



因为改知识库是基于Ollama 的所以需要先安装Ollama.
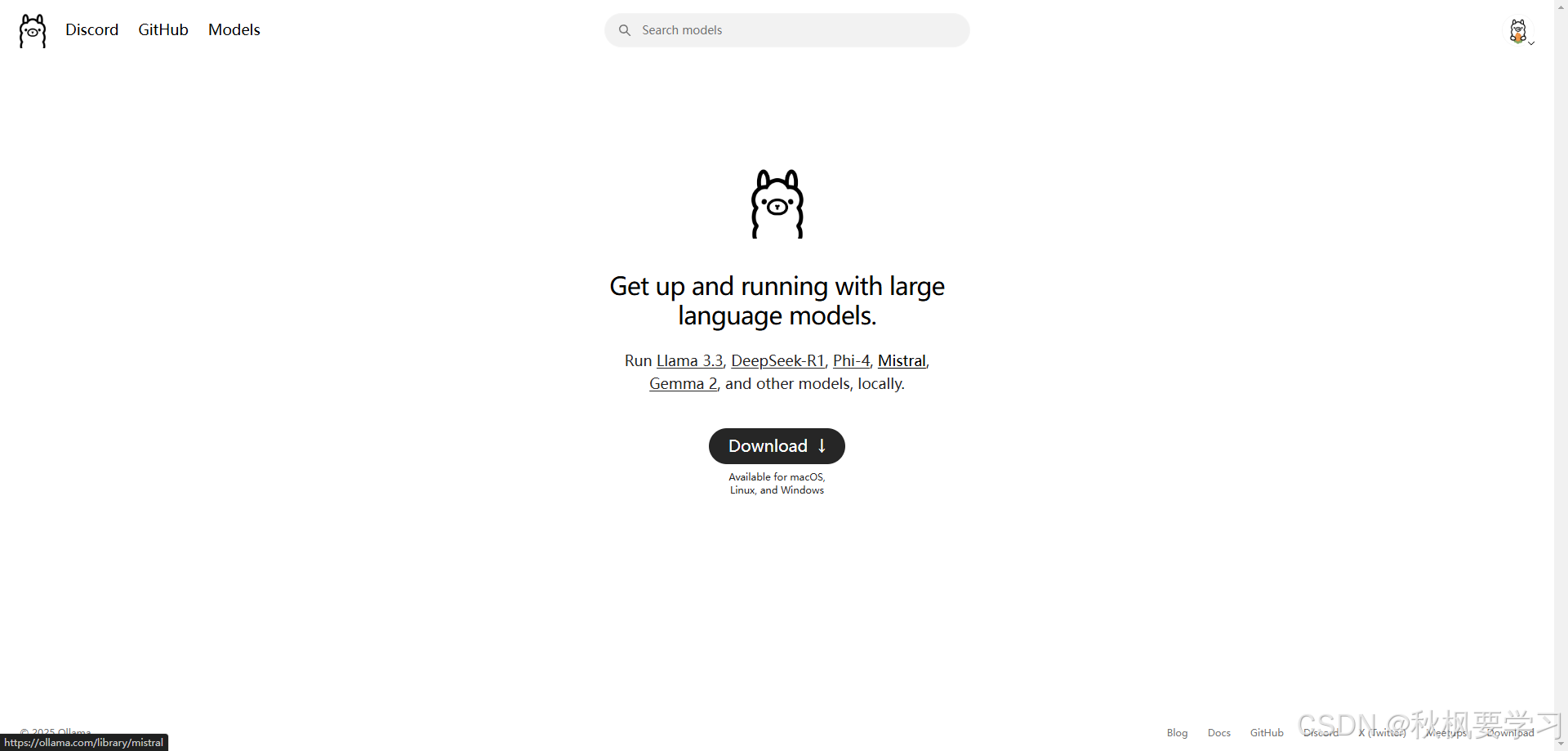
首先需要在 Ollama 官网下载对应的程序
https://ollama.com/download
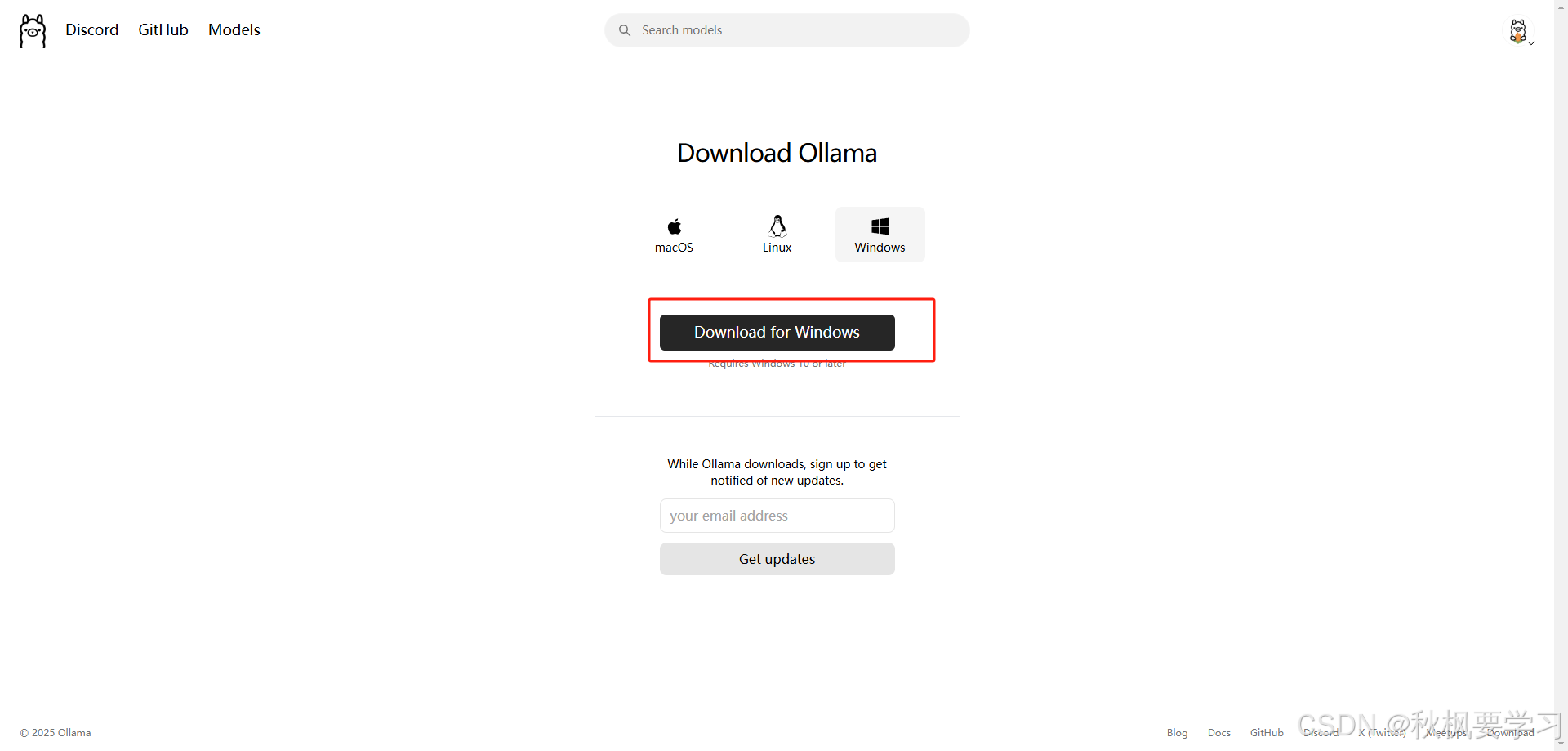
