



 Zookeeper是一种高可用的分布式协调服务,用于实现数据一致性、分布式锁和集群管理。在HA场景中,Zookeeper帮助实现NameNode的故障切换,通过EPHEMERAL-SEQUENTIAL节点实现共享锁,并确保在集群中维持正常工作的机制。Zookeeper集群需为奇数个,以保证选举机制的稳定。同时,Zookeeper的fencing机制防止了HDFS的脑裂问题,确保服务的高可用性。
Zookeeper是一种高可用的分布式协调服务,用于实现数据一致性、分布式锁和集群管理。在HA场景中,Zookeeper帮助实现NameNode的故障切换,通过EPHEMERAL-SEQUENTIAL节点实现共享锁,并确保在集群中维持正常工作的机制。Zookeeper集群需为奇数个,以保证选举机制的稳定。同时,Zookeeper的fencing机制防止了HDFS的脑裂问题,确保服务的高可用性。
Zookeeper与HA
Zookeeper
ZooKeeper基本概念

Zookeeper是高可用的分布式的协调服务。分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。Zookeeper提供对数据节点的监听器。Zookeeper提供少量数据的存储和管理。Zookeeper实现分布式锁、实现数据的一致性保证、实现数据的高可用性。在ZooKeeper任何一个客户端保存一份数据,在其他客户端都能看到。
zookeeper管理客户所存放的数据采用的是类似于文件树的结构:每一个节点叫作一个znode。Znode中的数据可以有多个版本,在查询的时候就需要带上版本号。客户端应用可以在节点上设置监视器。节点不支持部分读写,而是一次性完整读写。Zookeeper中有两种集群角色:Follower和Leader。要想保证写入数据的一致性要依靠Leader来实现。
集群中Zookeeper数量必须为奇数个。zookeeper集群要想维持正常工作,存活数量要大于集群配置数量的一半。主要因为一种选举机制,得票多者为leader。
ZooKeeper之集群管理与共享锁
Zookeeper能够很容易的实现集群管理的功能,若有多台Server组成一个服务集群,则必须要一个leader知道集群中每台机器的服务状态,从而做出调整重新分配服务策略。当集群中增加一台或多台Server时,leader同样需要知道。Zookeeper不仅能够维护当前的集群中机器的服务状态,而且能够选出一个leader来管理集群,即Zookeeper的Leader Election功能。
Zookeeper能够实现跨进程或者在不同Server之间的共享锁,其方式是需要获得锁的Server创建一个EPHEMERAL——SEQUENTIAL目录节点,然后调用getChildren方法获取当前的目录节点列表中最小的目录节点是不是自己创建的目录节点,如果是,就获得锁,如果不是,就调用exists(String path,boolean watch)方法并监控Zookeeper上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁。
HA(高可用)
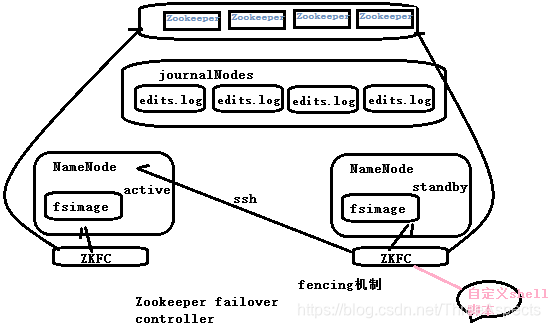
之前提到过的NameNode—Secondary NameNode架构是非HA的,对元数据的可靠性管理能够保证,元数据不会丢失,但是服务的可用性不高,因为一旦宕机了,就不能对外服务了。Yarn框架存在HA,ResourceManager状态的管理和切换也是由Zookeeper实现的。
HA指的是HDFS的高可用,整个集群中会有两个NameNode,这两个NameNode处在不同的状态,一个是active,一个是standby,负责响应客户请求的只有active状态的NameNode。这两个状态的NameNode可以很方便地切换,因为它们管理的元数据基本上是同步的,因为两个共享的元数据一个是在本地的fsimage中,最新的操作是在共享的edits的存储里面,由qjournal这样一个日志管理系统来管理这些edits日志,qjournal是基于Zookeeper实现的集群。除此还有failover controller的失败切换机制,是用来管理两个NameNode的状态的切换,其中有一个叫fencing机制,是为了防止出现脑裂,即防止两个NameNode同时处于active状态。fencing机制实现有两种方式:一个是ssh,即发一条kill指令,发给疑似出现异常的active的NameNode,然后把自己切换为acitve,该机制可能没有正常的返回值。我们还可以定义一个超时时间之后的shell脚本。

















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









