



 本文深入探讨Redis缓存的穿透、击穿和雪崩问题及其解决方案,介绍Redis持久化策略RDB和AOF,并讲解Redis存储原理及集群模式。此外,还详细阐述了秒杀业务的准备工作,包括查询秒杀商品列表、根据SpuId查询Sku列表等功能的开发,以及缓存预热和定时任务的设定。
本文深入探讨Redis缓存的穿透、击穿和雪崩问题及其解决方案,介绍Redis持久化策略RDB和AOF,并讲解Redis存储原理及集群模式。此外,还详细阐述了秒杀业务的准备工作,包括查询秒杀商品列表、根据SpuId查询Sku列表等功能的开发,以及缓存预热和定时任务的设定。
1.续 Redis强化
1.1缓存穿透
所谓缓存穿透,就是一个业务请求先查询redis,redis没有这个数据,那么就去查询数据库,但是数据库也没有的情况
正常业务下,一个请求查询到数据后,我们可以将这个数据保存在Redis
之后的请求都可以直接从Redis查询,就不需要再连接数据库了
但是一旦发生上面的穿透现象,仍然需要连接数据库,一旦连接数据库,项目的整体效率就会被影响
如果有恶意的请求,高并发的访问数据库中不存在的数据,严重的,当前服务器可能出现宕机的情况
解决方案:业界主流解决方案:布隆过滤器
布隆过滤器的使用步骤
1.针对现有所有数据,生成布隆过滤器,保存在Redis中
2.在业务逻辑层,判断Redis之前先检查这个id是否在布隆过滤器中
3.如果布隆过滤器判断这个id不存在,直接返回
4.如果布隆过滤器判断id存在,在进行后面业务执行
1.2缓存击穿
一个计划在Redis保存的数据,业务查询,查询到的数据Redis中没有,但是数据库中有
这种情况要从数据库中查询后再保存到Redis,这就是缓存击穿
但是这个情况也不是异常情况,因为我们大多数数据都需要设置过期时间,而过期时间到时,这个数据就会从Redis中移除,再有请求查询这个数据,就一定会从数据库中再次同步

缓存击穿本身并不是灾难性的问题,也不是不许发生的现象
1.3缓存雪崩
上面讲到击穿现象
同一时间发生少量击穿是正常的
但是如果出现同一时间大量击穿现象就会如下图

所谓缓存雪崩,指的就是Redis中保存的数据,短时间内有大量数据同时到期的情况
如上图所示,本应该有Redis反馈的信息,由于雪崩都去访问了Mysql,mysql承担不了,非常可能导致异常
要想避免这种情况,就需要避免大量缓存同时失效
大量缓存同时失效的原因:通常是同时加载的数据设置了相同的有效期导致的
我们可以通过在设置有效期时添加一个随机数,这样就能够防止大量数据同时失效了
1.4Redis持久化
Redis将信息保存在内存
内存的特征就是一旦断电,所有信息都丢失,对于Redis来讲,所有数据丢失后,再重新加载数据,就需要从数据库从新查询所有数据,这个操作不但耗费时间,而且对数据库的压力也非常大
而且有些业务是先将数据保存在Redis,隔一段时间和数据库同步的
如果Redis断电,这段时间的数据就完全丢失了!
为了防止Redis的重启对数据库带来额外的压力和数据的丢失,Redis支持了持久化的功能
所谓持久化就是将Redis中保存的数据,以指定方式保存在Redis当前服务器的硬盘上
如果存在硬盘上,那么断电数据也不会丢失
Redis实现持久化有两种策略
RDB:(Redis Database Backup)
RDB本质上就是数据库快照(就是当前Redis中所有数据转换成二进制的对象,保存在硬盘上)
默认情况下,每次备份会生成一个dump.rdb的文件
