




 本文深入探讨SQL中的关键概念,如Binlog、SQL注入防御、join操作、覆盖索引与回表查询、存储过程、数据去重及常见函数的用法区别,旨在提升数据库操作效率与安全性。
本文深入探讨SQL中的关键概念,如Binlog、SQL注入防御、join操作、覆盖索引与回表查询、存储过程、数据去重及常见函数的用法区别,旨在提升数据库操作效率与安全性。
目录
Binlog
二进制日志(binlog)是记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志并存储在磁盘上。binlog不会记录SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改。Binlog日志的两个最重要的使用场景:
- MySQL主从复制:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的
- 数据恢复:通过使用 mysqlbinlog工具来使恢复数据
写 Binlog 的时机
对支持事务的引擎如InnoDB而言,必须要提交了事务才会记录binlog。binlog 什么时候刷新到磁盘跟参数sync_binlog相关。
- 如果设置为0,则表示MySQL不控制binlog的刷新,由文件系统去控制它缓存的刷新
- 如果设置为不为0的值,则表示每 sync_binlog 次事务,MySQL调用文件系统的刷新操作刷新binlog到磁盘中。设为1是最安全的,在系统故障时最多丢失一个事务的更新,但是会对性能有所影响
- 如果 sync_binlog=0 或 sync_binlog大于1,当发生电源故障或操作系统崩溃时,可能有一部分已提交但其binlog未被同步到磁盘的事务会被丢失,恢复程序将无法恢复这部分事务
Binlog 的日志格式
记录在二进制日志中的事件的格式取决于二进制记录格式。支持三种格式类型:
- STATEMENT:基于SQL语句的复制
- ROW:基于行的复制
- MIXED:混合模式复制
Statement:每一条会修改数据的sql都会记录在binlog中。这种格式的binlog进行数据恢复时,如果SQL语句带有rand或uuid等函数,可能导致恢复出来的数据与原始数据不一致
Row:row记录的则是行的更改情况,可以避免之前提到的数据不一致的问题。但是row格式有一个不好的地方就是当修改的行数很多时,生成的binlog占用很大的空间,占用大量空间的同时还会耗费大量IO资源。注:将二进制日志格式设置为ROW时,有些更改仍然使用基于语句的格式,包括所有DDL语句,例如CREATE TABLE, ALTER TABLE,或 DROP TABLE。
Mixed:在Mixed模式下,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种
SQL中drop和delete的区别
delete:
1、DELETE属于数据库DML操作语言,只删除数据不删除表的结构,会走事务,执行时会触发trigger
2、在 InnoDB 中,DELETE其实并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记为已删除,因此 delete 删除表中的数据时,表文件在磁盘上所占空间不会变小,存储空间不会被释放,只是把删除的数据行设置为不可见。虽然未释放磁盘空间,但是下次插入数据的时候,仍然可以重用这部分空间(重用 → 覆盖)
3、DELETE执行时,会先将所删除数据缓存到rollback segement中,事务commit之后生效
4、delete from table_name删除表的全部数据,对于MyISAM 会立刻释放磁盘空间,InnoDB 不会释放磁盘空间
5、对于delete from table_name where xxx 带条件的删除, 不管是InnoDB还是MyISAM都不会释放磁盘空间
6、delete操作以后使用 optimize table table_name 会立刻释放磁盘空间。不管是InnoDB还是MyISAM 。所以要想达到释放磁盘空间的目的,delete以后执行optimize table 操作
7、delete 操作是一行一行执行删除的,并且同时将该行的的删除操作日志记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,生成的大量日志也会占用磁盘空间
drop:
1、drop是DDL,会隐式提交,所以,不能回滚,不会触发触发器
2、drop语句删除表结构及所有数据,并将表所占用的空间全部释放
3、drop语句将删除表的结构所依赖的约束,触发器,索引,依赖于该表的存储过程/函数将保留,但是变为invalid状态
truncate:
1、truncate属于数据库DDL定义语言,不走事务,原数据不放到 rollback segment 中,操作不触发 trigger。执行后立即生效,无法找回
