







1.为什么离职?
2.项目介绍
3.面试问题
(1)算法
-
手写代码快速排序算法
(2)Linux
-
统计文件有多少行?
[docker@MiWiFi-R4A-srv opt]$ sudo vim test.log
[docker@MiWiFi-R4A-srv opt]$ wc -l test.log
2 test.log
[docker@MiWiFi-R4A-srv opt]$ cat test.log |wc -l
2(3)Spark
-
讲一下你对RDD的理解,RDD有什么特性?
对RDD的理解:弹性分布式数据集(Resiliennt Distributed Datasets,RDD)
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
图 1 展示了 RDD 的分区及分区与工作结点(Worker Node)的分布关系。
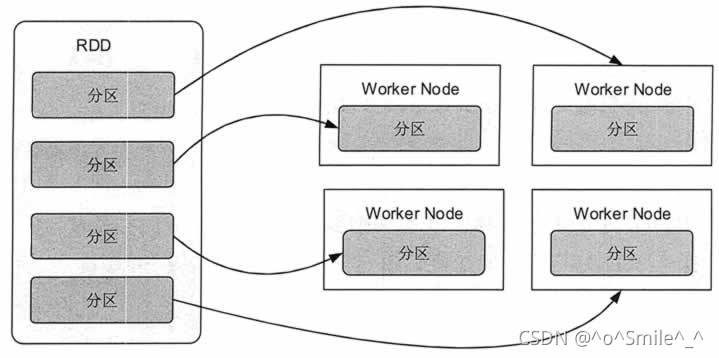
RDD分区及分区与工作节点的分布关系
图 1 RDD 分区及分区与工作节点的分布关系
RDD 具有容错机制,并且只读不能修改,可以执行确定的转换操作创建新的 RDD。具体来讲,RDD 具有以下几个属性。
只读:不能修改,只能通过转换操作生成新的 RDD。
分布式:可以分布在多台机器上进行并行处理。
弹性:计算过程中内存不够时它会和磁盘进行数据交换。
基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
RDD 实质上是一种更为通用的迭代并行计算框架,用户可以显示控制计算的中间结果,然后将其自由运用于之后的计算。
在大数据实际应用开发中存在许多迭代算法,如机器学习、图算法等,和交互式数据挖掘工具。这些应用场景的共同之处是在不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。
RDD 正是为了满足这种需求而设计的。虽然 MapReduce 具有自动容错、负载平衡和可拓展性的优点,但是其最大的缺点是采用非循环式的数据流模型,使得在迭代计算时要进行大量的磁盘 I/O 操作。
通过使用 RDD,用户不必担心底层数据的分布式特性,只需要将具体的应用逻辑表达为一系列转换处理,就可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 I/O 和数据序列化的开销。
特性:
1.A list of partitions
RDD是一个由多个partition(某个节点里的某一片连续的数据)组成的的list;将数据加载为RDD时,一般会遵循数据的本地性(一般一个hdfs里的block会加载为一个partition)。
2.A function for computing each split
一个函数计算每一个分片,RDD的每个partition上面都会有function,也就是函数应用,其作用是实现RDD之间partition的转换。
3.A list of dependencies on other RDDs
RDD会记录它的依赖 ,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作时出错或丢失会进行重算。
4.Optionally,a Partitioner for Key-value RDDs
可选项,如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区,例如这里自定义的Partitioner是基于key进行分区,那则会将不同RDD里面的相同key的数据放到同一个partition里面
5.Optionally, a list of preferred locations to compute each split on
最优的位置去计算,也就是数据的本地性。
-
spark为什么使用RDD?RDD原理?
Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。
参考博客:深入理解Spark RDD——为什么需要RDD?_beliefer的博客-优快云博客
-
spark数据倾斜如何处理?
定位原因与出现的问题的位置:根据log定位,出现数据倾斜的原因基本只可能发生了shuffle操作,在shuffle的过程中出现了数据倾斜问题。
解决办法:聚合源数据、过滤导致倾斜的key、提高shuffle操作reduce的并行度、使用随机key实现双重聚合、将reduce join 转换为map join、sample采样倾斜key进行两次join、使用随机数以及扩容表进行join。
-
怎么减少shuffle操作?
在spark中在使用groupByKey、reduceByKey、countByKey、join等容易发生shuffle。
-
作业提交流程
Spark:作业提交流程以及提交方式_ihooger的博客-优快云博客_spark作业提交流程
-
宽依赖和窄依赖
Spark中的宽依赖和窄依赖_荒野雄兵的专栏-优快云博客_spark的宽依赖和窄依赖
(4)Hadoop
-
如何搭建Hadoop HA高可用集群
Hadoop HA 高可用集群的搭建 - starzy - 博客园
(5)Kafka
-
kafka分区策略
-
如何保障kafka数据的准确性
大数据面试题:Kafka 如何保证数据可靠性和一致性_看朱成碧_的博客-优快云博客_kafka可靠性
(6)Zookeeper
-
如何保障数据的一致性
- ZooKeeper 如何保证数据一致性 - sw_kong - 博客园
-
zk有什么功能?
zookeeper有什么功能_啊喜鸭的博客-优快云博客_zookeeper有什么用
-
zk的存储结构?
浅谈zk(6).zookeeper内部存储结构_毛志荣的博客-优快云博客
-
zookeeper在整个大数据框架中如何做到协同
一文带你读懂zookeeper在大数据生态的应用_开源Linux-优快云博客
(7)Hive
-
hive中文乱码问题如何解决?
Hive学习之路 (八)Hive中文乱码 - 扎心了,老铁 - 博客园
-
hive建表格式,存储方式?该存储方式有什么优点、缺点?
Hive 文件存储格式 - hyunbar - 博客园
-
如何处理获取的json数据?
Hive中如何处理JSON格式数据 - 碧水斜茶 - 博客园
-
已知开始时间和结束时间求中间差?
Hive 时间日期处理总结 - chenzechao - 博客园
(8)Hbase
-
如何设计的RowKey
4.综合问题
-
如何保证spark消费kafka数据不丢失?
sparkStreaming kafka保证数据不丢失、不重复_Enzo的探索之路-优快云博客
-
是否搭建过大数据结构?是否搭建过CDH
-
如何使用命令查看job作业状态?
-
时间久了之后小文件过多如何处理?
数仓面试高频考点--解决hive小文件过多问题 - 五分钟学大数据 - 博客园
-
有没有使用过CDH?开源的架构存在哪些问题?
-
每日处理的数据量
-
在数仓的每一层是做了哪些操作?
-
怎么知道数据发生了数据倾斜?
-
HA的健康管理与Hadoop是如何交互的?
-
服务器内存1G,有一个2G的文件,里面每行存着一个QQ号(5-10位数),怎么最快找出出现过最多次的QQ号。
腾讯面试题:服务器内存1G,有一个2G的文件,里面每行存着一个QQ号(5-10位数),怎么最快找出出现过最多次的QQ号。_stay hungry,stay foolish-优快云博客
-
有一数组 a[1000]存放了1000 个数,这 1000个数取自1-999, 且只有两个相同的数,剩下的 998个数不同, 写一个搜索算法找出相同的那个数的值(请用 C# or JAVA编程实现,注意空间效率和时间效率尽可能优化)
有一数组 a[1000]存放了1000 个数,这 1000个数取自1-999, 且只有两个相同的数,剩下的 998个数不同, 写一个搜索算法找出相同的那个数的值_我冷漠的博客-优快云博客
-
用过的框架的版本
汇总一天面试遇到的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