下载好后安装
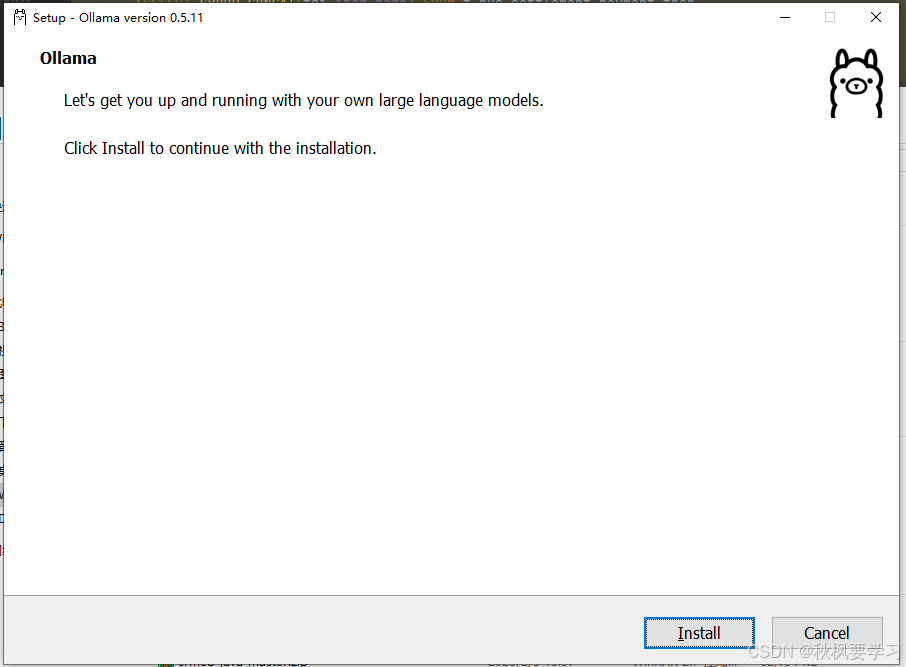
点击install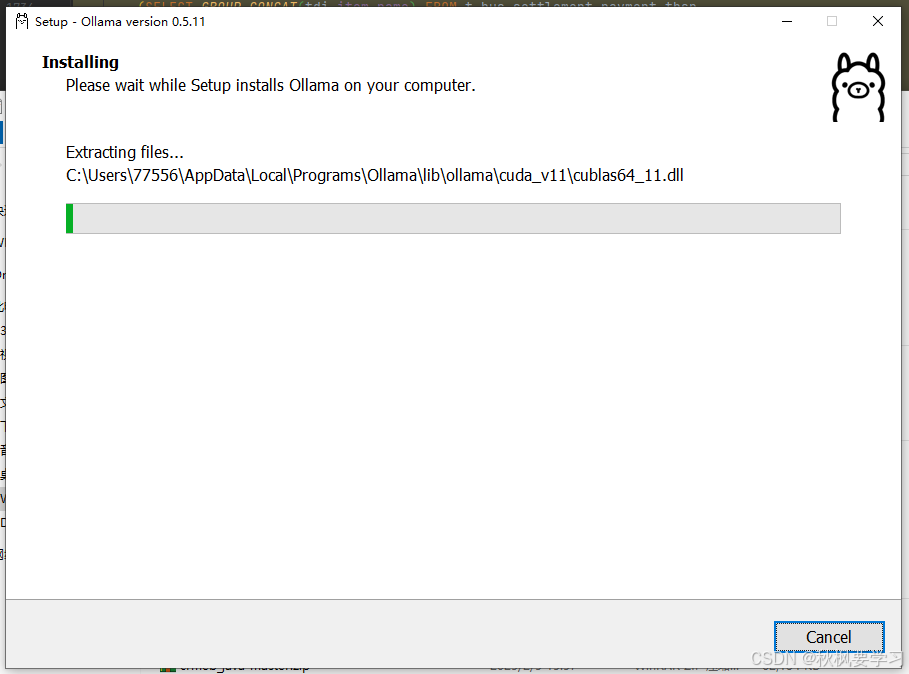
会自主选择系统盘符
安装完成后打开命令行 搜索框输入cmd
输入一下内容查看版本
ollama -v
