






22年12月DeepMind在NeurIPS发表的论文“Training Compute-Optimal Large Language Models“,阐述如何在给定计算资源条件下,用多少tokens训练最优大小的大语言模型(LLM)。
其研究在给定的计算预算下训练一个Transformer语言模型的最佳大小和token数量。发现大语言模型训练严重不足,这是最近关注于规模化语言模型同时保持训练数据量不变的结果。DeepMind训练用不同规模的数据 (从5B到500B tokens) 训练超过400个不同大小的模型 (从70M到超过16B),发现模型和训练数据规模需要同比增大。根据这个假设,使用与 Gopher (280B) 同样的计算量且4倍的数据,训练了70B的最优模型 Chinchilla。它在许多下游任务上的性能显著超过了 Gopher (280B), GPT-3 (175B) Jurassic-1 (178B) 和 Megatron-Turing NLG (530B)。这也意味着Chinchilla在微调和推理方面使用的计算量大大减少,极大地促进了下游的使用。作为一个亮点,Chinchilla在MMLU基准上达到了67.5%的平均准确率,比Gopher提高了7%以上。
了解语言模型的规模化行为及其迁移特性在最近大模型的开发中非常重要(Hernandez2021;Kaplan2020)。(Kaplan2020)首次显示了模型大小和损失之间在许多数量级呈现的可预测关系。其研究了在给定的计算预算下选择最佳模型大小进行训练的问题。类似地,其通过训练各种模型来解决这个问题。
OpenAI(Kaplan2020)的大语言模型规模化定律(scaling law)和本文工作在几个重要方面是不同的。
首先,前者对所有模型使用固定数量的训练tokens和学习率时间表;这使他们无法对这些超参数在损失的影响进行建模。相反,无论模型大小如何,将学习率时间表设置为与训练tokens的数量大致匹配都会得到最佳的最终损失。对于130B token固定学习率余弦的调度措施,中间损失估计(D′ << 130B)因此高估了用调度长度匹配训练的模型损失D′。使用这些中间损失导致低估了在少于130B个tokens的数据上训练模型的有效性,并最终得出结论,即随计算预算的增加,模型大小应该比训练数据大小增长得更快。相反,本文的分析预测,这两个数量的比例应该大致相同。
其次,本文包括了参数高达16B的模型,因为FLOP损失边界有轻微的弯曲——事实上,使用的大多数模型都有超过5亿个参数,而(Kaplan2020)中的大多数模型都要小得多——许多参数小于100M。
最近,(Clark2022)专门研究了专家混合语言模型的规模化特性,表明随着模型大小的增加,专家数量的规模化会减少——他们的方法将损失建模为两个变量的函数:模型大小和专家数量。然而,该分析是用固定数量的训练tokens进行的,如(Kaplan2020)所述,其可能低估了分支的改进。
如图叠加了三种不同方法的预测,以及(Kaplan2020)的预测。这三种方法都预测,目前的大模型应该比小得多才对,因此训练的时间要长得多。
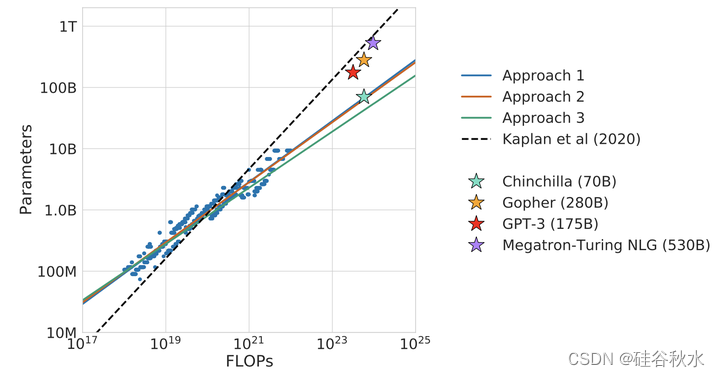
