




 本文探讨了线性回归中过拟合和欠拟合的问题及其解决方法,分析了特征选择对模型复杂度的影响,并介绍了两种正则化技术:L1和L2正则化。
本文探讨了线性回归中过拟合和欠拟合的问题及其解决方法,分析了特征选择对模型复杂度的影响,并介绍了两种正则化技术:L1和L2正则化。
1 本文主要解决两个问题
- 在线性回归中过拟合和欠拟合的原因以及解决方法
- 线性回归(不带正则化)的缺点
2 对于第一个问题的解决:
首先看过拟合和欠拟合的定义:
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合,
但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
然后思考——是什么原因导致模型复杂?
对于线性回归是根据特征。进行回归预测的。如果存在很多无用的特征或者现实中的事物特征跟目标值的关系并不是简单的线性关系,就会使模型变得复杂。
最后是问题得解决:
欠拟合原因以及解决办法
- 原因:学习到数据的特征过少
- 解决办法:增加数据的特征数量
过拟合原因以及解决办法
- 原因:原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
- 解决办法: 正则化
3 对第二个问题的解决
由上面我们可以知道,解决过拟合的办法是正则化,那什么是正则化?
正则化说到就是对特征的处理——合并/删除等
为了方便理解,一个线性拟合的过程可以用下图进行表示:
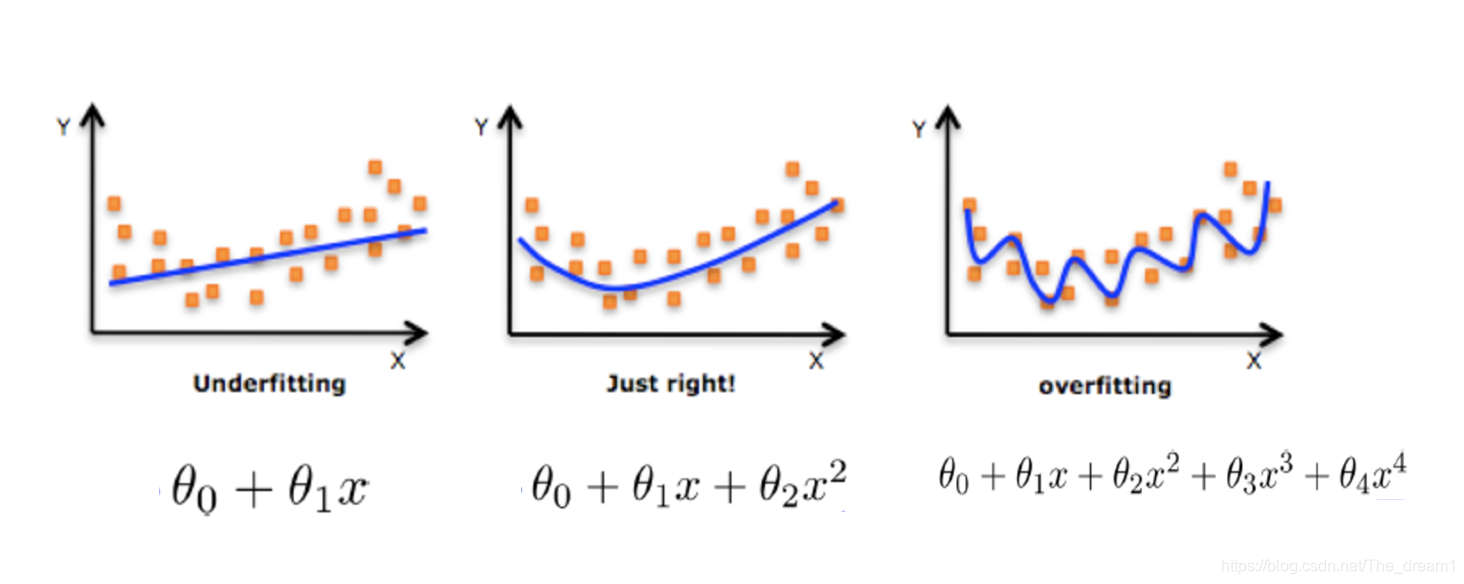
正则化是如何解决overfitting(过拟合)?

补充(2种正则化):
L2正则化
- 作用:可以使得其中一些W的都很小,都接近于0,削弱某个特征的影响
- 优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象 Ridge回归
L1正则化
- 作用:可以使得其中一些W的值直接为0,删除这个特征的影响
- LASSO回归

















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









