




 本文详细介绍了数据库的分库分表方法,包括垂直拆分和水平拆分,以及水平拆分中的分库分表策略。垂直拆分通过字段划分减少大表的复杂度,水平拆分则用于解决数据量过大的问题。文章强调了先垂直分后水平分的原则,并讨论了分区目的和常见分区类型。此外,文章还探讨了分库分表带来的挑战,如分布式事务和数据一致性问题,以及如何通过读写分离和数据库中间件来应对这些问题。
本文详细介绍了数据库的分库分表方法,包括垂直拆分和水平拆分,以及水平拆分中的分库分表策略。垂直拆分通过字段划分减少大表的复杂度,水平拆分则用于解决数据量过大的问题。文章强调了先垂直分后水平分的原则,并讨论了分区目的和常见分区类型。此外,文章还探讨了分库分表带来的挑战,如分布式事务和数据一致性问题,以及如何通过读写分离和数据库中间件来应对这些问题。
分库分表的方式方法
包括垂直切分和水平切分。单个库太大,要区分是因为表多而导致数据多,还是因为单张表里面的数据多。如果是因为表多而数据多,使用垂直切分,根据业务切分成不同的库。如果是因为单张表的数据量太大,这时要用水平切分,即把表的数据按某种规则切分成多张表,甚至多个库上的多张表。分库分表的顺序应该是先垂直分,后水平分。
垂直拆分
- 垂直分表
即“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。 - 垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上。一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以需要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
水平拆分
- 水平分表
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈,不建议采用。 - 水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。 - 水平分库分表切分规则
RANGE
从0到10000一个表,10001到20000一个表
HASH取模
一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
地理区域
比如按照华东,华南,华北这样来区分业务
时间
按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”
水平分库扩展问题
为了增加db的并发能力,常见的方案就是对数据进行sharding,这个需要在初期对数据规划有一个预期,从而预先分配出足够的库来处理。比如目前规划了3个数据库,基于uid进行取余分片,那么每个库上的划分规则如下:
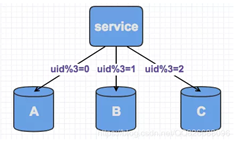
如上我们可以看到,数据可以均衡的分配到3个数据库里面。但是,如果后续业务发展的速度很快,用户量数据大量上升,当前容量不足以支撑,应该怎么办?需要对数据库进行水平扩容,再增加新库来分解。新库加入之后,原先sharding到3个库的数据,就可以sharding到四个库里面了。
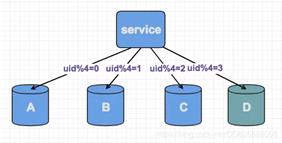
不过此时由于分片规则进行了变化(uid%3 变为uid%4),大部分的数据,无法命中在原有的数据库上了,需要重新分配,大量数据需要迁移。比如之前uid1通过uid1%3 分配在A库上,新加入库D之后,算法改为uid1%4 了,此时有可能就分配在B库上面了。在实际工程上新增一个节点,大概会有90%的数据需要迁移,那么如何应对?一般可以采用如下方式:
升级从库
步骤一:修改配置
线上数据库,为了保持其高可用,一般都会每台主库配一台从库,读写在主库,然后主从同步到从库。如下,A,B是主库,A0和B0是从库。
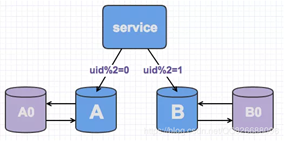
此时,当需要扩容的时候,我们把A0和B0升级为新的主库节点,如此由2个分库变为4个分库。同时在上层的分片配置,做好映射,规则如下:
uid%4=0和uid%4=2的分别指向A和A0,也就是之前指向uid%2=0的数据,分裂为uid%4=0和uid%4=2
uid%4=1和uid%4=3的指向B和B0,也就是之前指向uid%2=1的数据,分裂为uid%4=1和uid%4=3
因为A和A0库的数据相同,B和B0数据相同,所以此时无需做数据迁移即可。只需要变更一下分片配置即可,通过配置中心更新,无需重启。
步骤二:收尾工作,数据收缩
