




本文原创,若引用,请注明
毫无疑问,社交媒体情感分类已成为自然语言处理的重要课题。对于这个问题,了解如何细致得进行数据预处理,如何设计特征,如何用传统模型和深度模型进行处理,其性能又是如何,是非常重要的。本文希望在这方面给感兴趣的同学提供参考。文章以 Twitter 推文为数据源,比较了传统方法(MaxEnt、SVM)、深度学习方法(LSTM)以及基于 Transformer 的 BERT 模型。在实验中,我们不仅进行了社交媒体文本特征的专门预处理,还探索了 TF-IDF、VADER、GloVe 词向量与注意力机制等多种特征增强方式。最终结果显示,BERT 在整体表现最佳,而 LSTM 在轻量化部署场景中更具优势。
1. 引言
将推文整体情感分类为积极、消极或中立的任务,是SemEval竞赛任务4中子任务A的核心内容。本报告展示了两种传统分类器(最大熵法和支持向量机),以及基于循环神经网络架构的LSTM分类器和基于Transformer框架的BERT分类器。同时概述了数据预处理、特征构建及分类器调优涉及的技术细节。
在实验设计方面,本报告中的所有模型均使用相同的训练集(训练数据集和开发数据集)进行训练。评估指标包括宏观平均F1值和混淆矩阵,用于比较模型在推特数据集上的稳定性和泛化能力。测试数据集从test1.txt到twitter-test3.txt。在三组测试数据(Test1、Test2和Test3)的F1得分中,BERT表现最佳,得分分别为0.708、0.719和0.679。LSTM分类器紧随其后,得分分别为0.675、0.672和0.604。在传统分类器中,MaxEnt表现更优,在三个测试集上达到的F1分数分别为0.623、0.617和0.606。
此外,由于深度学习模型固有的随机性——例如权重初始化、dropout机制、训练轮数、Adam优化器及GPU执行等因素——LSTM与BERT的运行结果可能存在差异。所报告的结果可视为其在多次运行中表现的代表性体现,并可作为有用的参考依据。
2. 技术细节与结果评估
2.1 数据预处理
本任务中的文本源自推特推文。鉴于此类文本具有表情符号、话题标签及网络俚语(包括缩写)等独特特征,相较于统一规范化处理,合理处理这些特征对传统情感分类模型更为有利。多轮测试还表明,该方法能提升模型的泛化能力。
具体来说,使用 emoji 库将表情符号转化为文字,例如 😂 转化为 “face with tears of joy”。话题标签保留并加上自定义前缀,例如 #fail 转换为 “hashtag fail”。此外,还构建了一个社交媒体缩写词典,用于尽可能保留网络俚语和语义信息。例如:
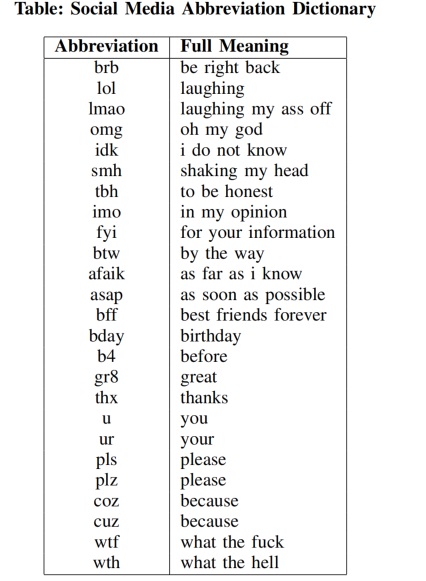
图表1:社交媒体缩略词典的示例
同时定义了 preprocess_tweet_advanced 函数进行文本标准化(如图2所示):

图表2:文本预处理的标准化函数
2.2 传统分类器:MaxEnt 与 SVM
报告对三组测试集进行了评估,基于混淆矩阵中观察到的错误模式,进行了针对性迭代。最终采用结合TF-IDF和VADER的特征管道开发了MaxEnt与SVM分类器。通过网格搜索对各模型进行调优以选取最优超参数。选定参数及其对应性能如下:
-
MaxEnt
- 最佳参数:C=10,ngram=(1,2),max_df=0.9,min_df=1
- 平均 F1:0.6153(三个测试集:0.623 / 0.617 / 0.606)
-
SVM
- 最佳参数:C=1,ngram=(1,2),max_df=1.0,min_df=1
- 平均 F1:0.6046(三个测试集:0.615 / 0.607 / 0.592)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 13
13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