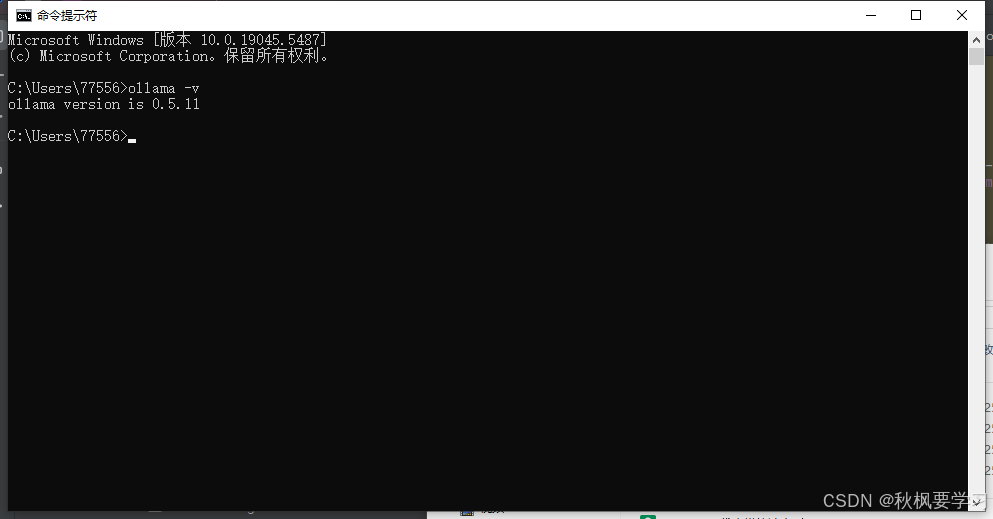
出现以上就说明ollama 已经安装完毕了,下面要安装知识库了
点击官网的这个
https://ollama.com/
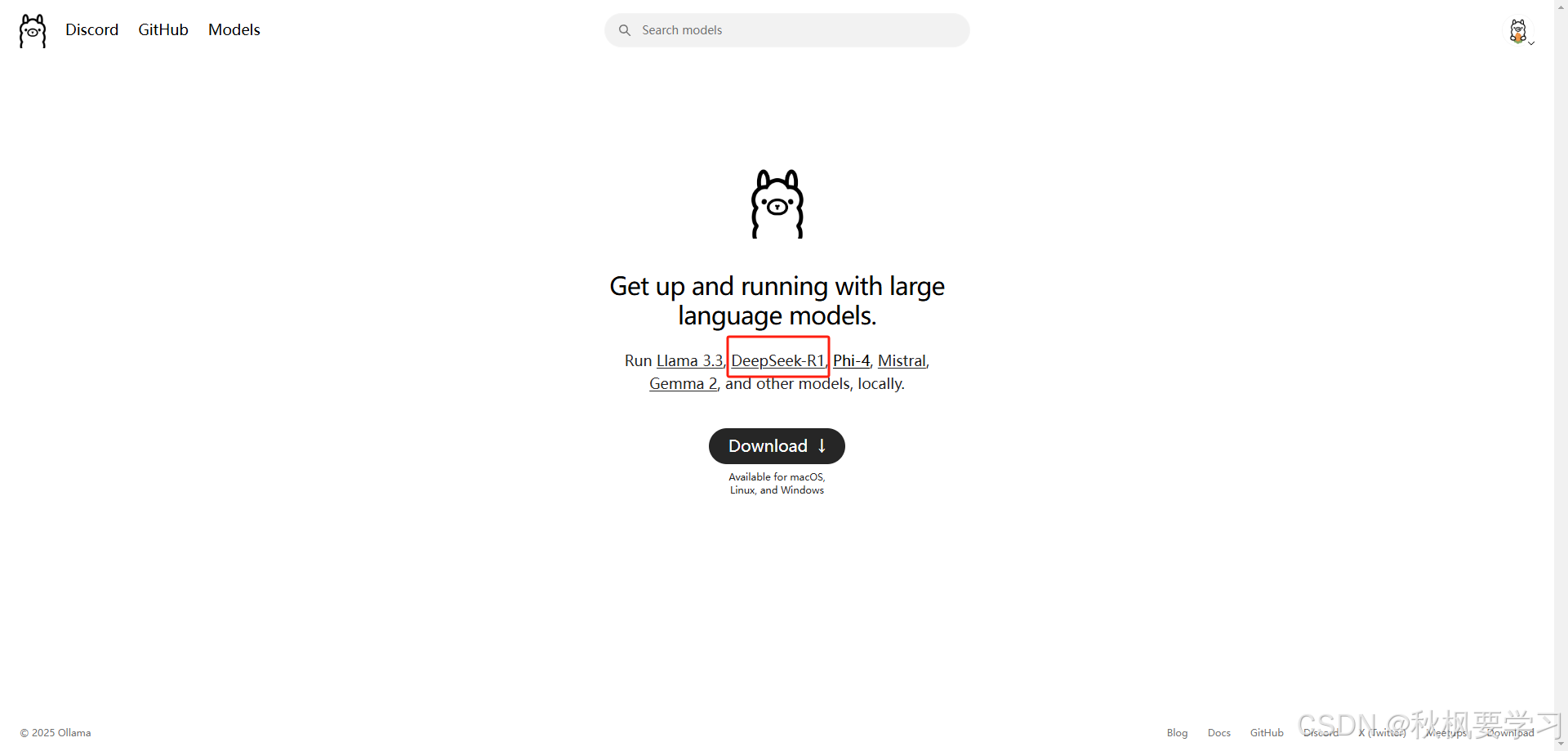
https://ollama.com/library/deepseek-r1
