



 本文详细解读了Transformer模型中的关键组件,如自注意力机制、多头注意力、位置编码和mask,以及编码器和解码器的工作原理,包括残差连接和softmax用于生成预测。
本文详细解读了Transformer模型中的关键组件,如自注意力机制、多头注意力、位置编码和mask,以及编码器和解码器的工作原理,包括残差连接和softmax用于生成预测。
参考:https://zhuanlan.zhihu.com/p/105493618
参考:《Attention is all you need》
前情说明
论文中每个嵌入和编码器输入/输出矢量的大小均为512,图中是4。
新向量的维数小于词嵌入向量的维数,在论文中,它们的维数为64,图中是3。
Transformer使用八个head,六个encoder-decoder。
图中输入数据x个数是2个。
Transform
总框架

输入
-
Embeddings
-
Position-Encoding
以上那些都没考虑到位置的顺序问题,也就是无序的,加入Position-Encoding就考虑到了词的顺序问题。

self-attention
- 与attention区别
QKV同源,且QKV是用WqWkWv得到。
- self-attention细节
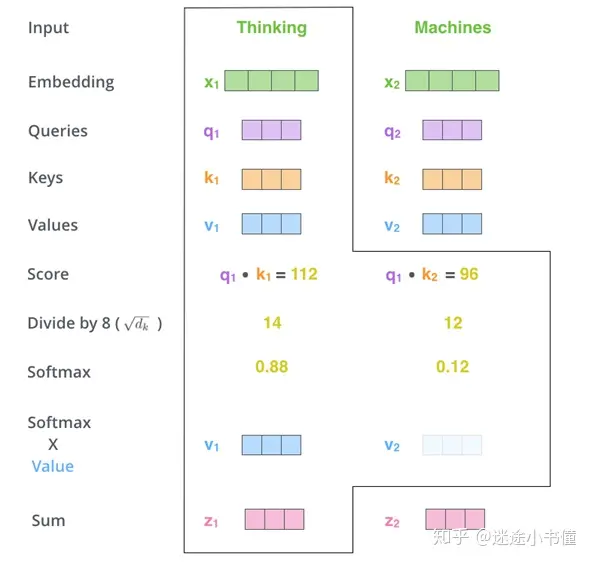
第一步:得到QKV
例如下图, x1*Wq 得到 q1,由此,最终为输入句子中的每个单词创建QKV。 由于Wq, Wk, 和Wv是分别初始化的,所以得到的三个向量(q1, k1, v1)不一定是相同的。


第二步:计算Scores
scores为该单词和输入句子的每个单词的“语义关联度”,分数决定了当我们对某个位置的单词进行编码时,将注意力集中在输入句子的其他部分上的程度。
如下图, scores=Q*K。

第三步:归一化 softmax(scores)
先将scores除以维度(d_k)的平方根,使用sqrt(d_k)来防止过大的得分。然后通过softmax操作传递结果。Softmax对分数进行归一化,因此所有分数均为正,加起来为1。
这个softmax分数(exp(14)/(exp(14)+exp(12))=0.88, exp(12)/(exp(14)+exp(12))=0.12)决定了每个单词在当前位置(例如,Thinking在句子”Thinking Machines”中所在的位置)要表达多少。

第四步:v*softmax(scores)
直觉是保持我们要关注的单词的值(向量表示)的完整性,并淹没无关的单词(例如,将它们乘以0.001之类的小数字)。
第五步:对加权值向量求和
注意,encoder的部分,是上下文;decoder的部分,只有上文,没有下文。
总的来说就是以下公式

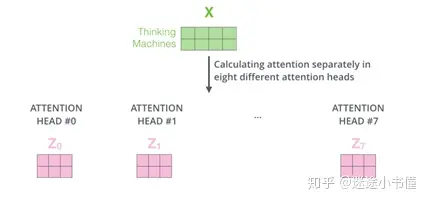
- multi-head-attention
其一,它扩展了模型专注于不同位置的能力。其二,它为注意力层提供了多个“表示子空间”。
注意,每个头维护单独的Q / K / V权重矩阵。

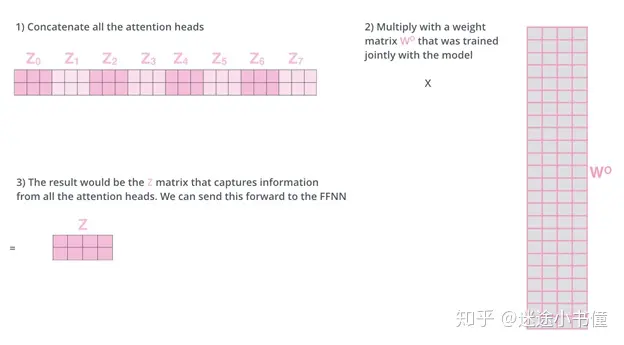
前馈层(feed forward sublayer)不期望有八个矩阵-它期望一个矩阵(每个单词一个向量)。因此,我们需要一种将这八个矩阵合并为单个矩阵的方法。我们合并矩阵,然后将它们乘以一个权重矩阵WO。
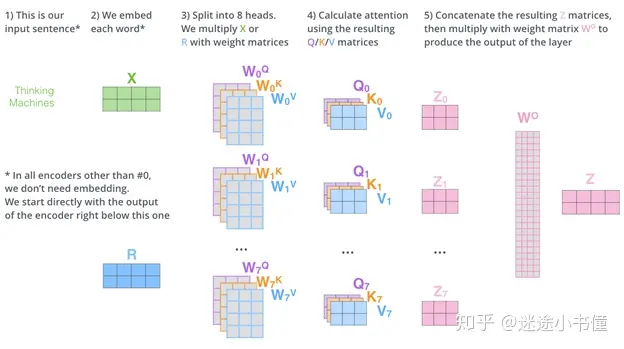
总的来说是下图。
self-attention是得到一个23的z,mutil-attentin是得到8个23的z,串联起来就是224的一个大z,再利用Wo(244)得到最终的z(2*4)。
残差+归一化
每个/层编码器中的每个子层在其周围都有残差连接,然后进行层归一化(layer normalization)步骤。
注意encoder和decoder残差连接的地方和不同。