当Redis断电或宕机后,重新启动时,会从这个文件中恢复数据,获得dump.rdb中所有内容
实现这个效果我们可以在Redis的配置文件中添加如下信息
save 60 5
上面配置中60表示秒
5表示Redis的key被修改的次数
配置效果:1分钟内如果有5个key以上被修改,就启动rdb数据库快照程序
优点:
因为是整体Redis数据的二进制格式,数据恢复是整体恢复的
缺点:
生成的rdb文件是一个硬盘上的文件,读写效率是较低的
如果突然断电,只能恢复最后一次生成的rdb中的数据
AOF(Append Only File):
AOF策略是将Redis运行过的所有命令(日志)备份下来,保存在硬盘上
这样即使Redis断电,我们也可以根据运行过的日志,恢复为断电前的样子
我们可以在Redis的配置文件中添加如下配置信息
appendonly yes
经过这个设置,就能保存运行过的指令的日志了
理论上任何运行过的指令都可以恢复
但是实际情况下,Redis非常繁忙时,我们会将日志命令缓存之后,整体发送给备份,减少io次数以提高备份的性能和对Redis性能的影响
实际开发中,配置一般会采用每秒将日志文件发送一次的策略,断电最多丢失1秒数据
优点:
相对RDB来讲,信息丢失的较少
缺点:
因为保存的是运行的日志,所以占用空间较大
实际开发中RDB和AOF是可以同时开启的,也可以选择性开启
Redis的AOF为减少日志文件的大小,支持AOF rewrite
简单来说就是将日志中无效的语句删除,能够减少占用的空间
1.5Redis存储原理
我们在编写java代码业务时,如果需要从多个元素的集合中寻找某个元素取出,或检查某个Key在不在的时候,推荐我们使用HashMap或HashSet,因为这种数据结构的查询效率最高,因为它内部使用了
"散列表"
下图就是散列表的存储原理
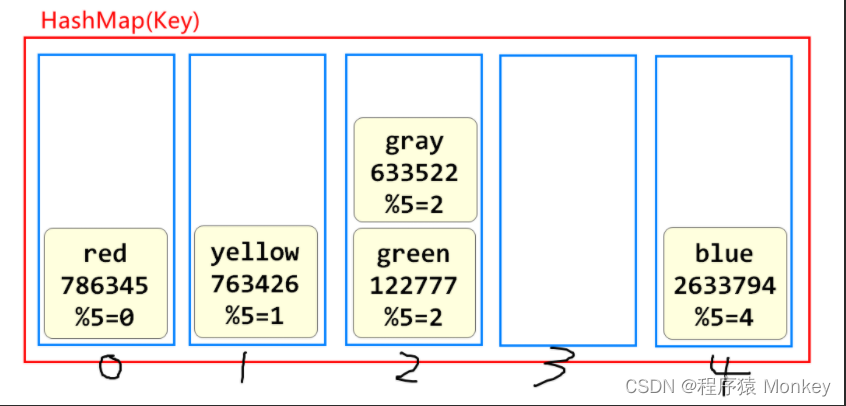
槽位越多代表元素多的时候,查询性能越高,HashMap默认16个槽
Redis底层保存数据用的也是这样的散列表的结构
Redis将内存划分为16384个区域(类似hash槽)
将数据的key使用CRC16算法计算出一个值,取余16384
得到的结果是0~16383
这样Redis就错非常高效的查找元素了
1.6Redis集群
Redis最小状态是一台服务器
这个服务器的运行状态,直接决定Redis是否可用
如果它离线了,整个项目就会无Redis可用
系统会面临崩溃
为了防止这种情况的发生,我们可以准备一台备用机
主从复制
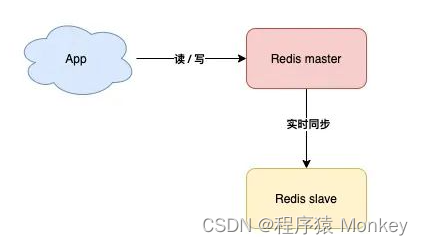
也就是主机(master)工作时,安排一台备用机(slave)实时同步数据,万一主机宕机,我们可以切换到备机运行
缺点,这样的方案,slave节点没有任何实质作用,只要master不宕机它就和没有一样,没有体现价值
读写分离
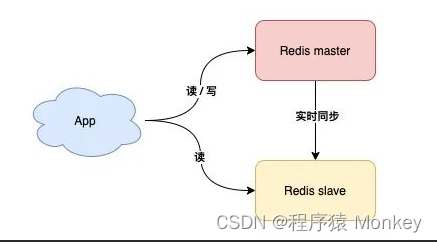
这样slave在master正常工作时也能分担Master的工作了
但是如果master宕机,实际上主备机的切换,实际上还是需要人工介入的,这还是需要时间的
那么如果想实现发生故障时自动切换,一定是有配置好的固定策略的
哨兵模式:故障自动切换
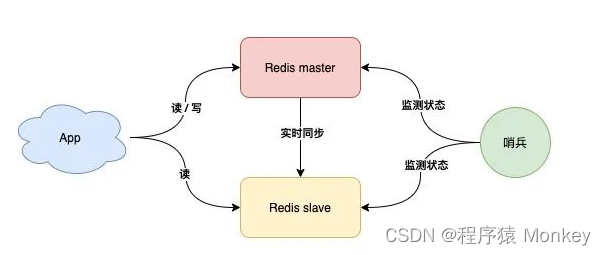
哨兵节点每隔固定时间向所有节点发送请求