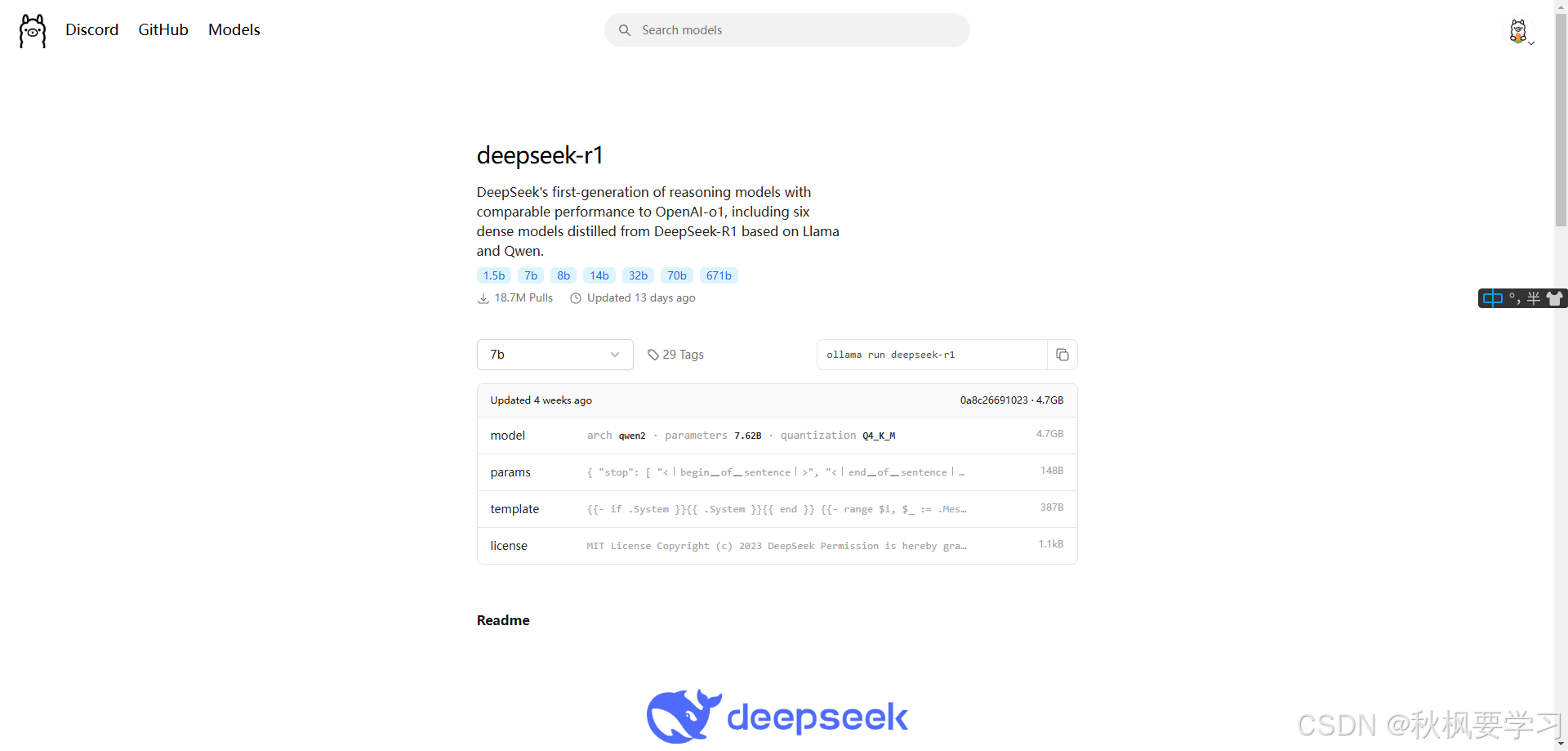
会跳转到这个页面
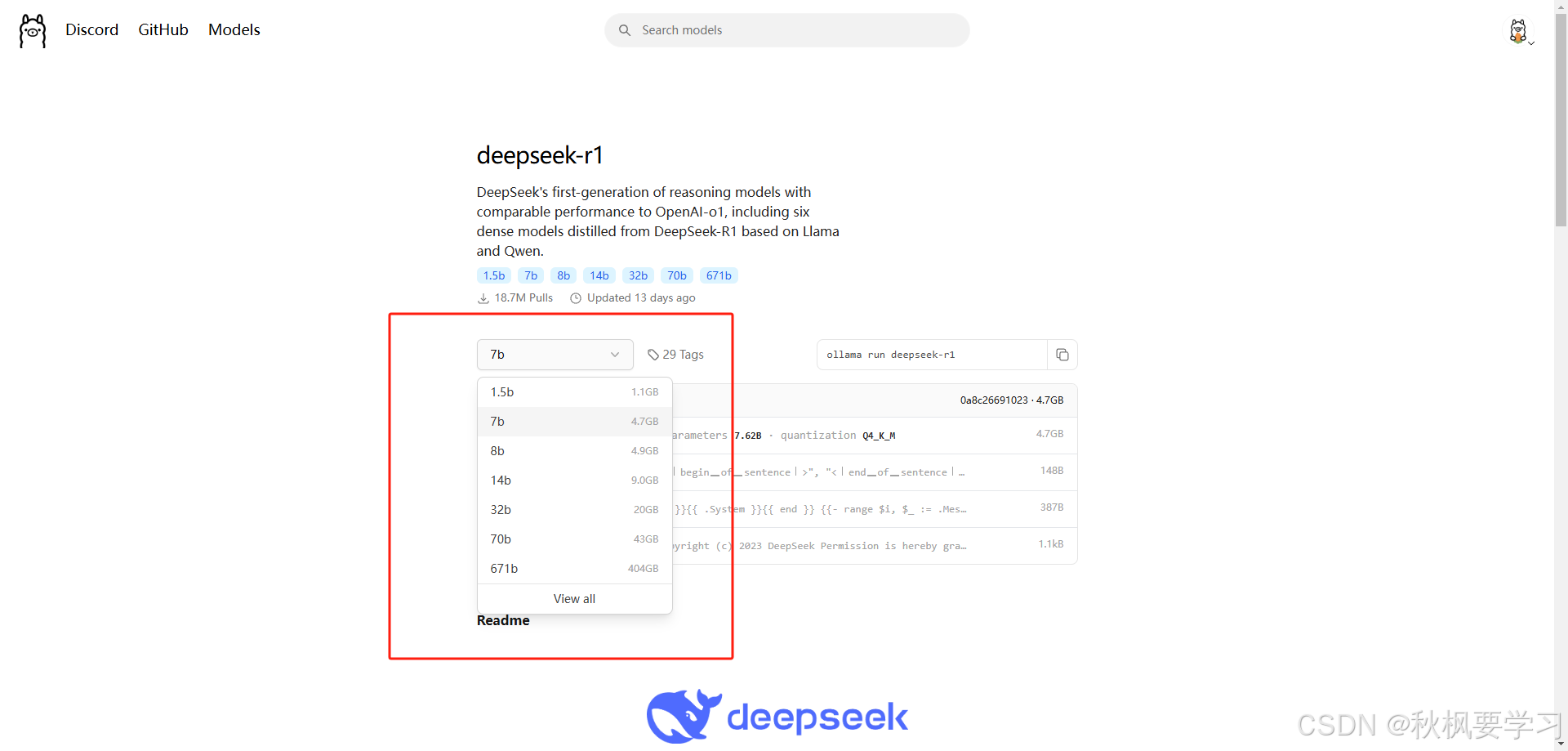
这里可以根据自己设备的配置选择不同大小的知识库。越大的知识库需要耗费的资源越高,请谨慎选择,这里选择的是 7b这个版本的知识库
