




 跳表是一种结合链表和二分查找特性的数据结构,通过在链表中加入跳跃指针来提高查找效率。它允许在O(logn)的时间复杂度内进行动态插入和删除操作。在Redis中,跳表被用于实现有序集合,相比红黑树,其操作更简单、快速。跳表由多层有序链表组成,每层链表包含部分元素,且上级链表的元素也在下级链表中出现,查找、插入和删除操作的时间复杂度均为O(logn)。
跳表是一种结合链表和二分查找特性的数据结构,通过在链表中加入跳跃指针来提高查找效率。它允许在O(logn)的时间复杂度内进行动态插入和删除操作。在Redis中,跳表被用于实现有序集合,相比红黑树,其操作更简单、快速。跳表由多层有序链表组成,每层链表包含部分元素,且上级链表的元素也在下级链表中出现,查找、插入和删除操作的时间复杂度均为O(logn)。
跳表
结合链表和二分法的特点,将链表进行加工,创造一个二者的结合体:
- 链表从头节点到尾节点是有序的
- 可以进行跳跃查找(形如二分法),降低时间复杂度
跳表其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
跳表的性质
(1) 由很多层结构组成,level是通过一定的概率随机产生的
(2) 每一层都是一个有序的链表,默认是升序
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在Level i 的链表中,则它在Level i 之下的链表也都会出现
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素
next数组
一个有序的链表,选取它的一半的节点用来建索引,这样如果插入一个节点,比较的次数就减少了一半。这种做法,虽然增加了50%的空间,但是性能提高了一倍。
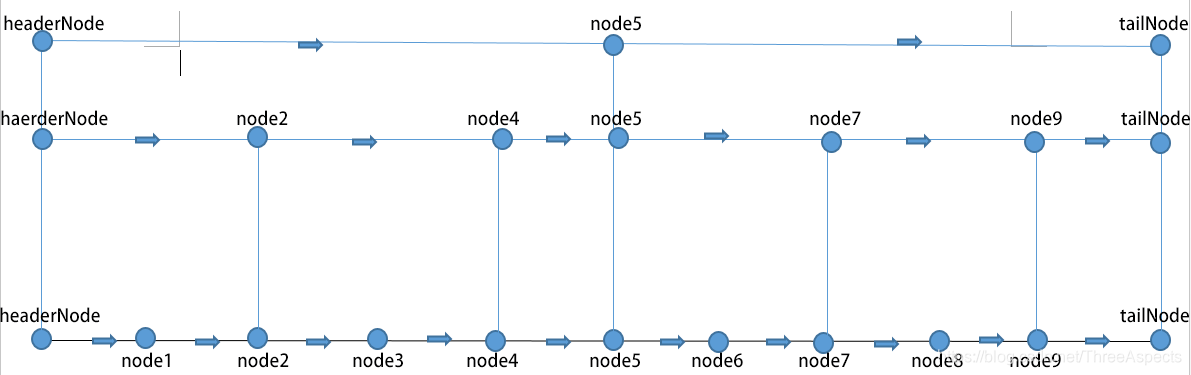
通常会定义跳表的级数,即层数-1(最下面一级是0级)。所以这张图表示的跳表的级数是(0, 1, 2)。而在第2级的节点(比如node5),它的next数组大小就是(2 + 1) == 3, 在第1级的节点(比如node4),它的next数组的大小就是(1 + 1) == 2, 在第0级的节点(比如node3),它的next数组大小是1。对于第2级的node5来说:
node5->next[2] == tailNode;
node5->next[1] == node7;
node5->next[0] == node6;
对于第1级的node2来说:
node2->next[1] == node4;
node2->next[0] == node3;
查找
headerNode和tailNode是人为添加的两端节点,很像存在头节点和尾节点的链表,它们不存储需要保存的有用的数据,仅仅是用来判断是否是头和尾。当跳表为空时,级数为0,headerNode->next[0] == tailNode。比较的时候的三种情况,以targetNode->next[i]->element和theElement为例:
1.小于:令targetNode = targetNode->next[i]; //第i级链表的下一个
2.大于:向下降级,i- - //不改变targetNode
3.等于:向下降级,i- - //不改变targetNode
最后,再次比较targetNode->next[0]和theElement,判断是否找到。所以整个运算下来,targetNode是要查找的节点前面那个节点。查找的时间复杂度为 O(logn)。
插入
当有2级索引时,新的节点先和2级索引比较,再和1级索引比较,最后和原链表比较,最终插到原链表中。当节点很多时,比较次数是原来的四分之一。
当节点足够多的时候,还可以继续加索引,保证每一层索引数是低级索引的一半。当这一层只剩两个节点时,就没有必要再建索引了,因为一个节点没有比较的意义。
当很多节点插入时,上层索引节点已经不够用,需要在新节点中选取一部分节点提到上一层,跳表的设计者用“抛硬币”的方法选取节点是否提拔,也就是随机的方式,每个节点有50%概率会提拔。这样虽然不会让索引绝对均匀分布,但也会大体上是均匀的。综上,插入的步骤:
- 新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logN)
- 把索引插入到原链表。O(1)
- 利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logN)
总体上,跳表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,既空间复杂度是 O(N)。
删除
- 自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
- 删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
总体上,跳表删除操作的时间复杂度是O(logN)。
跳表高效地动态插入和删除
在跳表中,查找的时间复杂度为 O(logn),因此,动态插入数据的时间复杂度也就是 O(logn)了。从链表中删除结点的时候,如果结点在索引中也有出现,那么除了要删除原始链表中的结点,还要删除索引中的。
当不停地往跳表中插入数据的时候,如果不更新索引,就有可能出现某两个结点之间数据非常多的情况。极端情况下,跳表还会退化为单链表。因此,需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表结点变多了,索引值就相应地增加一些。
当往跳表中插入数据的时候,可以选择同时也将这个数据插入到部分索引层中。而插入到哪些索引层中,则由一个随机函数生成一个随机数字来决定。如果这个数字为 K,那就将数据插入到第一级到第 K 级索引中。
Redis用跳表来实现有序集合而不是红黑树?
Redis 中的有序集合支持的核心操作主要有:插入一个数据;删除一个数据;查找一个数据;按照区间查找数据;迭代输出有序序列。
其中,插入、删除、查找以及迭代输出有序序列这几个操作,而红黑树的插入很可能会涉及多个结点的旋转、变色操作。而SkipList底层是用链表实现的,只需要修改相邻节点的指针,操作简单又快速。
范围查找:skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。跳表可以在 O(logn)时间复杂度定位区间的起点,然后在原始链表中顺序向后查询就可以。在做范围查找的时候,平衡树比skiplist操作要复杂(红黑树的效率没有跳表高)。在平衡树上,找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









