




 本文详细介绍了Hive窗口函数的使用,包括窗口函数的实现原理、常用序列函数如NTILE、ROW_NUMBER、RANK、DENSE_RANK、LAG和LEAD,以及FIRST_VALUE和LAST_VALUE。同时,讨论了Hive中的内部表和外部表的区别,强调了在数据管理和删除时的注意事项,提供了数据备份和管理的建议。
本文详细介绍了Hive窗口函数的使用,包括窗口函数的实现原理、常用序列函数如NTILE、ROW_NUMBER、RANK、DENSE_RANK、LAG和LEAD,以及FIRST_VALUE和LAST_VALUE。同时,讨论了Hive中的内部表和外部表的区别,强调了在数据管理和删除时的注意事项,提供了数据备份和管理的建议。
Hive窗口函数
在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
聚合函数+over
查询在2015年4月份购买过的顾客及总人数,使用窗口函数实现
select name,count(*) over ()
from t_window
where substring(orderdate,1,7) = '2015-04'
partition by子句
Over子句之后第一个提到的就是Partition By。Partition By子句也可以称为查询分区子句,非常类似于Group By,都是将数据按照边界值分组,而Over之前的函数在每一个分组之内进行,如果超出了分组,则函数会重新计算。
查看顾客的购买明细及月购买总额,可以执行如下的sql
select name,orderdate,cost,
sum(cost) over(partition by month(orderdate))
from t_window
order by子句
order by子句会让输入的数据强制排序(窗口函数是SQL语句最后执行的函数,因此可以把SQL结果集想象成输入数据)。Order By子句对于诸如Row_Number(),Lead(),LAG()等函数是必须的,因为如果数据无序,这些函数的结果就没有任何意义。因此如果有了Order By子句,则Count(),Min()等计算出来的结果就没有任何意义。
sum() 中加order by 和不加order by的区:加了的话是一个累加的过程,不加是分组汇总,比如有10条记录,算的每个值都一样是(是和),加了order by 就是每一行数据依次累加。一般求sum,不加order by
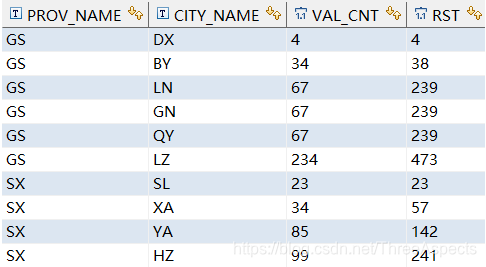
select prov_name, city_name, val_cnt,
sum(val_cnt) over(partition by prov_name ORDER BY val_cnt) AS rst
from test_orer_partition_by ;
select prov_name, city_name, val_cnt,
sum(val_cnt) over(partition by prov_name) AS rst
from test_orer_partition_by ;

