




 本文深入探讨了Kafka的幂等性及其实现机制,包括PID和Sequence Number的概念,以及如何保证单个Producer在单个Partition的Exactly Once语义。此外,文章还介绍了Kafka的事务特性,包括基本概念、事务流程,以及如何通过Transaction Coordinator和Transaction Marker实现跨Session的数据幂等性和事务恢复。
本文深入探讨了Kafka的幂等性及其实现机制,包括PID和Sequence Number的概念,以及如何保证单个Producer在单个Partition的Exactly Once语义。此外,文章还介绍了Kafka的事务特性,包括基本概念、事务流程,以及如何通过Transaction Coordinator和Transaction Marker实现跨Session的数据幂等性和事务恢复。
生产者幂等性
Kafka的幂等性指在发送同一条消息时,在服务端只会被持久化一次,数据不丢不重。前提条件:
- Kafka的幂等性只能保证单会话有效,如果broker挂掉重启,幂等性就无效了,因为无法获取之前的状态信息
- 幂等性不能跨多个Topic-Partition,只能保证单个partition的幂等性,如果需要跨分区实现幂等就只能借助事务性实现。
幂等性用来解决什么问题?
幂等性用来解决数据重复问题,保证Kafka单会话单分区内数据不会重复消费。在Kafka0.11之前通过isr+ack机制可保证数据不丢,却不能保证不重复。有一些情况可能会导致数据重复,比如:网络请求延时导致的重试操作,在发送请求重试时 Server 端并不知道这条请求是否已经处理(没有记录之前的状态信息),所以就会有可能导致数据请求的重复发送,这是 Kafka 自身的机制(异常时请求重试机制)导致的数据重复。
幂等性实现
配置属性
把producer的配置 enable.idempotence=ture,此时默认把acks设置为all,所以不需要再设置acks属性。
为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number:
- PID。每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的
- Sequence Numbler。(对于每个PID,该Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number
Broker端在缓存中保存了这seq number,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。但是,只能保证单个Producer对于同一个<Topic, Partition>的Exactly Once语义。不能保证同一个Producer一个topic不同的partion幂等。
这两个机制的实现过程:
producerID
Producer初始化的时候会分配一个producerID。对于一个给定的pid,sequence number会从0开始自增。每一个topic-partition都有自己的一套sequence number,client发送的每条消息都有seqnum Server根据这个seqnum判断是否重复。但是这里的PID是全局唯一的,如果client挂掉重启又会重新分配一个PID,这就是幂等性无法做到跨会话的原因。
PID 在 Server 端如何分配?Client 通过向 Server 发送一个 InitProducerIdRequest请求获取PID(幂等性时是选择一台连接数最少的 Broker 发送这个请求), Server 端如何处理这个请求的?
def handleInitProducerIdRequest(request: RequestChannel.Request): Unit = {
val initProducerIdRequest = request.body[InitProducerIdRequest]
val transactionalId = initProducerIdRequest.transactionalId
if (transactionalId != null) { //note: 设置 txn.id 时,验证对 txn.id 的权限
if (!authorize(request.session, Write, Resource(TransactionalId, transactionalId, LITERAL))) {
sendErrorResponseMaybeThrottle(request, Errors.TRANSACTIONAL_ID_AUTHORIZATION_FAILED.exception)
return
}
} else if (!authorize(request.session, IdempotentWrite, Resource.ClusterResource)) { //note: 没有设置 txn.id 时,验证对集群是否有幂等性权限
sendErrorResponseMaybeThrottle(request, Errors.CLUSTER_AUTHORIZATION_FAILED.exception)
return
}
def sendResponseCallback(result: InitProducerIdResult): Unit = {
def createResponse(requestThrottleMs: Int): AbstractResponse = {
val responseBody = new InitProducerIdResponse(requestThrottleMs, result.error, result.producerId, result.producerEpoch)
trace(s"Completed$transactionalId's InitProducerIdRequest with result$resultfrom client${request.header.clientId}.")
