



一、offline RL离线强化学习
不与环境交互,仅使用预先收集的固定数据集进行学习。
训练时不能通过探索来收集新数据,策略更新只能基于已有的数据。
二、online RL在线强化学习
智能体(agent)与环境(environment)进行交互,不断收集新数据,并基于新的数据进行学习和策略更新。
训练过程中,策略会不断变化,探索(exploration)和利用(exploitation)同时进行。
三、一张图便可清晰的了解两者区别
论文题目:AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
作者:Ashvin Nair , Abhishek Gupta , Murtaza Dalal, Sergey Levine
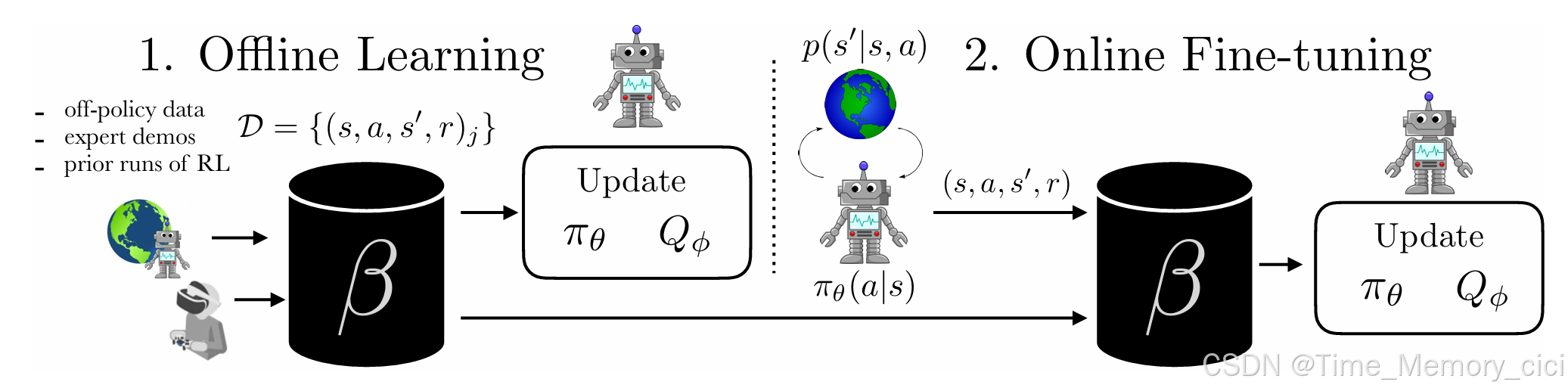
Figure 2: We study learning policies by offline learning on a prior dataset D and then fine-tuning with online interaction. The prior data could be obtained via prior runs of RL, expert demonstrations, or any other source of transitions. Our method, advantage weighted actor critic (AWAC) is able to learn effectively from offline data and fine-tune in order to reach expert-level performance after collecting a limited amount of interaction data. Videos and data are available at awacrl.github.io
总之,使用已有数据集,不与环境交互就是offline RL,这里的已有数据集可以是off-policy data、expert demos,也可以是prior runs of RL产生的数据。
四、补充材料
知乎上有一篇关于离线强化学习的文章,我觉得写的非常清晰,感兴趣的可以看下。


















 3782
3782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









