




 本文深入解析Kafka架构,包括其高吞吐量、低延迟、可扩展性等优势,详细介绍了broker、topic、partition、leader、follower、producer、consumer、consumer group等核心组件的功能与交互。探讨了发布-订阅模型、消息单播与多播、消费者消费语义(At-most-once、At-least-once、Exactly-once)以及Kafka的两种commit机制。此外,还分析了Kafka的分区策略(Range与RoundRobin)及GroupCoordinator的作用。
本文深入解析Kafka架构,包括其高吞吐量、低延迟、可扩展性等优势,详细介绍了broker、topic、partition、leader、follower、producer、consumer、consumer group等核心组件的功能与交互。探讨了发布-订阅模型、消息单播与多播、消费者消费语义(At-most-once、At-least-once、Exactly-once)以及Kafka的两种commit机制。此外,还分析了Kafka的分区策略(Range与RoundRobin)及GroupCoordinator的作用。
目录
Kafka架构
Kafka的优势如下:
高吞吐量、低延迟
可扩展性:分布式系统易于扩展:所有的 producer、broker 和 consumer 都会有多个,均为分布式的。无需停机即可扩展机器
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点故障
高并发:支持数千个客户端同时读写
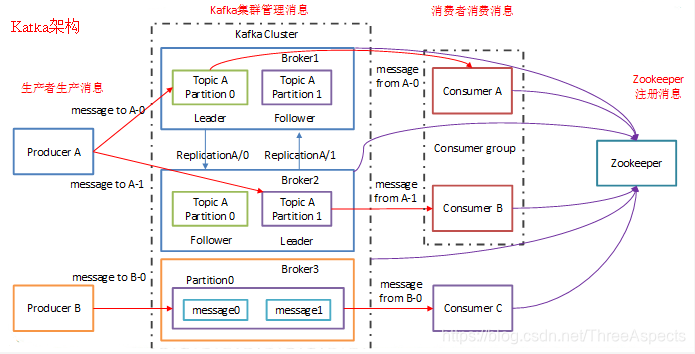
Kafka是一个分布式消息队列。与其他消息系统类似,整个系统由生产者、Broker Server和消费者三部分组成。Kafka是一种发布-订阅模式。使用Zookeeper进行集群的管理,来保证系统可用性。一个典型的Kafka集群中包含若干Producer、若干broker、若干Consumer Group以及一个Zookeeper集群。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息
broker
Kafka集群包含一个或多个服务器,服务器节点称为broker。broker存储topic的数据。只管数据存储,不管是谁生产,不管是谁消费。在集群中每个broker都有一个唯一brokerid,不得重复。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。一个Topic对应多个partition,落到磁盘上是一个partition目录,partition的目录中有多个segment组合(index,log)。
Partition
topic中的数据分割为一个或多个partition,每个topic至少有一个partition,每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序,在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
能否保证Kafka消费者消费数据是全局有序的?
1、一个topic使用一个分区,但是这样会降低性能
2、针对单分区有序,将同一个特征的数据写到一个分区
Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition
Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。ISR(In-Sync-Replica):是Replicas的一个子集,表示目前Alive且与leader能够“Catch-up”的Replicas集合
Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。
Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据
Consumer Group
Consumer Group 是Kafka提供的可扩展且具有容错性的消费者机制。在组内多个消费者实例,它们共享一个公共的ID即 Group ID 。组内的所有消费者协调在一起消费订阅主题的所有分区(Partition)。当然一个分区只能有同一个消费者组的一个Consumer 实例消费。Consumer Group 有三个特性:
- Consumer Group 下可以有一个或多个Consumer 实例。 这里的实例可以是一个单独的进程,也可以是同一进程下的线程
- Group ID 是一个字符串, 在Kafka集群中唯一标识,Consumer Group
- Consumer Group下所有实例订阅主体的单个分区,只能分配给组内某个Consumer实例消费。同一个分区消息可能被多个Group 消费
Kafka消费者组解决了哪些问题?