如图显示了预测的最佳tokens相对于固定FLOP预算的最佳参数数量的结果。Chinchilla的性能优于Gopher和其他大模型。对于固定的FLOP预算,其显示方法1、2和3预测的tokens和参数的最佳数量。
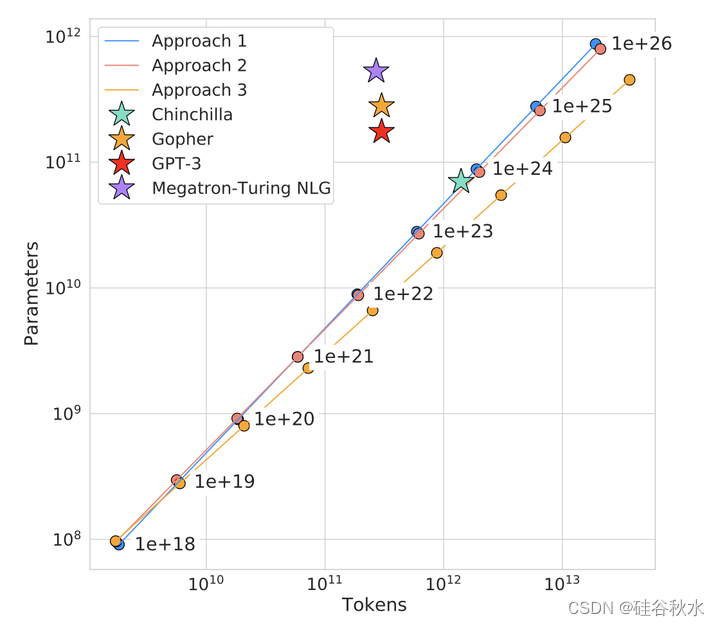
基于估计的计算最优边界,可以预测,对于用于训练Gopher的计算预算,最优模型应该小4倍,同时在多4倍的tokens上训练。通过在1.4万亿token上训练一个更具计算优化性的70B模型Chinchilla来验证这一点。Chinchilla不仅优于其大得多的同类模型Gopher,而且其缩小的模型大小大大降低了推理成本,并大大方便了在较小硬件上的下游使用。大语言模型的能量成本通过其用于推理和微调的成本来摊销。因此,经过优化训练的较小模型的好处,超出了其性能改进的直接好处。
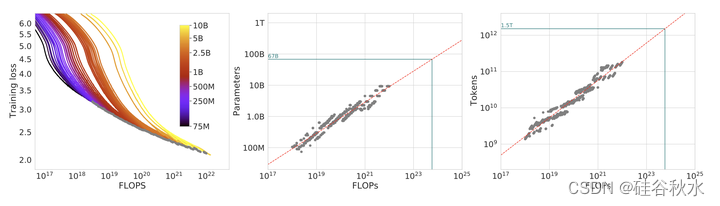
如图是训练曲线包络。左图展示了所有不同的运行方式。推出了一系列模型,尺寸从70M到10B不等,每个模型有四个不同的余弦周期长度。从这些曲线中,提取了每个FLOP的最小损失包络,并用这些点来估计给定计算预算的最佳模型大小(中图)和训练tokens的最佳数量(右图)。绿色线显示了基于训练Gopher的FLOP数量(5.76×10^23)的最佳模型大小和训练tokens计数的预测。
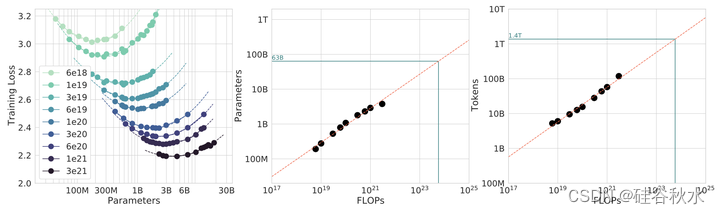
如图是IsoFLOP曲线。对于各种模型大小,选择训练tokens的数量,使得最终FLOP是常数。余弦周期长度设置与目标FLOP计数相匹配。有一个明显的损失凹坑,这意味着对给定的FLOP预算,有一个最佳模型需要训练(左图)。利用这些凹坑的位置,为更大的模型(中图和右图)预测最佳模型大小和tokens数量。绿色线显示用Gopher的计算预算去训练的最优模型参数和tokens估计数量。
如图是参数化拟合。拟合损失的参数模型𝐿2.6.1(𝑁, 𝐷) ,显示轮廓(左)和isoFLOP切片(右)。对于每个isoFLOP切片,在左图中对应一条相应的虚线。左图中用蓝色显示了有效边界,这是对数-对数空间中的一条线。具体来说,曲线在FLOPS最少的点穿过每个iso-loss轮廓。在Gopher FLOP预算为40B参数的情况下,预测了最佳模型大小。
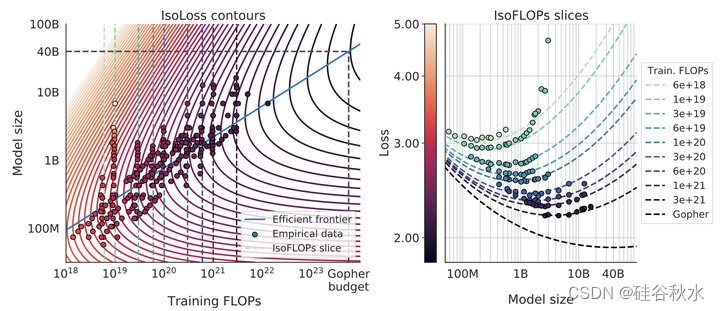
基于上述分析,Gopher (280B) 模型的最优大小应该在 40B ~ 70B 之间。出于数据集和计算效率的考虑,通过在1.4Ttoken(70B参数)上训练模型来检验这一假设。于是按模型大小的上限 70B 用 1.4T tokens 训练了模型 Chinchilla,在多个下游任务上的性能都超过了 Gopher。
Chinchilla和Gopher都接受了相同数量FLOP的训练,但模型的大小和训练tokens的数量不同。虽然预训练大型语言模型需要相当大的计算成本,但下游的微调和推理也会占用大量的计算量(Rae2021)。由于比Gopher小4倍,Chinchilla的内存占用和推理成本也更小。

















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