responseBody
}
sendResponseMaybeThrottle(request, createResponse)
}
//note: 生成相应的了 pid,返回给 producer
txnCoordinator.handleInitProducerId(transactionalId, initProducerIdRequest.transactionTimeoutMs, sendResponseCallback)
}
这里调用了TransactionCoordinator(Broker 在启动 server 服务时都会初始化这个实例)的 handleInitProducerId() 方法,幂等性的处理实现如下:
def handleInitProducerId(transactionalId: String,
transactionTimeoutMs: Int,
responseCallback: InitProducerIdCallback): Unit = {
if (transactionalId == null) { //note: 只设置幂等性时,直接分配 pid 并返回
// if the transactional id is null, then always blindly accept the request
// and return a new producerId from the producerId manager
val producerId = producerIdManager.generateProducerId()
responseCallback(InitProducerIdResult(producerId, producerEpoch = 0, Errors.NONE))
}
}
Server给Client 初始化PID实际上是通过ProducerIdManager 的 generateProducerId() 方法产生一个 PID。ProducerIdManager 是在 TransactionCoordinator 对象初始化时初始化的,这个对象主要是用来管理 PID 信息:PID的申请是向Zookeeper申请的,Zookeeper中有一个节点/latest_producer_id_block,存放PID信息。Broker向Zookeeper申请PID后都会写入这个节点,每个Broker申请前都会先读这个节点的信息,然后再分配PID,分配完将信息在写入这个节点。
ProducerIdManager 申请 PID 段的流程如下:
- 先从 Zookeeper的 /latest_producer_id_block 节点读取最新已经分配的 PID 段信息
- 如果该节点不存在,直接从 0 开始分配,选择 0~1000 的 PID 段(ProducerIdManager 的 PidBlockSize 默认为 1000,即是每次申请的 PID 段大小)
- 如果该节点存在,读取其中数据,根据 block_end 选择 这个 PID 段(如果 PID 段超过 Long 类型的最大值,这里会直接返回一个异常)
- 在选择了相应的 PID 段后,将这个 PID 段信息写回到 Zookeeper的这个节点中,如果写入成功,那么 PID 段就证明申请成功,如果写入失败(写入时会判断当前节点的 zkVersion 是否与步骤1获取的 zkVersion 相同,如果相同,那么可以成功写入,否则写入就会失败,证明这个节点被修改过),证明此时可能其他的 Broker 已经更新了这个节点(当前的 PID 段可能已经被其他 Broker 申请),那么从步骤 1 重新开始,直到写入成功
sequence numbers
有了 PID 之后,在 PID + Topic-Partition 级别上添加一个 sequence numbers 信息,就可以实现 Producer 的幂等性了。ProducerBatch 提供了一个 setProducerState() 方法,可以给一个 batch 添加一些 meta 信息(pid、baseSequence、isTransactional),这些信息是会伴随着 ProduceRequest 发到 Server 端,Server 端也正是通过这些 meta 来做相应的判断,如下所示:
// ProducerBatch
public void setProducerState(ProducerIdAndEpoch producerIdAndEpoch,int baseSequence, boolean isTransactional){
recordsBuilder.setProducerState(producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, baseSequence, isTransactional);
}
// MemoryRecordsBuilder
public void setProducerState(long producerId, short producerEpoch, int baseSequence, boolean isTransactional){
if (isClosed()) {
// Sequence numbers are assigned when the batch is closed while the accumulator is being drained.
// If the resulting ProduceRequest to the partition leader failed for a retriable error, the batch will
// be re queued. In this case, we should not attempt to set the state again, since changing the producerId and sequence
// once a batch has been sent to the broker risks introducing duplicates.