往下面滚动
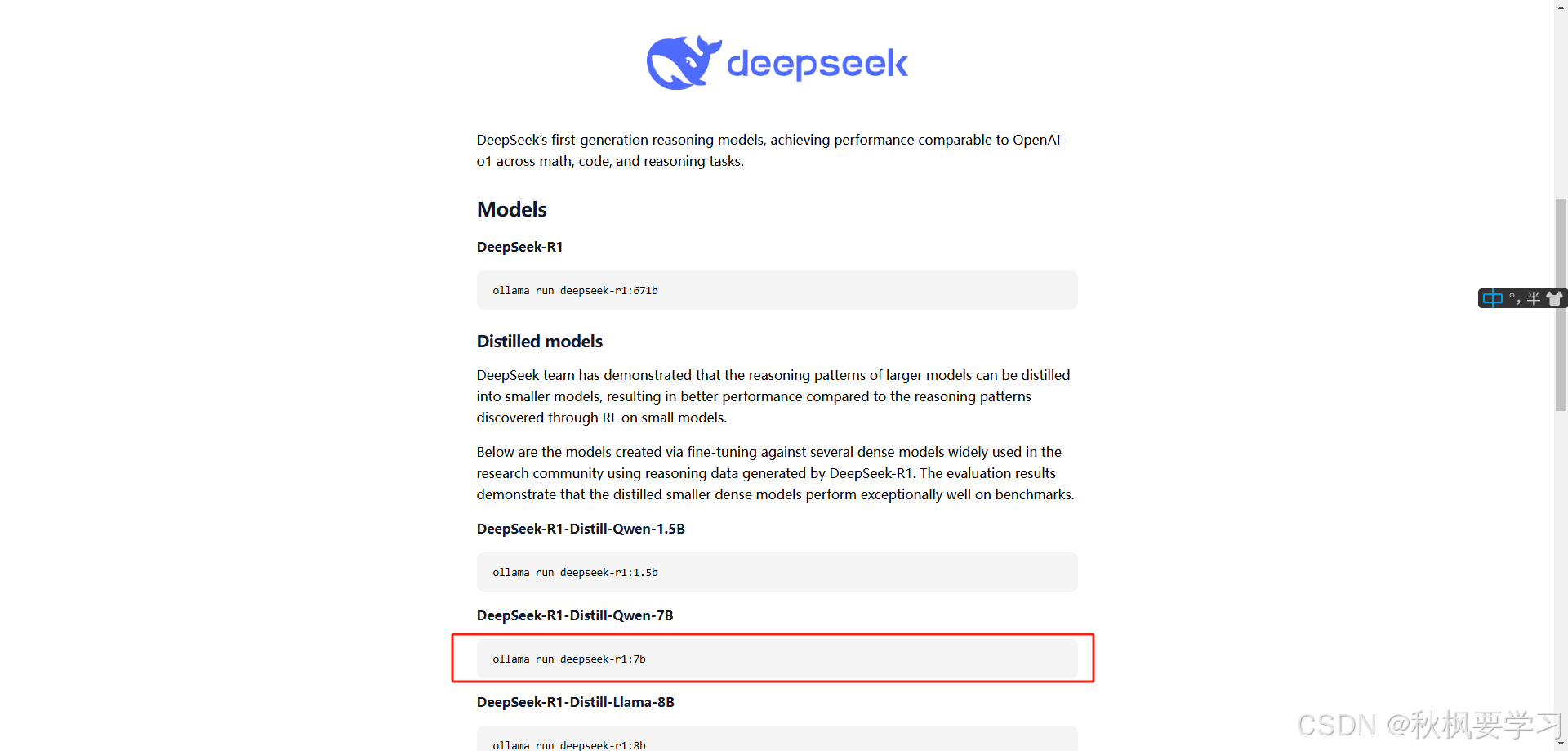
复制这段命令,粘贴到命令行
ollama run deepseek-r1:7b
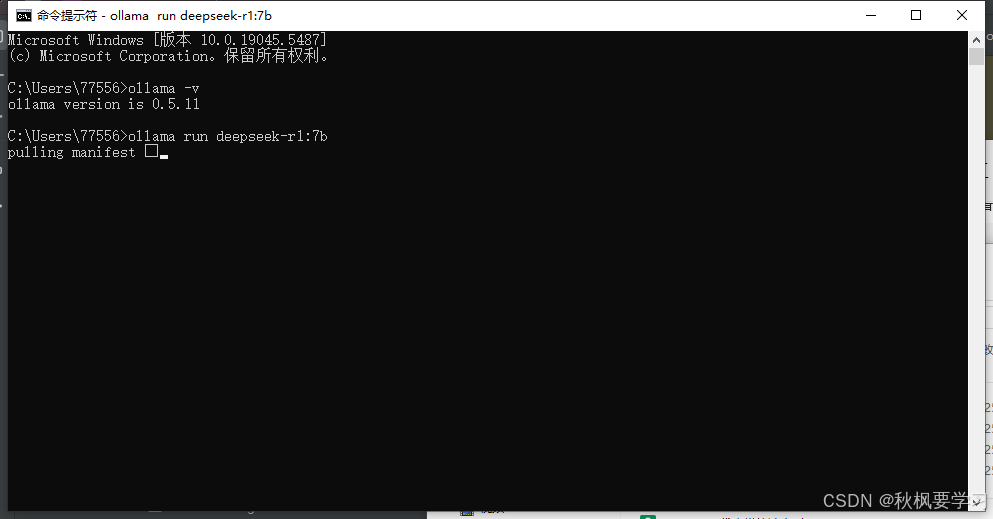
这个界面表示正在下载。
等待下载
