 机器学习三大任务:集成学习Ensemble Learning概览
机器学习三大任务:集成学习Ensemble Learning概览





 本文介绍了机器学习的三大任务:监督学习(包括回归和分类)、无监督学习和强化学习。通过scikit-learn库中的波士顿房价数据集和鸢尾花数据集举例说明,强调了回归预测价格、分类决策和无监督学习发现模式的重要性。
本文介绍了机器学习的三大任务:监督学习(包括回归和分类)、无监督学习和强化学习。通过scikit-learn库中的波士顿房价数据集和鸢尾花数据集举例说明,强调了回归预测价格、分类决策和无监督学习发现模式的重要性。
概述
这次参加集成学习的组对学习,加油加油~ 距离上次系统地学机器学习已经大半年了,好多基础知识都忘得差不多了。正好趁这次再回顾一下,也可以复习一下python里面的一些库的使用方法。
在一般情况下,用xik 表示特征数据,大写X表示特征x的向量矩阵。对于特征,都用x(k) 表示,而样本用xi 表示。
e.g. 第1个样本的第2个特征为x12 ,第5个样本的第3个特征为x53
监督学习
回归
监督学习中的回归,可以看做是一个线性问题。
回归的一个很典型的例子就是波士顿房价,这是sklearn库中自带的很多数据集中的一个。不得不感叹这个库是真的挺强大的。
from sklearn import datasets
boston = datasets.load_boston() # 波士顿房价数据集,返回一个类似于字典的类
X = boston.data # 特征X的向量矩阵,数据类型为
y = boston.target # 因变量(房价)的向量
features = boston.feature_names
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y
boston_data.head()
【scikit-learn官方文档给的返回参数】
data :ndarray of shape (506, 13)
数据矩阵
target:ndarray of shape (506, )
回归的目标
filename:str
The physical location of boston csv dataset.
feature_names:ndarray
The names of features
~~ndarray是Numpy的N维数组对象
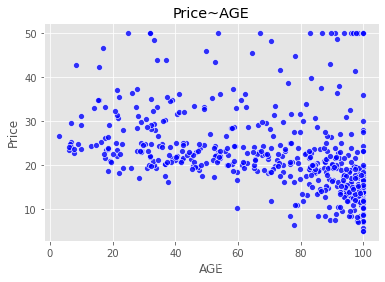
按照数据集画图如下
sns.scatterplot(boston_data['AGE'],boston_data['Price'],color="b",alpha=0.8) # 点图,一定要输入X,和y,才会有图出来,后面都是可设置的参数
plt.title("Price~AGE")
plt.show()
分类
分类可以看做一个多元化问题,做的是判断,非黑即白。
依然是sklearn自带的数据集,是通过鸢尾花的 花瓣大小 和花萼大小 间的关系来判断它是哪个品种。
from sklearn import datasets
iris = datasets.load_iris( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