window子句
已经通过使用partition by子句将数据进行了分组的处理。如果想要更细粒度的划分,需要引入window子句。首先要理解两个概念:
- 如果只使用partition by子句,未指定order by的话,聚合是分组内的聚合
- 使用了order by子句,未使用window子句的情况下,默认从起点到当前行
当同一个select查询中存在多个窗口函数时,它们相互之间是没有影响的。每个窗口函数应用自己的规则。window子句:
- PRECEDING:往前
- FOLLOWING:往后
- CURRENT ROW:当前行
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
按照name进行分区,按照购物时间进行排序,做cost的累加。如下结合使用window子句进行查询
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from t_window;
窗口函数实现原理
窗口函数的实现,主要借助一个叫做WindowingTableFunction的Partitioned Table Function (即PTF);PTF的输入可以是:表、子查询或另一个PTF函数输出;PTF输出也是一张表。
select channel, month,
sum(amount),
denserank() over (partition by channel order by sum(amount) desc) as dr,
rank() over(partition by channel order by sum(amount)desc) as r
from sales
group by channel, month;
考虑以上代码,在Hive中具体实现主要有两个阶段:
- 计算除窗口函数以外所有的其他运算,如:group by,join ,having等。上面的代码的第一阶段即为:
select channel, month, sum(amount) as s from sales group by channel, month;
- 将上一步的输出作为 WindowingTableFunction 函数的输入,计算对应的窗口函数值。上面代码的第二阶段即为:
select channel, month, s,dr,r from
WindowingTableFunction(
-- 上一阶段的输出
<select channel, month, sum(amount) as s from sales group by channel, month>,
-- 窗口函数的分区list
partition by channel,
-- 窗口函数的order list
order by s,
-- 窗口函数调用
[r:<rank()>, dr:<denserank()>]
)
窗口函数中的序列函数
序列函数是不支持window子句的。Hive中常用的序列函数有下面几个:
NTILE
- NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
- NTILE不支持ROWS BETWEEN, 比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
- 如果切片不均匀,默认增加第一个切片的分布
假如想要每位顾客购买金额前1/3的交易记录,便可以使用这个函数.
select name,orderdate,cost,
ntile(3) over() as sample1 , --全局数据切片
ntile(3) over(partition by name), -- 按照name进行分组,在分组内将数据切成3份
ntile(3) over(order by cost),--全局按照cost升序排列,数据切成3份
ntile(3) over(partition by name order by cost ) --按照name分组,在分组内按照cost升序排列,数据切成3份
from t_window
row_number/rank/dense_rank
这三个窗口函数的使用场景非常多
- row_number()从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列
- RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
- DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
注意: rank和dense_rank的区别在于排名相等时会不会留下空位
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM lxw1234
WHERE cookieid = 'cookie1';
LAG和LEAD函数
为常用的窗口函数,可以返回上下数据行的数据。以订单表为例,假如想要查看顾客上次的购买时间可以这样去查询
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1,
lag(orderdate,2) over (partition by name order by orderdate) as time2
from t_window;
time1取的为按照name进行分组,分组内升序排列,取上一行数据的值。time2取的为按照name进行分组,分组内升序排列,取上面2行的数据的值,注意当lag函数未设置行数值时,默认为1行。设定取不到时的默认值时,取null值。lead函数与lag函数方向相反,取向下的数据.
first_value和last_value
first_value取分组内排序后,截止到当前行,第一个值
last_value取分组内排序后,截止到当前行,最后一个值
select name,orderdate,cost,
first_value(orderdate) over(partition by name order by orderdate) as time1,
last_value(orderdate) over(partition by name order by orderdate) as time2
from t_window
Hive内部表和外部表
外部表(external table)
有external修饰,表数据保存在HDFS上,该位置由用户指定。删除表时,只会删除表的元数据,所以外部表不是有Hive完全管理的
内部表(internal table/managed table)
没有external修饰,表数据保存在Hive默认的路径下,数据完全由Hive管理,删除表时元数据和表数据都会一起删除。
区别
- 内部表数据由Hive自身管理,外部表数据由HDFS管理
- 外部表的表数据存储位置由用户指定,而内部表的数据默认存储位置为/user/hive/warehouse/数据库名.db/数据文件名
- 删除外部表时,只会删除表的元数据,表数据仍然存储在HDFS中,删除内部表时,元数据和表数据都会删除
- 对内部表修改时会同步到元数据,而对外部表结构和分区修改时,需要进行修复MSCK REPAIR TABLE table_name
使用场合
- 希望做数据备份并且不经常改变的数据,存放在外部表可以减少失误操作
- 数据清洗转换后的中间结果,可以存放在内部表,因为Hive对内部表支持的功能比较全面,方便管理
- 处理完成的数据由于需要共享,可以存储在外部表,这样能够防止失误操作,增加数据的安全性
外部表数据变动怎么和外部表建立联系?
三种方式:直接load、msck repair、上传数据之后添加分区

















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