2、truncate table table_name 立刻释放磁盘空间 ,不管是 InnoDB和MyISAM 。truncate table其实有点类似于drop table 然后creat,只不过这个create table 的过程做了优化,比如表结构文件之前已经有了等等。所以速度上应该是接近drop table的速度
3、truncate能够快速清空一个表。并且重置auto_increment的值。但对于不同的类型存储引擎需要注意的地方是:
- 对于MyISAM,truncate会重置auto_increment(自增序列)的值为1。而delete后表仍然保持auto_increment
- 对于InnoDB,truncate会重置auto_increment的值为1。delete后表仍然保持auto_increment。但是在做delete整个表之后重启MySQL的话,则重启后的auto_increment会被置为1
也就是说,InnoDB的表本身是无法持久保存auto_increment。delete表之后auto_increment仍然保存在内存,但是重启后就丢失了,只能从1开始。实质上重启后的auto_increment会从 SELECT 1+MAX(ai_col) FROM t 开始。
防止sql注入
SQL注入是比较常见的网络攻击方式之一,它不是利用操作系统的BUG来实现攻击,而是针对程序员编程时的疏忽,通过SQL语句,实现无帐号登录,甚至篡改数据库。
1、输入校验:做好规范的校验工作,比如搜索框不能输入sql语句等
2、权限控制:在创建一个SQL数据库的用户帐户时,要遵循最低权限法则。用户应只拥有使用其帐户的必要的最低特权。如果系统显示需要用户可以读取和修改自己的数据,那么应该限制其特权,使他们无法读取/编写别人的数据
3、重复校验:在服务器端重复客户端所进行的所有过滤
4、动态参数:应使用prepared statements语句绑定变量来执行SQL字符串。没有使用prepared statements语句绑定变量可能很容易受到攻击
where,group by,having,order by执行顺序
标准的 SQL 的解析顺序为:
(1).FROM 子句, 组装来自不同数据源的数据
(2).WHERE 子句, 基于指定的条件对记录进行筛选
(3).GROUP BY 子句, 将数据划分为多个分组
(4).使用聚合函数进行计算
(5).使用 HAVING 子句筛选分组
(6).Select:查看结果集中的哪个列,或列的计算结果
(7).使用 ORDER BY 对结果集进行排序
(8).LIMIT
having和where的用法区别:
1.having只能用在group by之后,对分组后的结果进行筛选
2.where肯定在group by 之前,即也在having之前
3.where后的条件表达式里不允许使用聚合函数,而having可以
4.having后只能跟group by后边字段条件或者非group by(group by 字段也可以使用聚合函数)字段的聚合函数条件(按组查询)
1.FROM
2.ON
3.JOIN
4.WHERE
5.GROUP BY
6.WITH CUBE or WITH ROLLUP
7.HAVING
8.SELECT
9.DISTINCT
10.ORDER BY
11.TOP
补充: select a.bp , sum(a.a) from a join b on a.bp=b.bp and a.id=b.id;说一下整个执行过程。
MySQL四种join
【1】SQL四种join
INNER JOIN等值查询,返回两张表中,联结字段值相等的组合记录。
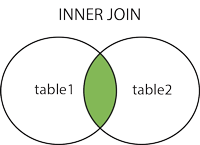
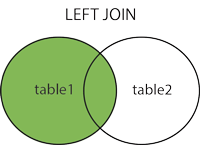
LEFT JOIN左外关联查询,返回包括左表中的所有记录和右表中联结字段有关的组合记录。如果左表中数据多于右表,查询结果中右表的数据为null。
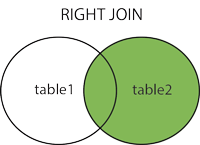
RIGHT JOIN右外关联查询,返回包括右表中的所有记录和左表中联结字段相等的组合记录。如果右表中数据多于左表,查询结果中左表的数据为null。
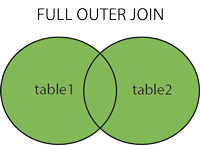
outer join包括left join,right join和full join
FULL JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行。FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。如果数据库不支持FULL JOIN,如MySQL不支持FULL JOIN,那么可以使用UNION ALL子句,将两个JOIN为如下:
SELECT table1.column1, table2.column2...
