




 本文介绍了Spark中的两种共享变量——广播变量和累加器,旨在解决跨任务读写共享变量的效率问题。广播变量适用于在Executor端读取的场景,避免了大对象分发带来的网络负担;累加器则用于Executor中写入,Driver端读取的计数或求和操作。文中详细阐述了广播变量的实现原理,包括数据分块、BlockManager存储、分布式获取和校验等步骤,以及累加器的定义和使用注意事项。
本文介绍了Spark中的两种共享变量——广播变量和累加器,旨在解决跨任务读写共享变量的效率问题。广播变量适用于在Executor端读取的场景,避免了大对象分发带来的网络负担;累加器则用于Executor中写入,Driver端读取的计数或求和操作。文中详细阐述了广播变量的实现原理,包括数据分块、BlockManager存储、分布式获取和校验等步骤,以及累加器的定义和使用注意事项。
Spark两种共享变量:广播变量与累加器。广播变量可以在Driver程序中写入,在Executor端读取。累加器在Executor中写入,而在Driver端读取。
共享变量出现的原因:通常,当在远程集群节点上执行传递给Spark操作的函数时,它将在函数中使用的所有变量的单独副本上工作。这些变量将复制到每台计算机,而且远程机器上的变量的更新不会同步给Driver端。这种情况下,跨任务读写共享变量效率低下。Spark使用共享变量(广播变量和累加器)来解决问题。
广播变量
为什么要将变量定义成广播变量?如果要在分布式计算里面分发大对象,例如:字典,集合等,这个都会由Driver端进行分发。一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么只是每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
注意:
1、能不能将一个RDD使用广播变量广播出去?
不能,广播变量的值必须是本地的可序列化的值,而不是RDD或其他分布式数据结构。
2、 广播变量只能在Driver端定义,不能在Executor端定义
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值
Broadcast的实现
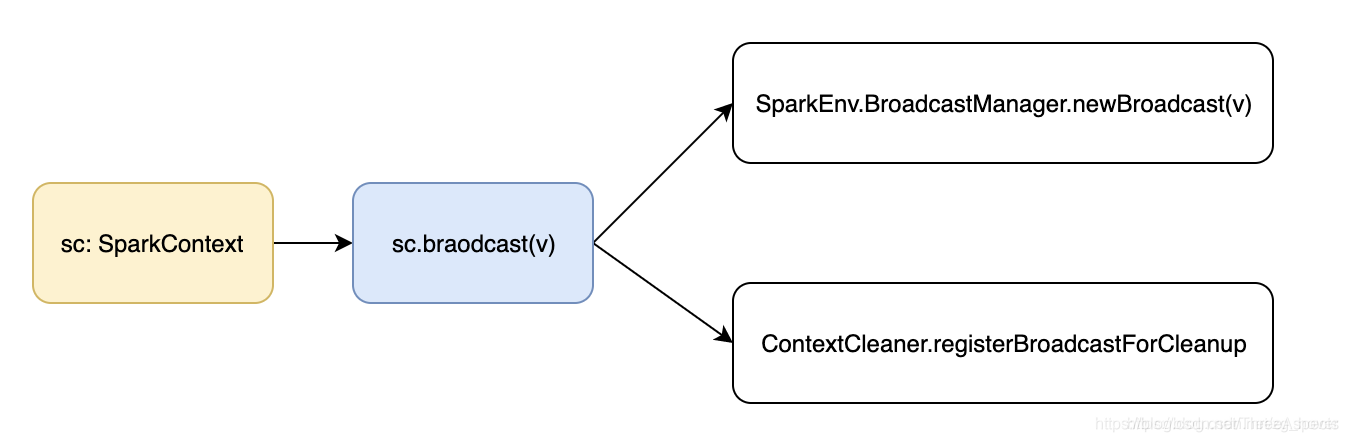
在SparkContext上调用broadcast来创建广播变量:
val a = 3
val broadcast = sc.broadcast(a)
Spark context初始化的时候, sparkEnv中初始化了一个broadcastManager,初始化方法里面默认使用的 TorrentBroadcastFactory, 调用 sc.broadcast 方法, 就会使用工厂模式创建一个TorrentBroadcast。这时候就会调用写操作,把数据分成小块写到 BlockManager 中,broadcast只是一个TorrentBroadcast 类型的实例, 并没有数组数据, 这个实例只维护了数据的元信息, 即一组BlockId 信息。这个实例被序列化被传到 executor上,在 executor 上调用这个实例的 value 方法,才会触发去 BlockManager 上读真正的数据。
TorrentBroadcastFactory工厂类实现了一个类似于BitTorrent的协议,通过该协议把广播数据分发到各个executor中。这些操作其实是在类TorrentBroadcast中实现。该类实现了以下的机制:
- TorrentBroadcast 底层使用的是 BlockManager, 下载每个数据块先要去 master 去获取 Block 所在的位置
- 在把大变量写到广播变量的时候,通过ChunkedByteBufferOutputStream把输入的数据分成多个小块,zipWithIndex中,为每个小块加一个唯一标识作为BlockId, 存储在 BlockManager 中,而且对每个小的数据块加上一个校验码
- BlockManagerMaster 作为 tracker 维护所有 Block块的元信息, 知道每个数据块所在的 executor和存储级别。 Broadcast 变量中维护属于自己的所有小块的 BlockId
- 通过 value 方法读取 Boradcast 变量的时候, 取出所有小块的 BlockId, 对于每个 BlockId, 通过BlockManagerMaster 获取了该BlockId的位置的集合, 随机化,位置集合被打乱,优先找同主机的地址,然后从随机的地址集合按顺序取地址一个一个尝试去获取数据,因为随机化了地址,那么executor不只会从Driver去获取数据。分散了driver 上的压力
- 取到 Block piece 后, 使用校验码进行校验,看看数据块有没有损坏, 如果没有损坏, 然后按照顺序拼在一起。
广播变量的回收
在调用 sc.Broadcast 方法中, 会去 ContextCleaner 中注册一下,cleaner.foreach(_.registerBroadcastForCleanup(bc)) 。当广播变量引用为null的时候, 在context cleaner 里面会回调 broadcastManager.unbroadcast 方法, 会把 Broadcast 变量从 BlockManager 存储中干掉。
累加器
为什么要将一个变量定义为一个累加器?在Spark应用程序中,经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会在Driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
定义一个累加器:
val a = sc.accumulator(0)
注意:累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。

















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









