




 本文探讨了HBase中二级索引的设计和实现,由于HBase不支持跨表事务,开发者需要自行实现分布式事务机制以保证数据一致性。二级索引本质是创建列值与行键的映射,通过特定的Hash前缀策略,确保索引与主数据在同一Region,降低查询性能损失。同时,逻辑和物理上的双重隔离解决了混合存储带来的问题,实现了性能和可维护性的平衡。
本文探讨了HBase中二级索引的设计和实现,由于HBase不支持跨表事务,开发者需要自行实现分布式事务机制以保证数据一致性。二级索引本质是创建列值与行键的映射,通过特定的Hash前缀策略,确保索引与主数据在同一Region,降低查询性能损失。同时,逻辑和物理上的双重隔离解决了混合存储带来的问题,实现了性能和可维护性的平衡。
由于在 HBase 中的二级索引是通过建表的方式实现的,当需要更新时,就是两个表的数据原子更新,也就是跨表的事务功能,而 Hbase 只提供行级事务,没有跨表和跨行的事 务功能,这就需要开发者自己去实现,如果对数据一致性要求较高,那么就可能需要自己 去实现一套分布式的事务机制,之所以是分布式的事务机制,是因为原始数据可能由一些 HRegionserver 维护,而索引表由另外一些 HRegionserver 维护,这个事务机制就涉及到了多个HRegionserver,也就是分布式的事务机制。
二级索引设计
二级索引的本质就是建立各列值与行键之间的映射关系,以列的值为键,以记录的RowKey 为值。
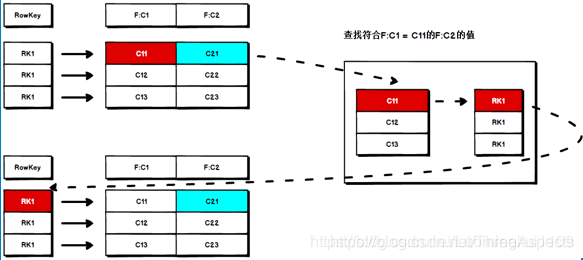
如图所示,当要对 F:C1 这列建立索引时,只需要建立 F:C1 各列值到其对应行键 的映射关系,如 C11->RK1 等,这样就完成了对 F:C1 列值的二级索引的构建,当要查询符 合 F:C1=C11 对应的 F:C2 的列值时。 其查询步骤如下:
1. 根据 C1=C11 到索引数据中查找其对应的 RK,查询得到其对应的 RK=RK1;
2. 得到 RK1 后就自然能根据 RK1 来查询 C2 的值了 这是构建二级索引大概思路,其 他组合查询的联合索引的建立也类似。
二级索引设计剖析
“二级多列索引”是针对目标记录的某个或某些列建立的“键-值”数据,以列的值为键,以记录的 RowKey 为值,当以这些列为条件进行查询时,引擎可以通过检索相应的“键 -值”数据快速找到目标记录。由于 HBase 本身并没有索引机制,为了确保非侵入性,引擎将索引视为普通数据存放在数据表中,所以,如何解决索引与主数据的划分存储是引擎第一个需要处理的问题。
为了能获得最佳的性能表现,并没有将主数据和索引分表储存,而是将它们存放在了同一张表里,通过给索引和主数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