FROM table1
FULL JOIN table2
ON table1.common_field = table2.common_field;
SQL> SELECT ID, NAME, AMOUNT, DATE
FROM CUSTOMERS
LEFT JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID
UNION ALL
SELECT ID, NAME, AMOUNT, DATE
FROM CUSTOMERS
RIGHT JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID
MySQL的join过程
join过程:笛卡尔积->on条件过滤->添加外部行->where条件->select 。执行顺序如下:
- FROM:对左右两张表执行笛卡尔积,产生第一张表vt1。行数为n*m(n为左表的行数,m为右表的行数)
- ON:根据ON的条件逐行筛选vt1,将结果插入vt2中
- JOIN:添加外部行,如果指定了LEFT JOIN,则先遍历一遍左表的每一行,其中不在vt2的行会被插入到vt2,该行的剩余字段将被填充为NULL,形成vt3;如果指定了RIGHT JOIN也是同理。但如果指定的是INNER JOIN,则不会添加外部行,上述插入过程被忽略,vt2=vt3(所以INNER JOIN的过滤条件放在ON或WHERE里 执行结果是没有区别的)
- WHERE:对vt3进行条件过滤,满足条件的行被输出到vt4
- SELECT:取出vt4的指定字段到vt5
覆盖索引与回表
一、什么是回表查询?
InnoDB有两大类索引:聚簇索引、非聚簇索引。
聚集索引(主键索引):
- 聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据
- 聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分
辅助索引(二级索引):
- 非主键索引,叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
画外音:所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
画外音:注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:
t(id PK, name KEY, sex, flag);
画外音:id是聚集索引,name是普通索引。
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
image
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?通常情况下,需要扫码两遍索引树。例如:select * from t where name='lisi';是如何执行的呢?

如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
什么是覆盖索引,有下面三种理解:
- 解释一: select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。即只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
回表查询:
需要扫描两遍索引树:(1)先通过普通索引定位到主键值
(2)再通过聚集索引定位到行记录
先定位主键值,再定位行记录,它的性能较扫一遍索引树更低
- 解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引。
- 解释三:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引。当发起一个索引覆盖查询时,在EXPLAIN的Extra列可以看到“Using index”的信息。
如何实现索引覆盖? 常见的方法是:将被查询的字段,建立到联合索引里去。
哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
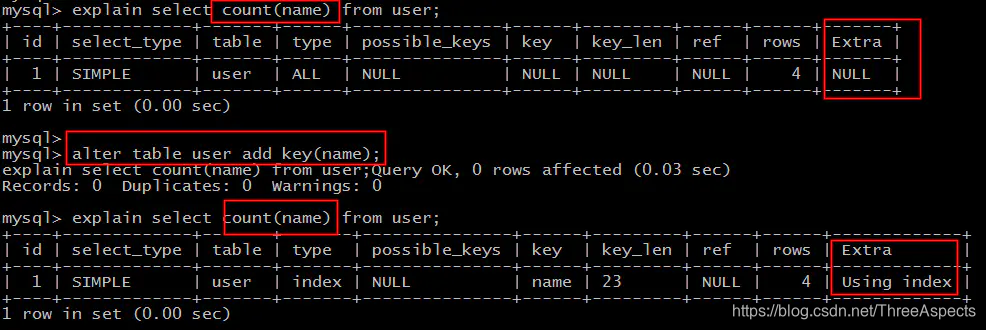
能够利用索引覆盖提效。
场景2:列查询回表优化
select id,name,sex … where name=‘shenjian’;
将单列索引(name)升级为联合索引(name, sex),即可避免回表。
场景3:分页查询
select id,name,sex … order by name limit 500,100;
将单列索引(name)升级为联合索引(name, sex),也可以避免回表。
数据库存储过程
存储过程是在大型数据库系统中,一组为了完成特定功能的SQL语句集,存储在数据库中,经过第一次编译后调用不需要再次编译,用户通过指定存储过程的名字并给出参数来执行它。 存储过程就是有业务逻辑和流程的集合, 可以在存储过程中创建表,更新数据, 删除等等。存储过程的特点:
1、能完成较复杂的判断和运算
2、可编程行强,灵活
3、SQL编程的代码可重复使用
4、执行的速度相对快一些
5、减少网络之间的数据传输,节省开销
创建一个简单的存储过程
1、创建存储过程的简单语法
create procedure 过程名([[IN|OUT|INOUT] 参数名 数据类型)
begin
.........