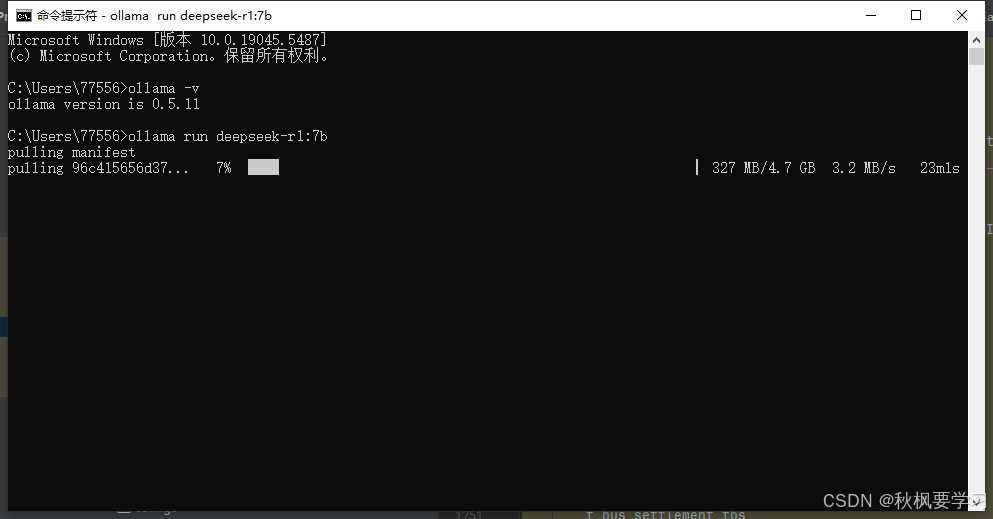
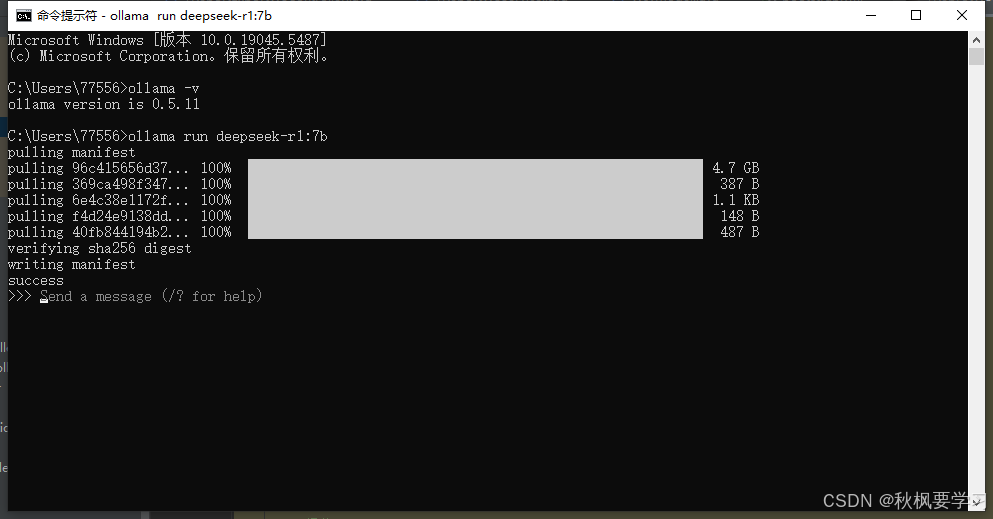
这个界面说明安装完毕了
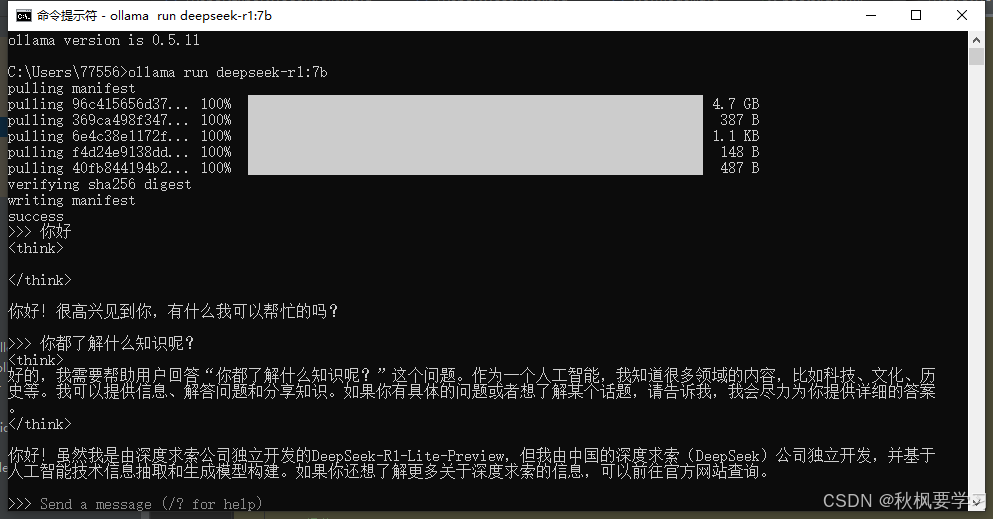
可以使用了。
如果觉得命令行不太方便,可以使用图形页面,我使用的ChatBox图形页面