传统的消息系统中,有两种消息引擎模型:点对点模型(消息队列)、发布/订阅模型
传统的两种消息系统各有优势:
- 传统的消息队列模型的缺陷在于消息一旦被消费,就会从队列中删除,而且只能被下游的一个Consumer消费。但很显然这种模型的伸缩性很差,因为下游的多个Consumer 都要“抢”这个共享消息队列的消息
- 发布/订阅模型,允许消息被多个Consumer 消费,但它的问题也是伸缩性不高,因为订阅者都必须订阅所有主体的所有分区
Kafka 为规避传统消息两种模型的缺点,引入了 Consumer Group 机制:
- 当 Consumer Group 订阅多个主题后,组内的每个实例不要求一定要订阅主题的所有分区,它只会消费部分分区中的消息
- Consumer Group 之间彼此队里,互不影响,它们可以订阅同一组主题而互不干涉。加上Broker端的消息留存机制,Kafka的Consumer Group 完美的避开了伸缩性差的问题
- kafka 是用Consumer Group机制,实现了传统两大消息引擎。如果所有实例属于同一个Group,那么它实现的就是消息队列模型;如果所有实例分别属于不同的Group,且订阅了相同的主题,那么它就实现了发布/订阅模型
发布-订阅模型
Kafka消息系统基于发布-订阅模式。Kafka生产者客户端发布消息到服务端的指定主题,会指定消息所属的分区。Kafka的消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组名称。因为生产者发布到主题的每一条消息都只会发送给消费者组的一个消费者。所以,如果要实现传统消息系统的“队列”模型,可以让每个消费者都拥有相同的消费组名称,这样消息就会负责均衡到所有的消费者;如果要实现“发布-订阅”模型,则每个消费者的消费者组名称都不相同,这样每条消息就会广播给所有的消费者。
对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer,但多个Consumer Group可同时消费这一消息;那么一个group中所有的consumer将会交错地消费整个Topic,每个group中consumer消息消费互相独立,可以认为一个group是一个“订阅”者。Kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的
生产者消费者模式与订阅发布者模式的区别
生产消费者模式,指的是由生产者将数据源源不断推送到消息中心,由不同的消费者从消息中心取出数据做自己的处理;订阅发布模式,本质上也是一种生产消费者模式,不同的是,由订阅者首先向消息中心指定自己对哪些数据感兴趣,发布者推送的数据经过消息中心后会通知所有订阅者对象,每个订阅者拿到的仅仅是自己感兴趣的一组数据。生产者消费者模式是两边都在不停地查,主动触发;发布订阅模式是发布者主动触发,订阅者被动触发。
Kafka消息单播与多播
Kafka引入了消费者组概念,每个消费者都属于一个特定的消费者组,通过消费者组就可以实现消息的单播与多播。
单播
一条消息只能被某一个消费者消费的模式称为单播。要实现消息单播,只要让这些消费者属于同一个消费者组即可。当生产者发送一条消息时,只有一个消费者能收到消息。
多播
一条消息能够被多个消费者消费的模式称为多播。之所以不称之为广播,是因为一条消息只能被Kafka同一个分组下某一个消费者消费,而不是所有消费者都能消费,所以从严格意义上来讲并不能算是广播模式,当然如果希望实现广播模式只要保证每个消费者均属于不同的消费者组。针对Kafka同一条消息只能被同一个消费者组下的某一个消费者消费的特性,要实现多播只要保证这些消费者属于不同的消费者组即可。然后通过生产者发送几条消息,可以看到不同消费者组的消费者同时能消费到消息,然而同一个消费者组下的消费者却只能有一个消费者能消费到消息。
Kafka消费者的三种消费语义
at-most-once, at-least-once和exactly-once message
消费者注册到kafka有多种方式:
- subscribe(订阅):这种方式在新增topic或者partition或者消费者增加或者消费者减少的时候,会进行消费者组内消费者的再平衡
- assign(分配):这种方式注册的消费者不会进行rebalance
上面两种方式都是可以实现,三种消费语义的。
At-most-once
最多一次消费语义是kafka消费者的默认实现。配置这种消费者最简单的方式是
1)enable.auto.commit设置为true
2)auto.commit.interval.ms设置为一个较低的时间范围
3)consumer.commitSync()不要调用该方法
由于上面的配置,就可以使得kafka有线程负责按照指定间隔提交offset。但是这种方式会使得kafka消费者有两种消费语义:
- at-most-once:消费者的offset已经提交,但是消息还在处理,这个时候挂了,再重启的时候会从上次提交的offset处消费,导致上次在处理的消息部分丢失
- at-least-once:消费者已经处理完了,但是offset还没提交,那么这个时候消费者挂了,就会导致消费者重复消费消息处理。但是由于auto.commit.interval.ms设置为一个较低的时间范围,会降低这种情况出现的概率
At-least-once
实现最少一次消费语义的消费者也很简单。
1)设置enable.auto.commit为false
2)消息处理完之后手动调用consumer.commitSync()
这种方式就是要手动在处理完该次poll得到消息之后,调用offset异步提交函数consumer.commitSync()。
Exactly-once
使用subscribe实现Exactly-once
使用subscribe实现Exactly-once 很简单,具体思路如下:
1)将enable.auto.commit设置为false
2)不调用consumer.commitSync()
3)使用subcribe定于topic
4)实现一个ConsumerRebalanceListener,在该listener内部执行
consumer.seek(topicPartition,offset),从指定的topic/partition的offset处启动
5)在处理消息的时候,要同时控制保存住每个消息的offset。以原子事务的方式保存offset和处理的消息结果。
传统数据库实现原子事务比较简单。但对于非传统数据库,比如hdfs或者nosql,为了实现这个目标,
只能将offset与消息保存在同一行
使用assign实现Exactly-once
使用assign实现Exactly-once 也很简单,具体思路如下:
1)将enable.auto.commit设置为false
2)不调用consumer.commitSync()
3)调用assign注册kafka消费者到kafka
4)初次启动的时候,调用consumer.seek(topicPartition,offset)来指定offset
5)在处理消息的时候,要同时控制保存住每个消息的offset。以原子事务的方式保存offset和处理的消息结果。