Encoder
encoder由两个子层组成,分别是self-attention+feed forward,再加上个残差连接和归一化,上面已经介绍完了。
Decoder
encoder介绍得差不多,现在看看decoder和它的区别。一个是encoder-decoder attention层,一个是mask。

decoder有三个子层,其中多出来的encoder-decoder attention层可以帮助解码器将注意力集中在输入语句的相关部分,连接了encoder和decoder。
Mask相当于一个矩阵:[[1, 0, 0], [1, 1, 0], [1, 1, 1]]。也就是说:当预测t4的时候,只有t1可见;当预测t2的时候,只有t1和t4可见;当预测t1的时候,只有t1, t4, 和t2可见。这样的话,预测出来的序列,t4?, t2?, t1?就会进一步和事先知道的target序列的reference, t4, t2, t1进行对比,计算loss,并使用SGD/Adam等方法进行反向传播来更新transformer中的参数。

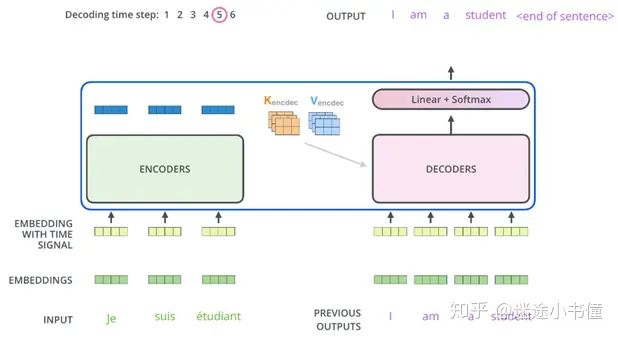
训练过程
编码器首先处理输入序列。然后,顶部/顶层编码器的输出转换为注意力向量K和V的集合。每个解码器decoder将在其“编码器-解码器注意力层”(Encoder-Decoder Attention layer)中使用它们,这有助于解码器将注意力集中在输入序列中的适当位置。

解码第一步:编码完成,trg第一位已知,开始解码第二位。例如给定src = [[1,4,2,1], [1,4,4,4]] 和 trg = [[1], [1]] (每个序列的第一个词”1”可以看成s即start-of-sentence填充符号,Target序列的第一个单词,s是事先给定的。)通过神经网络transformer得到trg=[[1, 4?], [1, 4?]],这里给4打问号,是因为实际预测到的不一定是4,如果不是4,产生loss,计算loss,并反向传播。
开始解码的开始状态(假设现在是基于训练好的模型的“测试阶段”),编码器ENCODER端已经运行完毕,得到了source memory。解码器这边,最初只有一个s,作为句子的开始,对该词进行encode,然后参考来自ENCODER部分的memory, K, V来分别计算multi-head attention + feed forward,最后得到一个向量,对该向量进行linear + softmax,就是下一个词,例如4。
解码器工作的第二步:根据已有的计算好的source memory和当前可用的target sequence来继续对下一个词预测。第二步,我们把得到的1,4作为target sequence,扔给DECODER,其内部也同样参考已有的ENCODER的memory, K and K,来得到一个新的矩阵,我们取该矩阵的最后一行,扔给linear+softmax就得到下一个词,假设为2。
解码器工作的第三步:重复上一步,直到解码完成,也就相当于“训练”结束。当然,训练阶段,不是分成三步,而是基于mask,一步搞定的。
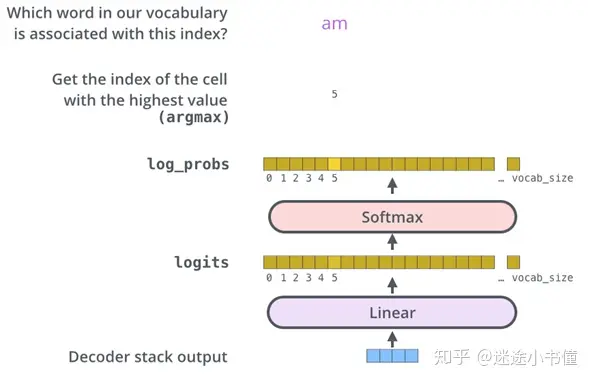
输出
利用线性层和其后的Softmax层将解码器输出的浮点数向量变为一个词。
线性层是一个简单的全连接的神经网络,它将解码器堆栈产生的向量投影到一个更大的向量中,称为logits向量。(类似于one-hot-alike表示,只不过one-hot的是一个位置为1,其他位置都为0;而logits是一个位置的概率得分最大,其他的位置的值可以非0)
假设我们的模型从其学习的训练数据集中知道有10,000个去冗余后的英语单词(我们模型的“目标语言的词汇表”)。这将使logits向量的宽度变为10,000个单元-每个单元对应一个单词的分数。这就是我们对线性层模型输出的解释。
然后,softmax层将这些分数转换为概率(全部为正,全部相加为1.0)。选择具有最高概率的单元,并且与此单元对应的单词将作为该时间步的输出。

















 563
563




 到【灌水乐园】发言
到【灌水乐园】发言