throw new IllegalStateException("Trying to set producer state of an already closed batch. This indicates a bug on the client.");
}
this.producerId = producerId;
this.producerEpoch = producerEpoch;
this.baseSequence = baseSequence;
this.isTransactional = isTransactional;
}
Client 幂等性时发送流程
- 应用通过 KafkaProducer 的 send() 方法将数据添加到 RecordAccumulator 中,添加时会判断是否需要新建一个 ProducerBatch,这时这个 ProducerBatch 还是没有 PID 和 sequence number 信息的
- Producer 后台发送线程 Sender,在 run() 方法中,会先根据 TransactionManager 的 shouldResetProducerStateAfterResolvingSequences() 方法判断当前的 PID 是否需要重置
- Sender 线程通过 maybeWaitForProducerId() 方法判断是否需要申请 PID,如果需要的话,这里会阻塞直到获取到相应的 PID 信息
- 最后调用sendProduceRequest方法将消息发送出去
幂等性时 Server 端如何处理 ProduceRequest 请求
- 如果请求是事务请求,检查是否对 TXN.id 有 Write 权限,没有的话返回 TRANSACTIONAL_ID_AUTHORIZATION_FAILED
- 如果请求设置了幂等性,检查是否对 ClusterResource 有 IdempotentWrite 权限,没有的话返回 CLUSTER_AUTHORIZATION_FAILED
- 验证对 topic 是否有 Write 权限以及 Topic 是否存在,否则返回 TOPIC_AUTHORIZATION_FAILED 或 UNKNOWN_TOPIC_OR_PARTITION 异常
- 检查是否有 PID 信息,没有的话走正常的写入流程
- LOG 对象会在 analyzeAndValidateProducerState() 方法先根据 batch 的 sequence number 信息检查这个 batch 是否重复(server 端会缓存 PID 对应这个 Topic-Partition 的最近5个 batch 信息),如果有重复,这里当做写入成功返回(不更新 LOG 对象中相应的状态信息,比如这个 replica 的 the end offset 等)
- 有了 PID 信息,并且不是重复 batch 时,在更新 producer 信息时,会做以下校验:
a】检查该 PID 是否已经缓存中存在(主要是在 ProducerStateManager 对象中检查)
b】如果不存在,那么判断 sequence number 是否 从0 开始,是的话,在缓存中记录 PID 的 meta(PID,epoch, sequence number),并执行写入操作,否则返回 UnknownProducerIdException(PID 在 server 端已经过期或者这个 PID 写的数据都已经过期了,但是 Client 还在接着上次的 sequence number 发送数据);
c】如果该 PID 存在,先检查 PID epoch 与 server 端记录的是否相同;
d】如果不同并且 sequence number 不从 0 开始,那么返回 OutOfOrderSequenceException 异常;
e】如果不同并且 sequence number 从 0 开始,那么正常写入;
f】如果相同,那么根据缓存中记录的最近一次 sequence number(currentLastSeq)检查是否为连续(会区分为 0、Int.MaxValue 等情况),不连续的情况下返回 OutOfOrderSequenceException 异常。
幂等性时,Broker 在处理 ProduceRequest 请求时,多了一些校验操作。analyzeAndValidateProducerState() 方法的实现,如下所示:
private def analyzeAndValidateProducerState(records: MemoryRecords, isFromClient: Boolean): (mutable.Map[Long, ProducerAppendInfo], List[CompletedTxn], Option[BatchMetadata]) = {
val updatedProducers = mutable.Map.empty[Long, ProducerAppendInfo]
val completedTxns = ListBuffer.empty[CompletedTxn]
for (batch <- records.batches.asScala if batch.hasProducerId) { //note: 有 pid 时,才会做相应的判断
val maybeLastEntry = producerStateManager.lastEntry(batch.producerId)
// if this is a client produce request, there will be up to 5 batches which could have been duplicated.
// If we find a duplicate, we return the metadata of the appended batch to the client.
if (isFromClient) {
maybeLastEntry.flatMap(_.findDuplicateBatch(batch)).foreach { duplicate =>
return (updatedProducers, completedTxns.toList, Some(duplicate)) //note: 如果这个 batch 已经收到过,这里直接返回
}
}
val maybeCompletedTxn = updateProducers(batch, updatedProducers, isFromClient = isFromClient) //note: 这里
maybeCompletedTxn.foreach(completedTxns += _)
}
(updatedProducers, completedTxns.toList, None)
}
如果这个 batch 有 PID 信息,会首先检查这个 batch 是否为重复的 batch 数据,其实现如下,batchMetadata 会缓存最新 5个 batch 的数据(如果超过5个,添加时会进行删除,这个也是幂等性要求MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 小于等于5 的原因,与这个值的设置有关),根据 batchMetadata 缓存的 batch 数据来判断这个 batch 是否为重复的数据。如果 batch 不是重复的数据,analyzeAndValidateProducerState() 会通过 updateProducers() 更新 producer 的相应记录,在更新的过程中,会做一步校验,校验
存在两个问题:
- Producer 在设置幂等性时,为什么要求MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 小于等于 5,如果设置大于 5(不考虑 Producer 端参数校验的报错),会带来什么后果?
