




 本文深入分析了Spark Submit脚本的执行过程,从spark-class的调用开始,详细阐述了prepareSubmitEnvironment方法如何设置环境,包括clusterManager和部署模式。接着讨论了standalone集群下两种提交网关,特别是基于REST的提交方式。在doRunMain方法中,通过反射执行用户主方法。当部署模式为client或cluster时,分别讲述了不同的执行逻辑。在Client模式下,ClientEndpoint的onStart方法负责启动和配置Driver。整个Spark Submit任务提交在向Master发送driver描述后完成,等待driver注册结果。
本文深入分析了Spark Submit脚本的执行过程,从spark-class的调用开始,详细阐述了prepareSubmitEnvironment方法如何设置环境,包括clusterManager和部署模式。接着讨论了standalone集群下两种提交网关,特别是基于REST的提交方式。在doRunMain方法中,通过反射执行用户主方法。当部署模式为client或cluster时,分别讲述了不同的执行逻辑。在Client模式下,ClientEndpoint的onStart方法负责启动和配置Driver。整个Spark Submit任务提交在向Master发送driver描述后完成,等待driver注册结果。
脚本分析
从Spark-submit这个脚本作为入口,脚本最后调用exec执行 “${SPARK_HOME}”/bin/spark-class 调用class为:org.apache.spark.deploy.SparkSubmit
整个Spark Submit过程图:
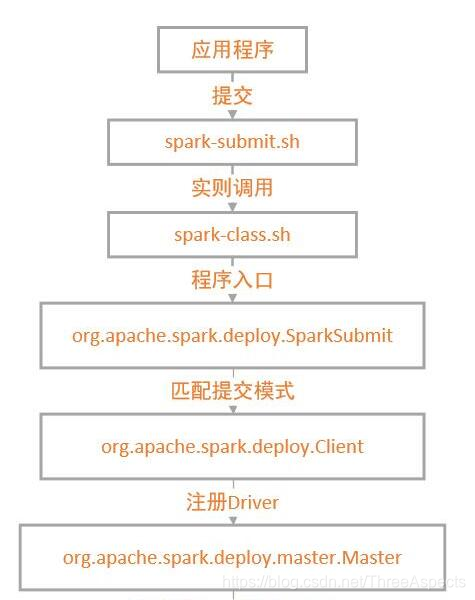
看一下spark-class脚本执行步骤:
1.首先校验$ SPARK_HOME/conf,spark相关依赖目录$ SPARK_HOME/jars,hadoop相关依赖目录$HADOOP_HOEM/lib
2.将校验所得所有目录地址拼接为LAUNCH_CLASSPATH变量
3.将$JAVA_HOME/bin/java 定义为RUNNER变量
4.调用build_command()方法,创建执行命令
5.把build_command()方法创建的命令,循环加到数组CMD中,最后执行exec执行CMD命令
源码解析
最终执行的命令中,指定了程序的入口为org.apache.spark.deploy.SparkSubmit,来看一下它的主函数:
根据解析后参数action进行模式匹配,如果是submit操作,则调用submit方法,submit方法中,首先调用prepareSubmitEnvironment方法,准备submit环境。prepareSubmitEnvironment方法中做了如下操作:
1.根据参数中master和delpoy-mode,设置对应的clusterManager和部署模式
2.再根据args中的其他参数,设置相关childArgs, childClasspath, sysProps, childMainClass,并返回结果
prepareSubmitEnvironment完成后,需要判断是否为Standalone Cluster模式和是否设置了useRest。在standalone集群模式下,有两个提交网关:
1.使用org.apache.spark.deploy.Client作为包装器来使用传统的RPC网关
2.Spark 1.3中引入的基于rest的网关
第二种方法是Spark 1.3的默认行为,但是Spark submit将会失败,如果master不是一个REST服务器,那么它将无法使用REST网关。
接着看一下doRunMain方法,其实调用了runMain方法,runMain通过反射mainMethod.invoke执行该方法:
- 当deploy mode为client时,执行用户自己编写的主方法
- 当deploy mode为cluster时,需要判断是否为REST提交,如果是则执行
org.apache.spark.rest.RestSubmissionClient的主方法,如果不是则执行org.apache.spark.deploy.Client的主方法
来看传统的org.apache.spark.deploy.Client提交方式:
Client用于启动和终止独立集群中的Driver程序,这个ClientEndpoint用于将消息转发给Driver程序的代理,启动时调用其onStart方法,该方法执行内容如下:
1.根据cmd进行模式匹配,如果命令为launch,获取driver额外的java依赖、classpath、java配置
2.在提交spark任务时,可添加一些额外的参数对driver进行额外的配置:
spark.driver.extraClassPath driver的额外classpath
spark.driver.extraLibraryPath driver的额外lib路径
spark.driver.extraJavaOptions driver的额外java配置,jvm相关配置
在onStart方法中,第二个步骤就是,获取的driver额外参数的配置
3.将获取到的额外配置和driver参数封装为command对象,即在命令行启动时执行的shell命令
4.将command和driver启动信息封装为driverDescription对象,该对象为driver的基本信息描述,调用RequestSubmitDriver方法,将driver相关信息发送给Master,向Master申请注册Drvier
在向master发送消息后,整个的Spark-Sumit任务提交就完成了,接下来就是等待master返回driver的注册结果,启动driver,driver的注册请访问

















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









