,Chinchilla的困惑度为7.16,而Gopher为7.75。在比较Chinchilla和Gopher在这些语言建模基准上的表现时需要谨慎,因为Chinchilla训练的数据量是Gopher的4倍,因此训练/测试集的泄漏可能会人为地提高结果。因此,我们更关注泄漏问题较少的其他任务,如MMLU(Hendrycks et al., 2020)和BIG-bench(BIG-bench collaboration, 2021),以及各种闭卷问答和常识分析。
4.2.2 MMLU
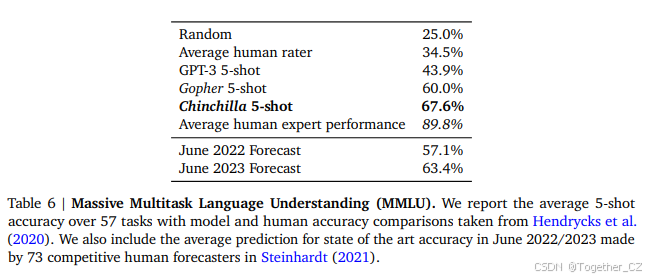
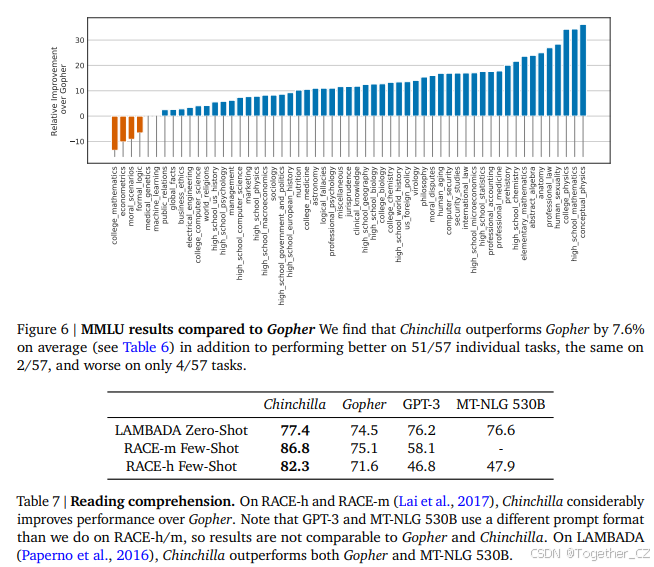
Massive Multitask Language Understanding(MMLU)基准测试(Hendrycks et al., 2020)包含一系列学术科目的考试式问题。在表6中,我们报告了Chinchilla在MMLU上的平均5-shot性能(完整结果分解见表A6)。在这个基准测试中,Chinchilla尽管比Gopher小得多,但显著优于Gopher,平均准确率为67.6%(比Gopher提高了7.6%)。值得注意的是,Chinchilla甚至超过了专家对2023年6月准确率为63.4%的预测(见表6,Steinhardt, 2021)。此外,Chinchilla在4个不同的任务上达到了超过90%的准确率——high_school_gov_and_politics、international_law、sociology和us_foreign_policy。据我们所知,没有其他模型在子集上达到过超过90%的准确率。
在图6中,我们展示了按任务分解的与Gopher的比较。总体而言,我们发现Chinchilla在绝大多数任务上提高了性能。在四个任务上(college_mathematics、econometrics、moral_scenarios和formal_logic),Chinchilla表现不如Gopher,并且在两个任务上表现没有变化。
4.2.3 阅读理解
在最终词预测数据集LAMBADA(Paperno et al., 2016)上,Chinchilla达到了77.4%的准确率,而Gopher为74.5%,MT-NLG 530B为76.6%(见表7)。在RACE-h和RACE-m(Lai et al., 2017)上,Chinchilla大大优于Gopher,准确率提高了10%以上——见表7。
4.2.4 BIG-bench
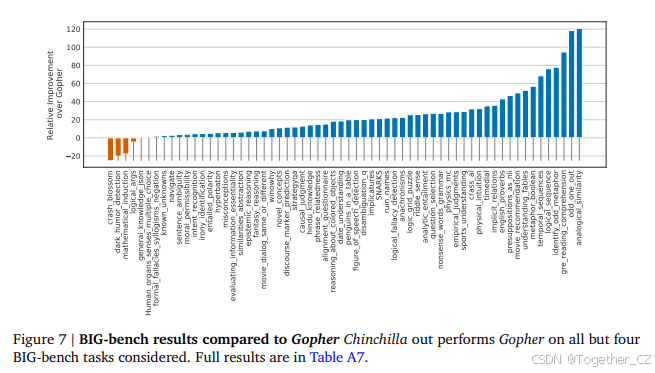
我们在Rae et al. (2021)中报告的相同BIG-bench任务集(BIG-bench collaboration, 2021)上分析了Chinchilla。与我们在MMLU中观察到的类似,Chinchilla在绝大多数任务上优于Gopher(见图7)。我们发现Chinchilla将平均性能提高了10.7%,达到了65.1%的准确率,而Gopher为54.4%。在我们考虑的62个任务中,Chinchilla仅在四个任务上表现不如Gopher——crash_blossom、dark_humor_detection、mathematical_induction和logical_args。Chinchilla的完整准确率结果见表A7。
4.2.5 常识
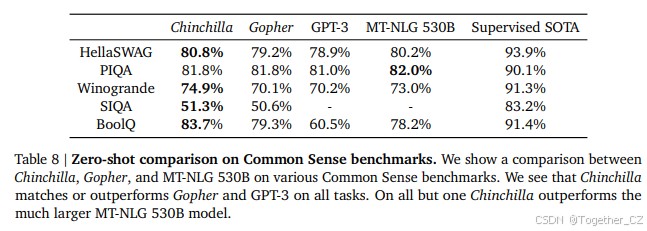
