




1.适用情景
形如如下格式的题目:
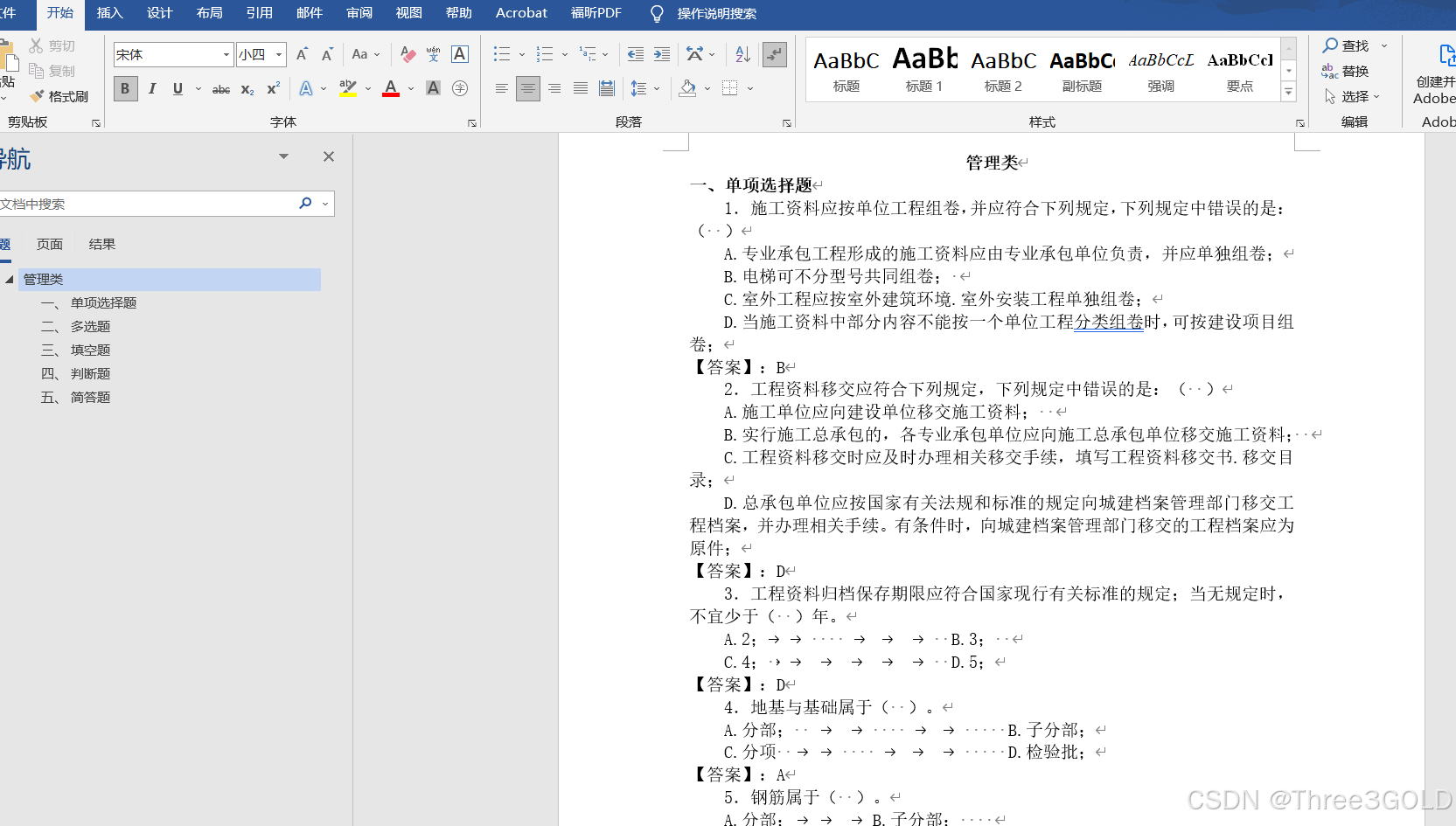
2.matlab脚本
2.1单选、多选、填空
clc,clear
title1={'管理','钢结构','土建'};
title2={'单选','多选','填空'};
%%
for ki=1:3
for kj=1:2
path='F:\wjy0907\work\w0910_GaoHan\附件2:中建n局2024年技术质量知识题库';
fileName=[path,'\',title1{ki},title2{kj},'.txt'];
fileNameW=[fileName(1:end-4),'_select.txt'];
%% read
fid=fopen(fileName,"r");
tiMuNum=0;
str=fgetl(fid);
while strcmp(str,'DFend')==0
loc=find(str=='.');
if isempty(loc)
loc=find(str=='.');
end
if isempty(loc)
qNum=tiMuNum;
tiMu=str;
else
qNum=str2double(str(1:(loc(1)-1)));
tiMu=str((loc(1)+1):end);
end
str=fgetl(fid);
%
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6848
6848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