https://chatboxai.app/zh
下载安装
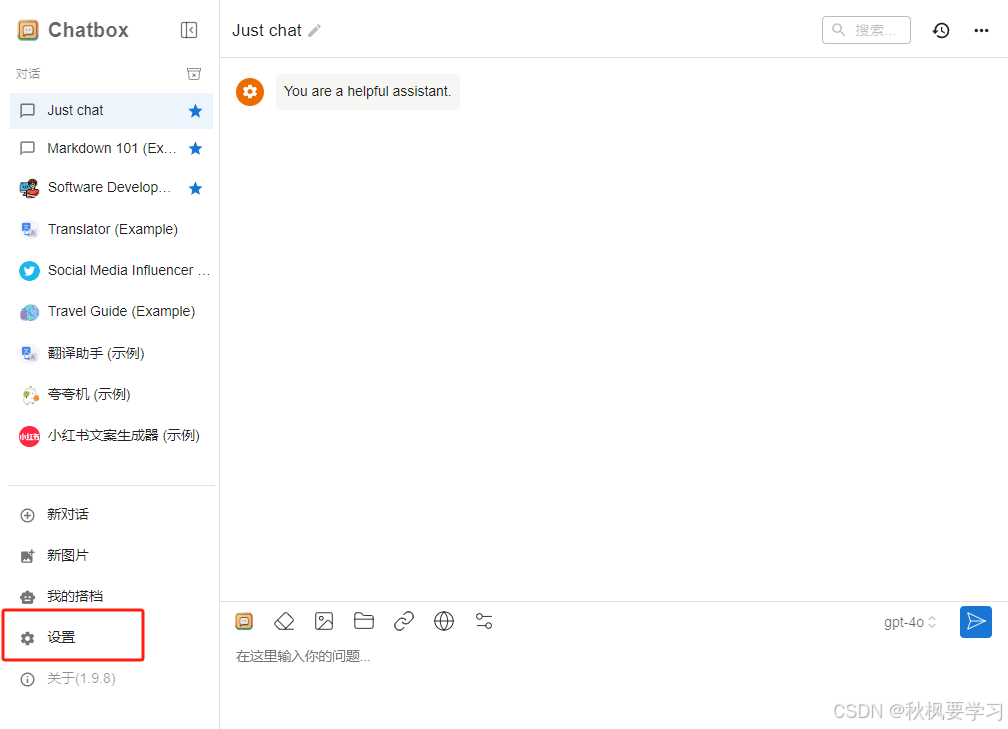
选择Ollama API
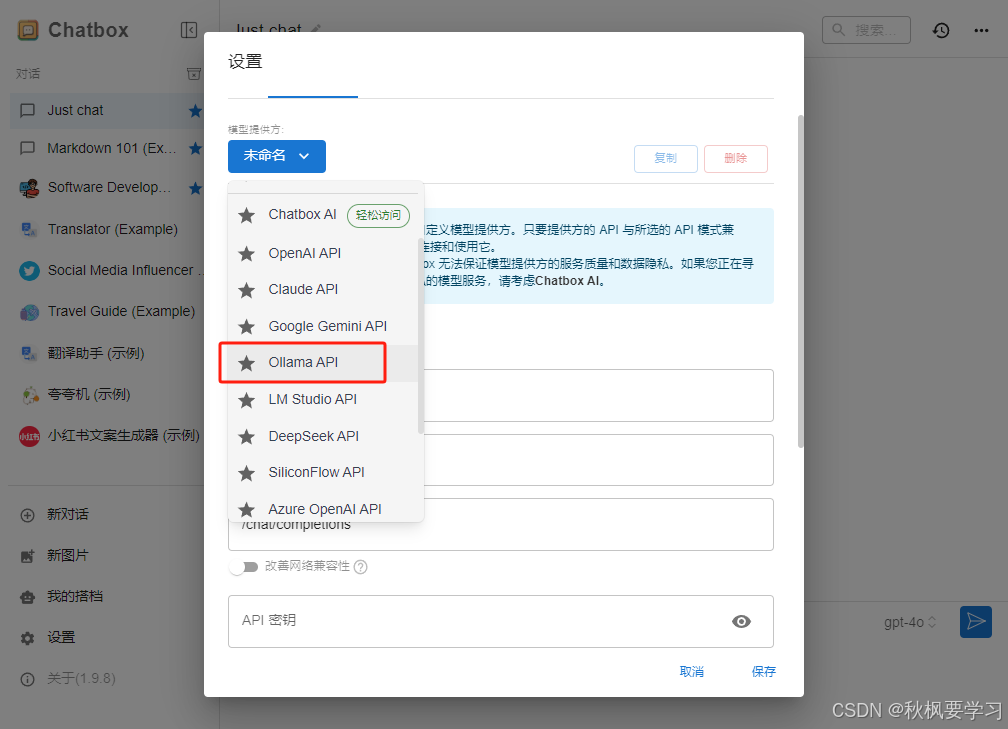
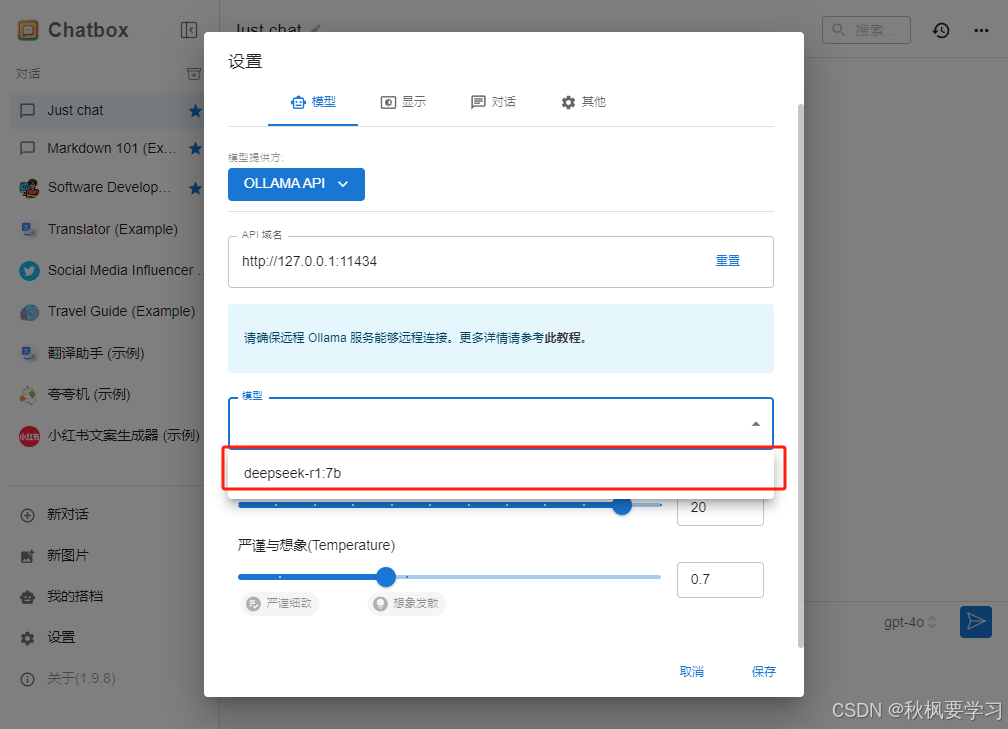