要求 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 小于等于 5 的主要原因是:Server 端的 ProducerStateManager 实例会缓存每个 PID 在每个 Topic-Partition 上发送的最近 5 个batch 数据,如果超过 5,ProducerStateManager 就会将最旧的 batch 数据清除。假设应用将 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 设置为 6,假设发送的请求顺序是 1、2、3、4、5、6,这时候 Server 端只能缓存 2、3、4、5、6 请求对应的 batch 数据,这时候假设请求 1 发送失败,需要重试,当重试的请求发送过来后,首先先检查是否为重复的 batch,这时候检查的结果是否,之后会开始 check 其 sequence number 值,这时候只会返回一个OutOfOrderSequenceException 异常,Client 在收到这个异常后,会再次进行重试,直到超过最大重试次数或者超时,这样不但会影响 Producer 性能,还可能给 Server 带来压力(相当于Client 不断发送错误请求)。
更好的方案是对于 OutOfOrderSequenceException 异常,再进行细分,区分这个 sequence number 是大于 nextSeq (期望的下次 sequence number 值)还是小于 nextSeq,如果是小于,那么肯定是重复的数据。
- Producer 在设置幂等性时,如果设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 大于 1,那么是否可以保证有序,如果可以,是怎么做到的?
在什么情况下 Producer 会出现乱序的问题?没有幂等性时,乱序的问题是在重试时出现的,举个例子:C lient 依然发送了 6 个请求 1、2、3、4、5、6(它们分别对应了一个 batch),这 6 个请求只有 2-6 成功 ack 了,1 失败了,这时候需要重试,重试时就会把 batch 1 的数据添加到待发送的数据列队中),那么下次再发送时,batch 1 的数据将会被发送,这时候数据就已经出现了乱序,因为 batch 1 的数据已经晚于了 batch 2-6。
当 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 设置为 1 时,是可以解决这个为题,因为同时只允许一个请求正在发送,只有当前的请求发送完成(成功 ack 后),才能继续下一条请求的发送,类似单线程处理这种模式,每次请求发送时都会等待上次的完成,效率非常差,但是可以解决乱序的问题(当然这里有序只是针对单 client 情况,多 client 并发写是无法做到的)。
系统能提供的方案,基本上就是有序性与性能之间二选一,无法做到兼容,实际上系统出现请求重试的几率是很小的(一般都是网络问题触发的),可能连 0.1% 的时间都不到,但是就是为了这 0.1% 时间都不到的情况,应用需要牺牲性能问题来解决,在大数据场景下,应该有更友好的方式来解决这个问题。简单来说,就是当出现重试时,max-in-flight-request 可以动态减少到 1,在正常情况下还是按 5 来处理,这有点类似于分布式系统 CAP 理论中关于 P 的考虑,当出现问题时,可以容忍性能变差,但是其他的情况下,希望的是能拥有原来的性能。令人高兴的,在 Kafka 2.0.0 版本中,如果 Producer 开始了幂等性,Kafka 是可以做到这一点的,如果不开启幂等性,是无法做到的,因为它的实现是依赖了 sequence number。
当请求出现重试时,batch 会重新添加到队列中,这时候是根据 sequence number 添加到队列的合适位置(有些 batch 如果还没有 sequence number,那么就保持其相对位置不变),也就是队列中排在这个 batch 前面的 batch,其 sequence number 都比这个 batch 的 sequence number 小,其实现如下,这个方法保证了在重试时,其 batch 会被放到合适的位置。
简单来说,其实现机制概括为:
- Server 端验证 batch 的 sequence number 值,不连续时,直接返回异常
- Client 端请求重试时,batch 在 reenqueue 时会根据 sequence number 值放到合适的位置(有序保证之一)
- Sender 线程发送时,在遍历 queue 中的 batch 时,会检查这个 batch 是否是重试的 batch,如果是的话,只有这个 batch 是最旧的那个需要重试的 batch,才允许发送,否则本次发送跳过这个 Topic-Partition 数据的发送等待下次发送
Kafka事务特性
问:如果有一条offset对应的数据,消费完成之后,手动提交失败,如何处理?
