




大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
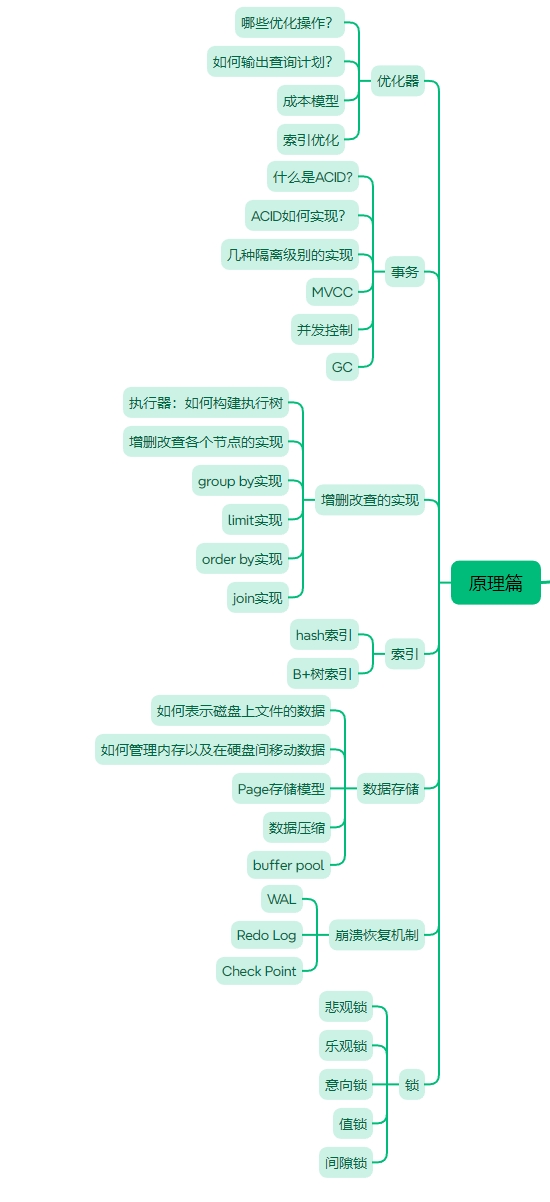
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习。
基础篇和应用篇已经更新完成。
接下来是原理篇,原理篇的内容大致如下图所示。
零基础MySQL教程原理篇之缓冲池原理及实现
MySQL中的buffer pool(缓冲池)是InnoDB存储引擎的重要组件,它负责在内存中管理数据库中的数据和索引的缓存。
它加速了数据库的运行速度,是数据库和磁盘之间的一个中间层。如果没有缓冲池,那么所有的数据库操作都需要进行磁盘IO,有了缓冲池,就不需要频繁的IO操作了。
缓冲池重点在于两个部分
- 时间管理
- 空间管理
时间管理
- 将数据写入磁盘的何处
- 目标是经常被一起使用的pages放在磁盘中也是一起的地方。
空间管理
- 何时将pages读入内存,何时将pages写入磁盘
- 目标是最小化的解决必须从磁盘读取数据这个事
同样的一个内存块在不同的地方,就有不同的叫法,比如在磁盘中,存储数据库中的数据,我们叫做page(页),而放在缓冲池中,就叫frame(帧)。
一个frame其实就是一页数据。只不过这个数据是在缓冲池中的.
到这里有个问题了,那就是缓冲池里面都是一堆数据,可是MySQL怎么知道缓冲池的哪个frame里面有数据,哪个没有呢?frame里面的数据对应的是具体哪个page的数据呢?
因此,就需要另外一个组件了,叫做page table,本质上就是一个hash map。这个page table记录了页数据在当前缓冲池中的位置,通过page table 和 page id可以知道在哪个frame中。
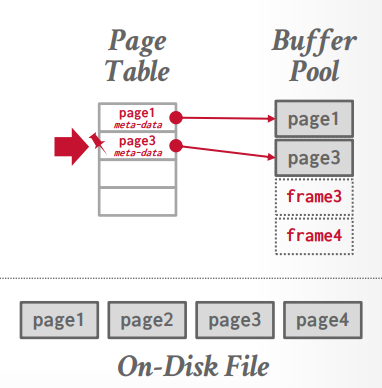
我们还需要记录一些元数据,这些数据也有着重要的作用:
- dirty flag: 记录是否被修改过,也就是常说的"脏数据标记"
- 引用计数器: 记录有多少线程在使用这个数据
- 访问追踪信息
缓冲池和mmap
如果你学过操作系统这个课,那么你看到这里,是不是觉得缓冲池很像一个东西?
没错,就是mmap。那为什么MySQL要使用自己实现的缓冲池呢?这是因为相比于mmap来说,自定义的缓冲池可以更加完美的控制,达到自己想要的效果。这也是很多大厂会自研很多组件的原因,更加适配自己的生态系统,并可以进行一些性能优化。
从下面几个点来看:
- 事务安全:如果使用mmap,操作系统完全控制page的写入,刷新,有可能在一个事务没有完成的时候有些数据就已经写入磁盘了。
- IO停顿:MySQL不知道哪些page在内存中,当读取不在内存中的时候触发
page fault,操作系统才会从磁盘获取。 - 错误处理:任何访问都可能触发操作系统的中断信号
SIGBUS,而整个MySQL都需要处理它。 - 性能问题: 没有办法实现独特的性能优化。
性能优化有两种考虑策略,分别是全局策略和局部策略。
全局策略
- 针对所有的查询或者事务的策略
局部策略
- 针对单个查询或者事务的策略
- 可以对单个优化,虽然对全局可能不好
淘汰策略
既然MySQL自己实现了一个缓冲池作为磁盘数据的缓存,那么就像我们日常使用Redis作为缓存一样,也是需要有一个淘汰策略的,毕竟,缓冲池满了怎么办?总不能MySQL不工作了吧。
淘汰策略有几种算法
- LRU:著名的LRU算法,这里不过多介绍了。
- Clock:Linux使用的,把所有的page放成一个圈,每个page有一个标志位,如果为0表示没有被使用过,1被使用过,淘汰的时候淘汰0的,再把1改成0.
- LRU-K:记录使用的次数k,达到次数才放到缓存里面,淘汰的时候比对两次的时间间隔,间隔长的认为是最近最少使用。这个基本上是MySQL使用的一个淘汰算法。属于LRU算法的变种。
- PRIORIT
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1737
1737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









