



 本文介绍了机器学习中的三大主要任务:回归、分类和无监督学习,并通过Python的sklearn库中的波士顿房价数据集和鸢尾花数据集进行演示。重点讲解了有监督学习中的回归和分类问题。
本文介绍了机器学习中的三大主要任务:回归、分类和无监督学习,并通过Python的sklearn库中的波士顿房价数据集和鸢尾花数据集进行演示。重点讲解了有监督学习中的回归和分类问题。
- 这篇博文是DataWhale集成学习【上】的第一部分,主要是介绍机器学习的三大主要任务
- 参考资料为DataWhale开源项目:机器学习集成学习与模型融合(基于python)和scikit-learn官网
- 学习交流欢迎联系 obito0401@163.com
任务一:回归
- 回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,是机器学习中有监督学习的一个重要组成部分,在预测模型中多有应用
- 回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析
【例】下面以Python的 sklearn 库中内置的波士顿房价数据集 boston 做一个演示
- 自变量:data,特征x的矩阵(ndarray)
- 因变量:target,因变量y的向量(ndarray)
- 特征名称:target_names,自变量x的含义(ndarray)
import pandas as pd
from sklearn import datasets
import matplotlib.pyplot as plt
import seaborn as sns
# 加载原始数据集并做进一步处理
boston = datasets.load_boston() # 返回一个包含data、target和feature_names的字典
x = boston.data # 划分出自变量
y = boston.target # 划分出因变量
features = boston.feature_names # 划分出特征名
boston_data = pd.DataFrame(x,columns=features) # 自变量加上特征名
boston_data["Price"] = y # 添加因变量列
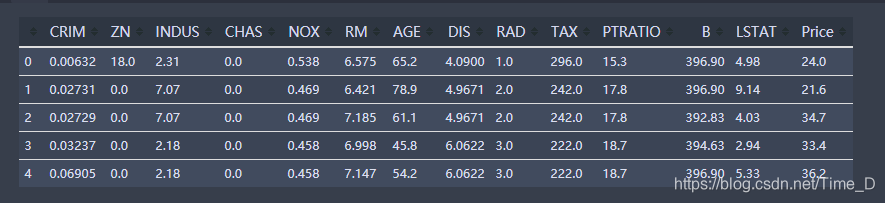
boston_data.head() # 展示所构造的最终数据集的头部信息
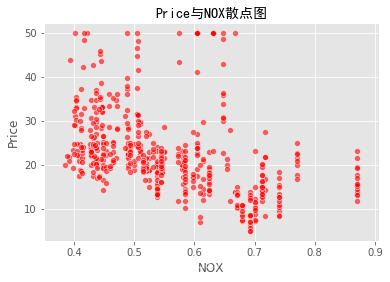
# 画出自变量和因变量的散点图,观察其关系
sns.scatterplot(boston_data['NOX'],boston_data['Price'],color="r",alpha=0.6)
plt.title("Price与NOX散点图",fontproperties = 'SimHei',fontsize = 14)
plt.show()
任务二:分类
- 分类问题是数据挖掘处理的一个重要组成部分,在机器学习领域,分类问题通常被认为属于有监督学习,也就是说,分类问题的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类
- 根据类别的数量还可以进一步将分类问题划分为二元分类(binary classification)和多元分类(multiclass classification)
【例】下面以Python的 sklearn 库中内置的鸢尾花数据集 iris 做一个演示
- 特征:data,特征x的矩阵(ndarray)
- 类:target,类y的向量(ndarray)
- 特征名称:target_names,特征x的含义(ndarray)
import pandas as pd
from sklearn import datasets
import matplotlib as plt
# 加载原始数据集并做进一步处理
iris = datasets.load_iris()
x = iris.data
y = iris.target
features = iris.feature_names
iris_data = pd.DataFrame(x,columns=features)
iris_data['target'] = y
iris_data.head()

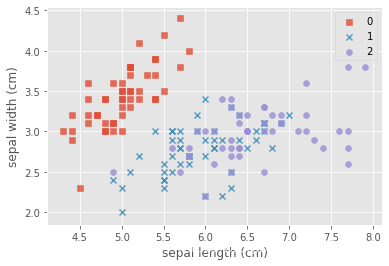
# 可视化数据分布特征
marker = ['s','x','o'] # 符号标记
for index,c in enumerate(np.unique(y)):
plt.scatter(x=iris_data.loc[y==c,"sepal length (cm)"],y=iris_data.loc[y==c,"sepal width (cm)"],
alpha=0.8,label=c,marker=marker[c])
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.legend()
plt.show()
任务三:无监督学习
- 上述两类任务:回归和分类是有监督学习的经典任务,而机器学习的另一大任务就是无监督学习
- 无监督学习并不需要标签,也就是所谓的因变量(或者类),它是从数据中去自动的提取信息,最常见的经典任务就是聚类
- 在本次组队学习中,重点学习回归和分类的集成学习的问题,因此不再介绍关于无监督学习的部分

















 5755
5755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