由于之前uid%2的数据分配在2个库里面,此时分散到4个库中,由于老数据还存在(uid%4=0,还有一半uid%4=2的数据),所以需要对冗余数据做一次清理。而这个清理,不会影响线上数据的一致性,可是随时随地进行。处理完成以后,为保证高可用,以及下一步扩容需求。可以为现有的主库再次分配一个从库。收尾工作包括:
(a)把双虚ip修改回单虚ip
(b)解除旧的双主同步,让成对库的数据不再同步增加
(c)增加新的双主同步,保证高可用
(d)删除掉冗余数据,例如:ip0里%4=2的数据全部删除,只为%4=0的数据提供服务
总结一下此方案步骤如下:
- 修改分片配置,做好新库和老库的映射。
- 同步配置,从库升级为主库
- 解除主从关系
- 冗余数据清理
- 为新的数据节点搭建新的从库
无论怎么做分库分表,其基本思路都是一样的。需要有分库路由,分库规则,分库关键字等。
分区
分区的目的是为了在特定的SQL操作中减少数据读写的总量以缩减响应时间。分区并不是生成新的数据表,而是将表的数据均衡分摊到不同的硬盘,系统或是不同服务器存储介质中,实际上还是一张表。另外,分区可以做到将表的数据均衡到不同的地方,提高数据检索的效率,降低数据库的频繁IO压力值。包括:水平分区和垂直分区。
综述
分区就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的。
分表就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。
常用的单机数据库的瓶颈
问题描述:
- 单个表数据量越大,读写锁,插入操作重新建立索引效率越低
- 单个库数据量太大(一个数据库数据量到1T-2T就是极限)
- 单个数据库服务器压力过大
- 读写速度遇到瓶颈(并发量几百)
分区
什么时候考虑使用分区?
- 一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 表中的数据是分段的
- 对数据的操作往往只涉及一部分数据,而不是所有的数据
分表
什么时候考虑分表?
- 一张表的查询速度已经慢到影响使用的时候
- sql经过优化
- 数据量大
- 当频繁插入或者联合查询时,速度变慢
分表解决的问题
分表后,单表的并发能力提高了,磁盘I/O性能也提高了,写操作效率提高了
- 查询一次的时间短了
- 数据分布在不同的文件,磁盘I/O性能提高
- 读写锁影响的数据量变小
- 插入数据库需要重新建立索引的数据减少
分区和分表的区别与联系
- 分区和分表的目的都是减少数据库的负担,提高表的增删改查效率
- 分区只是一张表中的数据的存储位置发生改变,分表是将一张表分成多张表
- 当访问量大,且表数据比较大时,两种方式可以互相配合使用
- 当访问量不大,但表数据比较多时,可以只进行分区
常见分区分表的规则策略
- Range(范围)
- Hash(哈希)
- 按照时间拆分
- Hash之后按照分表个数取模
- 在认证库中保存数据库配置,就是建立一个DB,这个DB单独保存user_id到DB的映射关系
分库
什么时候考虑使用分库?
- 单台DB的存储空间不够
- 随着查询量的增加单台数据库服务器已经没办法支撑
分库解决的问题
其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
垂直拆分
将系统中不存在关联关系或者需要join的表可以放在不同的数据库不同的服务器中。按照业务垂直划分。比如:可以按照业务分为资金、会员、订单三个数据库。需要解决的问题:跨数据库的事务、jion查询等问题。
水平拆分
例如,大部分的站点。数据都是和用户有关,那么可以根据用户,将数据按照用户水平拆分。按照规则划分,一般水平分库是在垂直分库之后的。比如每天处理的订单数量是海量的,可以按照一定的规则水平划分。需要解决的问题:数据路由、组装。
读写分离
对于时效性不高的数据,可以通过读写分离缓解数据库压力。需要解决的问题:在业务上区分哪些业务上是允许一定时间延迟的,以及数据同步问题。
思路:垂直分库–>水平分库–>读写分离
拆分之后面临新的问题
- 事务的支持,分库分表,就变成了分布式事务
- join时跨库,跨表的问题
- 分库分表,读写分离使用了分布式,分布式为了保证强一致性,必然带来延迟,导致性能降低,系统的复杂度变高
常用的解决方案:
对于不同的方式之间没有严格的界限,特点不同,侧重点不同。需要根据实际情况,结合每种方式的特点来进行处理。选用第三方的数据库中间件(Atlas,Mycat,TDDL,DRDS),同时业务系统需要配合数据存储的升级。

















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