答:回滚,利用Kafka的事务解决。
幂等设计只能保证单个Producer对于同一个<Topic, Partition>的Exactly Once语义。Kafka 事务属性是指一系列的生产者生产消息和消费者提交偏移量的操作在一个原子操作,要么全部成功,要么全部失败,即使该生产或消费跨多个<Topic, Partition>。
Kafka事务引入了transactionId 和Epoch,设置transactional.id后,一个transactionId只对应一个pid, 且为了保证新的 Producer 启动后,旧的具有相同Transaction ID的 Producer 即失效,每次 Producer 通过Transaction ID拿到 PID 的同时,还会获取一个单调递增的 epoch。由于旧的 Producer 的 epoch 比新 Producer 的 epoch 小,Kafka 可以很容易识别出该 Producer 是老的 Producer 并拒绝其请求。
基本概念
为了支持事务,Kafka 0.11.0版本引入以下概念:
1、事务协调者:Transaction Coordinator,用于管理Producer发送的消息的事务性。该Transaction Coordinator维护Transaction Log,该log存于一个内部的Topic内。由于Topic数据具有持久性,因此事务的状态也具有持久性。Producer并不直接读写Transaction Log,它与Transaction Coordinator通信,然后由Transaction Coordinator将该事务的状态插入相应的Transaction Log。Transaction Log的设计与Offset Log用于保存Consumer的Offset类似
2、Control Messages:为了区分写入Partition的消息被Commit还是Abort,Kafka引入了Control Message。该类消息的Value内不包含任何应用相关的数据,并且不会暴露给应用程序。它只用于Broker与Client间的内部通信。对于Producer端事务,Kafka以Control Message的形式引入一系列的Transaction Marker。Consumer即可通过该标记判定对应的消息被Commit了还是Abort了,然后结合该Consumer配置的隔离级别决定是否应该将该消息返回给应用程序
3、引入TransactionId:有了Transaction ID后,Kafka可保证:
- 跨Session的数据幂等发送。当具有相同Transaction ID的新的Producer实例被创建且工作时,旧的且拥有相同Transaction ID的Producer将不再工作
- 跨Session的事务恢复。如果某个应用实例宕机,新的实例可以保证任何未完成的旧的事务要么Commit要么Abort,使得新实例从一个正常状态开始工作
事务流程
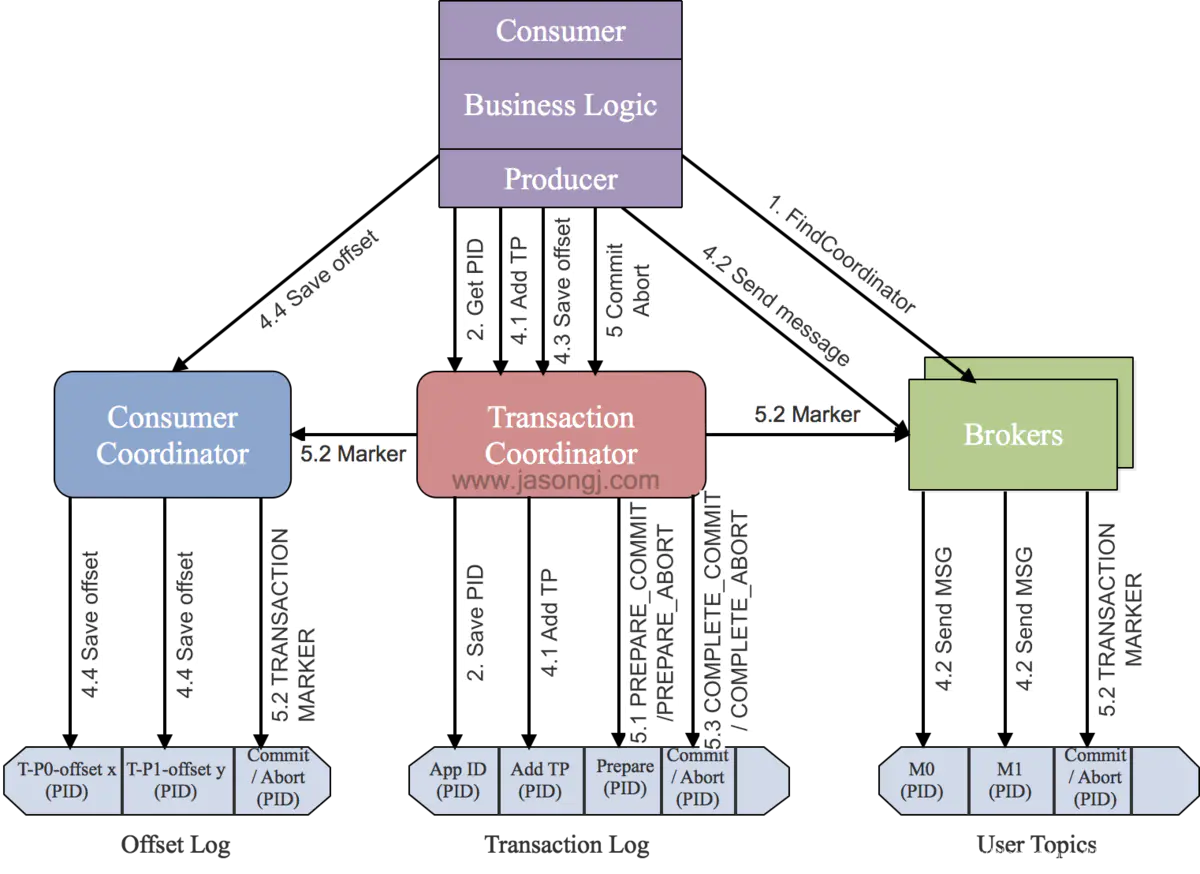
1、查找事务协调者
Producer要做的第一件事情就是通过向任意一个Broker发送FindCoordinator请求找到Transaction Coordinator的位置
2、获取produce ID
找到Transaction Coordinator后,具有幂等特性的Producer必须发起InitPidRequest请求以获取PID。这个请求分两种情况:
如果事务特性被开启