传统数据库实现原子事务比较简单。但对于非传统数据库,比如hdfs或者nosql,为了实现这个目标,
只能将offset与消息保存在同一行
Consumer 两种 commit 机制
两种 commit 机制:一种是同步 commit,一种是异步 commit。对于提交的 offset,GroupCoordinator 会记录在 GroupMetadata 对象中。
同步 commit
对 poll() 中返回的所有 topics 和 partition 列表进行 commit
这个方法只能将 offset 提交 Kafka 中,Kafka 将会在每次 rebalance 之后的第一次拉取或启动时使用同步 commit
这是同步 commit,它将会阻塞进程,直到 commit 成功或者遇到一些错误
public void commitSync(){}
只对指定的 topic-partition 列表进行 commit
public void commitSync(final Map offsets){}
同步 commit 的实现方式, client.poll() 方法会阻塞直到这个request 完成或超时才会返回。使用commitSync()的方式提交数据,每次提交都需要等待broker返回确认结果。这样每提交一次等待一次会限制吞吐量。
异步 commit
对于异步的 commit只管发送提交请求无需等待broker返回确认结果,最后调用CommitAsync 方法。在异步 commit 中,可以添加相应的回调函数,如果 request 处理成功或处理失败,ConsumerCoordinator 会通过 OffsetCommitCallbacks() 方法唤醒相应的回调函数。
Kafka分区策略
在新建一个Consumer时,可以通过指定groupId来将其添加进一个Consumer Group中。Consumer Group是为了实现多个Consumer能够并行的消费一个Topic,并且一个partition只能被一个Consumer Group里的一个固定的Consumer消费。
对于一个Consumer Group,可能随时都有Consumer加入或者退出这个Consumer Group,Consumer列表的变化势必会引起partition的重新分配。这个为Consumer分配partition的过程就被称为Consumer Rebalance。默认情况下,Kafka提供了两种分配策略:Range和RoundRobin。
Range策略
Range策略的具体步骤如下:
- 对一个topic中的partition进行排序
- 对消费者按字典进行排序
- 然后遍历排序后的partition的方式分配给消费者
假设 topic 的 partition 数为 numPartitionsForTopic,group 中订阅这个 topic 的 member 数为 consumersForTopic.size() ,首先需要算出两个值:
numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size():表示平均每个 consumer 会分配到几个 partitionconsumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size():表示平均分配后还剩下多少个 partition 未分配
分配的规则是:对于剩下的那些 partition 分配到前 consumersWithExtraPartition 个 consumer 上,也就是前 consumersWithExtraPartition 个 consumer 获得 topic-partition 列表会比后面多一个
RoundRobin策略
RoundRobin策略和Range策略类型,唯一的区别就是Range策略分配partition时,是按照topic逐次划分的。而RoundRobin策略则是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询方式逐个将分区依次分配给每个消费者。
Group Coordinator
Group Coordinator是负责管理Consumer Group的组件。当一个Consumer希望加入某一个Consumer Group时,它会发送一个请求给Group Coordinator。Group Coordinator负责维护一个Consumer Group中所有的Consumer列表,随着Consumer的加入和退出,Coordinator也会随之更新这个列表。第一个加入Consumer Group的Consumer被称为leader。
一旦Consumer Group中的成员发生变化,例如有新的Consumer加入,那么就需要为其分配partition或者有Consumer退出,那么就需要将其负责消费的partition分配给组内其他成员。因此Consumer Group中的成员发生变化, Group Coordinator就负责发起Consumer Rebalance活动。
Consumer Rebalance行为是由Consumer Group Leader执行的。Group Leader首先向Coordinator获取Group中的Consumer成员列表,然后根据Rebalance策略,将partition分配给Consumer Group中的成员,再将分配结果告知Coordinator。最后,Coordinator将partition分配结果通知给每一个Consumer。在Consumer Rebalance的过程中,所有的Consumer都不允许消费消息。
Producer发送消息到Topic时,分配partition的算法如下:
- 如果指定了一个partition,那么直接使用指定的partition
- 如果没有指定partition,但是指定了key,那么会根据key进行哈希,分配到对应的partition中
- 如果partition和key都没指定,会使用round-robin算法进行分配
总结
- Consumer Groups 用于多个Consumer并行消费消息。为了防止两个消费者重复消费一条消息,Kafka不允许同一个Consumer Group中的两个Consumer读取同一个partition
- Group Coordinator 用于维护Consumer Group信息
- Consumer Rebalance 是为Consumer Group中的Consumer分配partition的过程。一旦一个Consumer Group中的成员发生变化,就会触发Rebalance行为
- Group leader 是第一个加入Consumer Group的Consumer,它负责Consumer Rebalance的执行
- Consumer Rebalance策略主要有Range和Round Robin

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