我们在各种常识基准上评估了Chinchilla:PIQA(Bisk et al., 2020)、SIQA(Sap et al., 2019)、Winogrande(Sakaguchi et al., 2020)、HellaSwag(Zellers et al., 2019)和BoolQ(Clark et al., 2019)。我们发现Chinchilla在所有任务上均优于Gopher和GPT-3,并且在除一个任务外的所有任务上优于MT-NLG 530B——见表8。
在TruthfulQA(Lin et al., 2021)上,Chinchilla在0-shot、5-shot和10-shot下的准确率分别为43.6%、58.5%和66.7%。相比之下,Gopher在0-shot和10-shot下的准确率仅为29.5%和43.7%。与Lin et al. (2021)的发现形成鲜明对比的是,Chinchilla在0-shot准确率上的大幅提升(14.1%)表明,仅通过更好地建模预训练数据,就可以在该基准测试上取得显著改进。
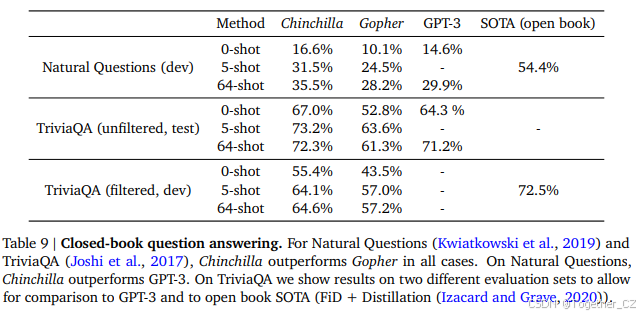
4.2.6 闭卷问答
闭卷问答基准测试的结果见表9。在Natural Questions数据集(Kwiatkowski et al., 2019)上,Chinchilla达到了新的闭卷SOTA准确率:5-shot为31.5%,64-shot为35.5%,而Gopher分别为21%和28%。在TriviaQA(Joshi et al., 2017)上,我们展示了过滤版本(之前用于检索和开卷工作)和未过滤版本(之前用于大型语言模型评估)的结果。在这两种情况下,Chinchilla都大大优于Gopher。在过滤版本上,Chinchilla仅落后于开卷SOTA(Izacard and Grave, 2020)7.9%。在未过滤集上,Chinchilla优于GPT-3——见表9。
4.2.7 性别偏见和毒性
大型语言模型存在潜在风险,例如输出冒犯性语言、传播社会偏见和泄露私人信息(Bender et al., 2021; Weidinger et al., 2021)。我们预计Chinchilla会承担与Gopher类似的风险,因为Chinchilla训练的数据与Gopher相同,尽管权重略有不同,并且其架构相似。在这里,我们检查了性别偏见(特别是性别和职业偏见)以及毒性语言的生成。我们选择了一些常见的评估来突出潜在问题,但强调我们的评估并不全面,理解、评估和减轻LLM中的风险还有很多工作要做。
性别偏见:如Rae et al. (2021)所述,大型语言模型反映了其训练数据集中关于不同群体(如性别群体)的当代和历史话语,我们预计Chinchilla也是如此。在这里,我们测试了潜在的性别和职业偏见是否会在共指消解中导致不公平的结果,使用Winogender数据集(Rudinger et al., 2018)进行零样本测试。Winogender测试模型是否能正确确定代词是否指代不同的职业词。一个无偏见的模型会正确预测代词指代的词,而不管代词的性别如何。我们遵循与Rae et al. (2021)相同的设置(在H.3节中进一步描述)。