InitPidRequest会发送给Transaction Coordinator。如果Transaction Coordinator是第一次收到包含有该Transaction ID的InitPidRequest请求,它将会把该<TransactionID, PID>存入Transaction Log。这样可保证该对应关系被持久化,从而保证即使Transaction Coordinator宕机该对应关系也不会丢失。
除了返回PID外,InitPidRequest还会执行如下任务:
- 增加该PID对应的epoch。具有相同PID但epoch小于该epoch的其它Producer新开启的事务将被拒绝
- 恢复(Commit或Abort)之前的Producer未完成的事务
注意:InitPidRequest的处理过程是同步阻塞的。一旦该调用正确返回,Producer即可开始新的事务。
如果事务特性未开启
InitPidRequest可发送至任意Broker,并且会得到一个全新的唯一的PID。该Producer将只能使用幂等特性以及单一Session内的事务特性,而不能使用跨Session的事务特性。
3、启动事务
生产者通过调用beginTransaction接口启动事务。调用该方法后,Producer本地会记录已经开启了事务,但Transaction Coordinator只有在Producer发送第一条消息后才认为事务已经开启。
4、消费和生产配合过程
这一步是消费和生成互相配合完成事务的过程,其中涉及多个请求:
●AddPartitionsToTxnRequest(增加分区到事务请求)
一个Producer可能会给多个<Topic, Partition>发送数据,给一个新的<Topic, Partition>发送数据前,它需要先向Transaction Coordinator发送AddPartitionsToTxnRequest。Transaction Coordinator会将该<Transaction, Topic, Partition>存于Transaction Log内,有了该信息后,才可以在后续步骤中为每个Topic, Partition>设置COMMIT或者ABORT标记
●ProduceRequest(生产请求)
Producer通过一个或多个ProduceRequest发送一系列消息。除了应用数据外,该请求还包含了PID,epoch,和Sequence Number
●AddOffsetsToTxnRequest(增加消费offset到事务)
生产者通过新增的sendOffsetsToTransaction方法,会发送某个分区的Offset信息到Transaction Coordinator,Transaction Coordinator将对应的所有<Topic, Partition>存于Transaction Log中,并将其状态记为BEGIN
●TxnOffsetCommitRequest(事务提交offset请求)
当生产者调用事务提交offset接口后,会发送一个TxnOffsetCommit请求给Consumer Coordinator,消费组协调者会把offset存储在consumer-offsets Topic中。Consumer Coordinator会根据请求的PID和epoch验证生产者是否允许发起这个请求。 消费offset只有当事务提交后才对外可见
5、提交或回滚事务
一旦上述数据写入操作完成,应用程序必须调用KafkaProducer的commitTransaction方法或者abortTransaction方法提交或回滚事务。