end
存储过程根据需要可能会有输入、输出、输入输出参数,如果有多个参数用","分割开。MySQL存储过程的参数用在存储过程的定义,共有三种参数类型:IN、OUT、INOUT:IN参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值。OUT该值可在存储过程内部被改变,并可返回。INOUT:调用时指定,并且可被改变和返回。
2、调用存储过程
call testa();
count(1),count(*)和count(列名)的区别
从执行结果来说: count(1)和count( * )之间没有区别,因为count( * )和count(1)都不会去过滤空值,但count(列名)就有区别了,因为count(列名)会去过滤空值。从执行效率来说:他们之间根据不同情况会有些许区别,MySQL会对count( * )做优化。
(1)如果列为主键,count(列名)效率优于count(1)
(2)如果列不为主键,count(1)效率优于count(列名)
(3)如果表中存在主键,count(主键列名)效率最优
(4)如果表中只有一列,则count(*)效率最优
(5)如果表有多列,且不存在主键,则count(1)效率优于count( * )
关于count(1)count( * )原理:count(1),其实就是计算一共有多少符合条件的行。1并不是表示第一个字段,而是表示一个固定值。其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1。count( * ),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。
Avg、sum、count 函数,在某列有空值的情况下,结果会有哪些不同
一、AVG()
AVE()忽略NULL值
二、COUNT()
两种用法
1、COUNT(*)
对表中行数进行计数,不管是否有NULL
2、COUNT(字段名)
对特定列有数据的行进行计数,忽略NULL值
三、SUM()
忽略NULL值
除了distinct外如何使用对数据去重
group by having count(*)>=1 查出所有的记录,但重复的只显示一条
group by 和 distinct的区别
1、distinct只是将重复的行从结果中出去;group by是按指定的列分组,一般这时在select中会用到聚合函数。
2、distinct是把不同的记录显示出来;group by是在查询时先把纪录按照类别分出来再查询
3、group by 必须在查询结果中包含一个聚集函数,而distinct不用
union与union all
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
两个不同列数表的合并(把一些列设为null,union即可)
select 姓名,性别,年龄 from student
union select 课程代号,课程内容,null from course;
Mysql中char和varchar的区别
区别一:定长和变长
char 表示定长,长度固定,varchar表示变长,即长度可变。当所插入的字符串超出它们的长度时,视情况来处理,如果是严格模式,则会拒绝插入并提示错误信息,如果是宽松模式,则会截取然后插入。如果插入的字符串长度小于定义长度时,则会以不同的方式来处理,如char(10),表示存储的是10个字符,无论你插入的是多少,都是10个,如果少于10个,则用空格填满。而varchar(10),小于10个的话,则插入多少个字符就存多少个。
varchar怎么知道所存储字符串的长度呢?实际上,对于varchar字段来说,需要使用一个(如果字符串长度小于255)或两个字节(长度大于255)来存储字符串的长度。但是因为他需要有一个prefix来表示他具体bytes数是多少(因为varchar是变长的,没有这个长度值他不知道如何读取数据)。
区别之二:存储的容量不同
对 char 来说,最多能存放的字符个数 255,和编码无关。而 varchar最多能存放 65532 个字符。VARCHAR 的最大有效长度由最大行大小和使用的字符集确定。整体最大长度是 65,532字节。
其他
(1 )两条语句的执行结果是否一样?为什么?