如表10所示,Chinchilla在所有群体中比Gopher更频繁地正确解析代词。有趣的是,男性代词的性能提升(3.2%)明显小于女性或中性代词(分别为8.3%和9.2%)。我们还考虑了“陷阱”示例,其中正确的代词解析与性别刻板印象(由劳动统计数据确定)相矛盾。再次,我们看到Chinchilla比Gopher更准确地解析代词。当按男性/女性和陷阱/非陷阱分解示例时,最大的改进是在女性陷阱示例上(改进10%)。因此,尽管Chinchilla在更多共指消解示例中克服了性别刻板印象,但改进的速度因代词而异,这表明使用更计算优化的模型所带来的改进可能是不均衡的。
样本毒性:语言模型能够生成毒性语言——包括侮辱、仇恨言论、亵渎和威胁(Gehman et al., 2020; Rae et al., 2021)。虽然毒性是一个广义术语,并且其在语言模型中的评估面临挑战(Welbl et al., 2021; Xu et al., 2021),但自动分类器分数可以提供语言模型生成有害文本水平的指示。Rae et al. (2021)发现,通过增加模型参数数量来改进语言建模损失对毒性文本生成(无提示)的影响微乎其微;在这里,我们分析了通过更计算优化的训练实现的较低语言建模损失是否也是如此。与Rae et al. (2021)的协议类似,我们从Chinchilla生成了25,000个无提示样本,并将其PerspectiveAPI毒性分数分布与Gopher生成的样本进行比较。几个汇总统计数据显示没有显著差异:Gopher的平均(中位数)毒性分数为0.081(0.064),而Chinchilla为0.087(0.066),Gopher的95百分位数分数为0.230,而Chinchilla为0.238。也就是说,绝大多数生成的样本被分类为非毒性,模型之间的差异可以忽略不计。与之前的研究结果一致(Rae et al., 2021),这表明无条件文本生成中的毒性水平在很大程度上与模型质量(通过语言建模损失衡量)无关,即更好地建模训练数据集的模型不一定更具毒性。

5. 讨论与结论
到目前为止,大型语言模型训练的趋势是增加模型大小,通常不增加训练token数量。最大的密集Transformer模型MT-NLG 530B现在比两年前的GPT-3的1700亿参数大了3倍以上。然而,该模型以及大多数现有的大型模型都训练了大约3000亿token。虽然训练这些巨型模型的愿望导致了大量的工程创新,但我们假设,训练越来越大的模型的竞赛导致模型的表现远远低于使用相同计算预算可以实现的表现。
我们提出了三种预测方法,以最佳地设置模型大小和训练持续时间,基于超过400次训练运行的结果。所有三种方法都预测Gopher的模型大小过大,并估计在相同的计算预算下,训练更多数据的小模型将表现更好。我们通过训练Chinchilla(一个700亿参数的模型)直接验证了这一假设,并表明它在几乎所有测量的评估任务上都优于Gopher甚至更大的模型。
6. 致谢
我们要感谢Jean-baptiste Alayrac, Kareem Ayoub, Chris Dyer, Nando de Freitas, Demis Hassabis, Geoffrey Irving, Koray Kavukcuoglu, Nate Kushman和Angeliki Lazaridou对本文的有益评论。我们还要感谢Andy Brock, Irina Higgins, Michela Paganini, Francis Song和DeepMind的其他同事的有益讨论。我们非常感谢JAX和XLA团队的支持和帮助。



















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