●EndTxnRequest
commitTransaction方法使得Producer写入的数据对下游Consumer可见。abortTransaction方法通过Transaction Marker将Producer写入的数据标记为Aborted状态。下游的Consumer如果将isolation.level设置为READ_COMMITTED,则它读到被Abort的消息后直接将其丢弃而不会返回给客户程序,也即被Abort的消息对应用程序不可见
无论是Commit还是Abort,Producer都会发送EndTxnRequest请求给Transaction Coordinator,并通过标志位标识是应该Commit还是Abort
●WriteTxnMarkerRequest
这个请求由Transaction Coordinator发送给当前事务涉及到的每个<Topic, Partition>的Leader。收到该请求后,对应的Leader会将对应的COMMIT(PID)或者ABORT(PID)控制信息到数据日志中
该控制消息向Broker以及Consumer表明对应PID的消息被Commit了还是被Abort了
这里要注意,如果事务也涉及到__consumer_offsets,即该事务中有消费数据的操作且将该消费的Offset存于__consumer_offsets中,Transaction Coordinator也需要向该内部Topic的各Partition的Leader发送WriteTxnMarkerRequest从而写入COMMIT(PID)或COMMIT(PID)控制信息
●写入最终提交或回滚信息
写完所有的Transaction Marker后,Transaction Coordinator会将最终的COMPLETE_COMMIT或COMPLETE_ABORT消息写入Transaction Log中以标明该事务结束,此时Transaction Log中所有关于该事务的消息全部可以移除
总结:
- PID与Sequence Number的引入实现了写操作的幂等性
- 写操作的幂等性结合At Least Once语义实现了单一Session内的Exactly Once语义
- Transaction Marker与PID提供了识别消息是否应该被读取的能力,从而实现了事务的隔离性
- Offset的更新标记了消息是否被读取,从而将对读操作的事务处理转换成了对写(Offset)操作的事务处理
- Kafka事务的本质是,将一组写操作对应的消息与一组读操作对应的Offset的更新进行同样的标记(即Transaction Marker)来实现事务中涉及的所有读写操作同时对外可见或同时对外不可见
Kafka与Zookeeper比较:
Zookeeper的原子广播协议与两阶段提交以及Kafka事务机制有相似之处,但又有各自的特点:
- Kafka事务可COMMIT也可ABORT。而Zookeeper原子广播协议只有COMMIT没有ABORT
- Kafka存在多个Transaction Coordinator实例,扩展性较好。而Zookeeper写操作只能在Leader节点进行,所以其写性能远低于读性能
- Kafka事务是COMMIT还是ABORT完全取决于Producer即客户端。而Zookeeper原子广播协议中某条消息是否被COMMIT取决于是否有一大半FOLLOWER ACK该消息

















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