点击保存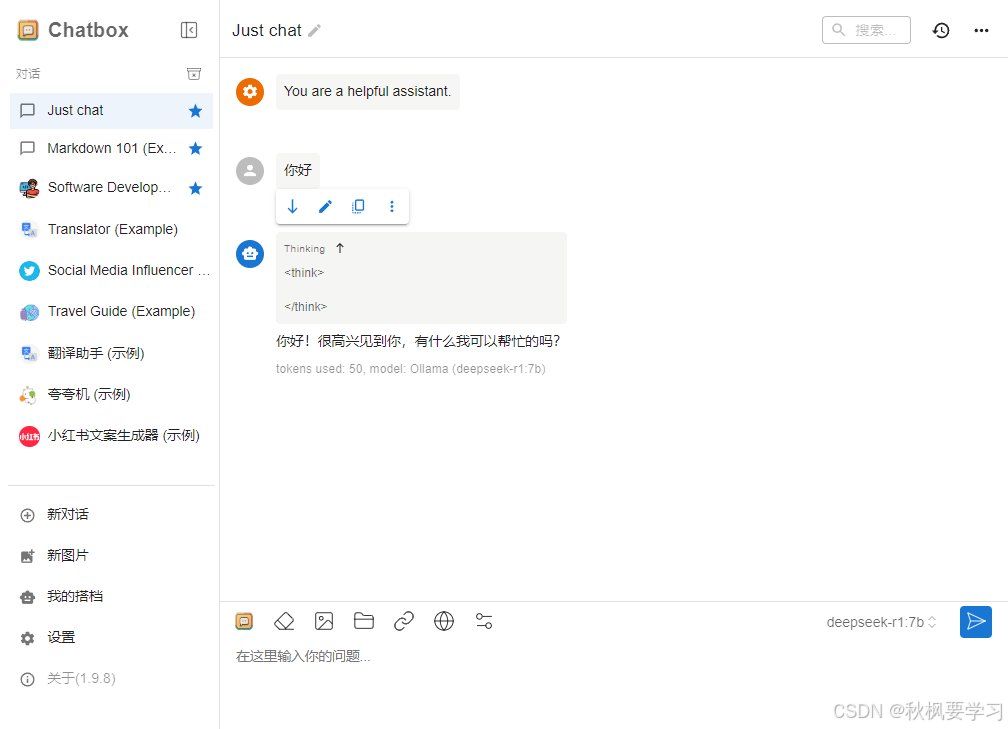
到这里就已经完毕了。
可以使用啦!!!


















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