(2 )假设,数据量很大的情况下,您会选择哪种语句执行?也可以自行开发
–sql 语句 1
select
t1.id,t1.xxx,t2.xxx
from t1 left join t2
on t1.id = t2.id and t1.id < 10
–sql 语句 2
select
t1.id,t1.xxx,t2.xxx
from t1 left join t2
on t1.id = t2.id
where t1.id < 10
答:
1)由于left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left 或right表中的记录,full则具有left 和right的特性的并集。sql 1中采用的是left join,所以 on 里的 t1.id <10 对左表 t1 不起作用,结果还是会返回t1 表的所有数据。sql 2则是先通过on上的条件,将两表关联,在最终关联好的表上,在进行过滤,所以只会返回t1.id < 10 的所有数据。
- 当数据量很大的情况下,基于上述情况我会选择sql2,但是性能不高,可以采用以下查询
select
tmp_t1.id,tmp_t1.xxx,t2.xxx
from
(
select * from t1 where t1.id < 10
) tmp_t1 left join t2
on tmp_t1.id = t2.id;
类型转换
隐式类型转换和显式类型转换
隐式类型装换:两个值进行运算或者比较,首先要求数据类型必须一致。如果发现两个数据类型不一致时就会发生隐式类型转换。例如,把字符串转成数字或者相反:
SELECT 1+‘1’; – 字符串1转成数字
SELECT concat(2,’ test’); – 数字2转成字符串
显式类型转换:利用函数进行数据类型的转换
Cast函数
CAST(expr AS type)
将任意类型的表达式expr转换成指定类型type的值。type可以是以下任意类型之一:
BINARY[(N)] :二进制字符串
CHAR[(N)] :字符串
DATE :日期
DATETIME :日期时间
DECIMAL[(M[,N])] :浮点数,M为数字总位数(包括整数部分和小数部分),N为小数点后的位数
SIGNED [INTEGER] :有符号整数
TIME :时间
UNSIGNED [INTEGER] :无符号整数
Convert函数
CONVERT(expr, type)
CONVERT(expr USING sharset_name)
convert函数的作用和cast函数几乎相同,但是它可以把字符串从一种字符集转换成另一种字符集。
约束,表与表之间的关系
约束
not null:不为空
unique:唯一约束,数据唯一不能重复
索引:相当于字典的目录,通过索引可以加快查询速度
primary key:主键,标记数据的唯一特征(唯一且不为空的数据)
foreign key:外键,把多张表通过一个关联字段,联合在一起
表与表之间的关系
(1)一对一:表1中的主键(唯一索引)关联表2中的主键(唯一索引)字段形成一对一的关系
(2)一对多或多对一:一个班级里可以对应多个学生,把学生作为主动关联的表,设置一个外键,去存储班级表的关联字段中的数据
(3)多对多:一个学生可以对应多个学科,一个学科也可以被多个学生学习
数据库DQL、DML、DDL、DCL
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
(1)数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE
子句组成的查询块:
SELECT <字段名表> FROM <表或视图名> WHERE <查询条件>
(2)数据操纵语言DML
数据操纵语言DML主要有三种形式:
1、插入:INSERT 2、更新:UPDATE 3、删除:DELETE
(3)数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象:表、视图、索引、同义词、聚簇等如:CREATE TABLE/VIEW/INDEX/SYN/CLUSTER。DDL操作是隐性提交的,不能rollback
(4)数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制
数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1、GRANT:授权。
2、ROLLBACK:回滚,回滚命令使数据库状态回到上次最后提交的状态。
3、COMMIT [WORK]:提交。

















 3966
3966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