如果正常响应认为该节点正常
如果没有响应,认为该节点出现问题,哨兵能自动切换主备机
如果主机master下线,自动切换到备机运行
但是这样的模式存在问题
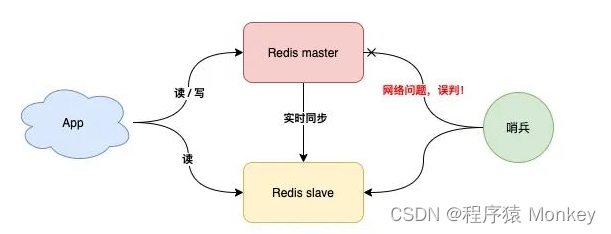
但是如果哨兵判断节点状态时发生了误判,那么就会错误将master下线,降低整体运行性能
所以要减少哨兵误判的可能性
哨兵集群
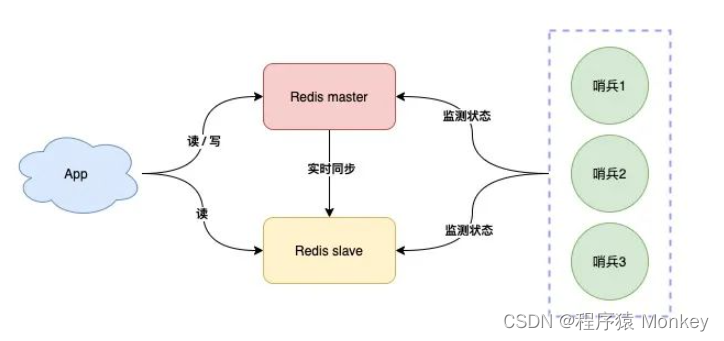
我们可以将哨兵节点做成集群,由多个哨兵投票决定是否下线某一个节点
哨兵集群中,每个节点都会定时向master和slave发送ping请求
如果ping请求有2个(集群的半数节点)以上的哨兵节点没有收到正常响应,会认为该节点下线
当业务不断扩展,并发不断增高时
分片集群
只有一个节点支持写操作无法满足整体性能要求时,系统性能就会到达瓶颈
这时我们就要部署多个支持写操作的节点,进行分片,来提高程序整体性能
分片就是每个节点负责不同的区域
Redis0~16383号槽,
例如MasterA复制0~5000
MasterB复制5001~10000
MasterC复制10001~16383
一个key根据CRC16算法只能得到固定的结果,一定在指定的服务器上找到数据
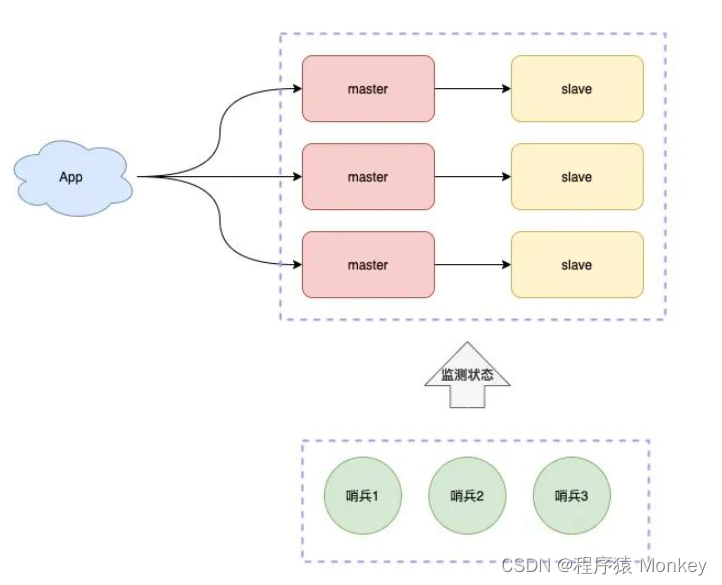
有了这个集群结构,我们就能更加稳定和更加高效的处理业务请求了
为了节省哨兵服务器的成本,有些公司在Redis集群中直接添加哨兵功能,既master/slave节点完成数据读写任务的同时也都互相检测它们的健康状态
有额外精力的同学,可以自己查询Redis分布式锁的解决方案
2.秒杀业务准备
2.1准备工作概述
学习秒杀的目的是让同学们了解高并发在微服务项目中的处理流程
指定一些基本的高并发处理标准动作
酷鲨商城定时秒杀业务就是一个模拟高并发的业务场景
每秒请求数8000
网站在线用户30000(到50000)
日活跃用户80000(到100000)
学习完秒杀业务,我们能具备处理一般高并发业务的基本逻辑
2.2开发查询秒杀商品列表功能
秒杀模块是mall-seckill,这个模块操作的数据库是mall-seckill
数据库中包含秒杀spu信息(seckill_spu)和秒杀sku信息(seckill_sku)以及秒杀成功记录(success)
首先我们先将秒杀列表的功能开发
2.2.1开发持久层
mall-seckill-webapi项目
创建mapper包,创建SeckillSpuMapper,代码如下
@Repository
public interface SeckillSpuMapper {
// 查询秒杀商品列表
List<SeckillSpu> findSeckillSpus();
}
SeckillSpuMapper.xml编写对应查询
<!-- 秒杀spu表sql的字段sql片段 -->
<sql id="SimpleField">
<if test="true">
id,
spu_id,
list_price,
start_time,
end_time,
gmt_create,
gmt_modified
</if>
</sql>
<!-- 查询秒杀商品spu列表的方法 -->
<select id="findSeckillSpus" resultMap="BaseResultMap">
select
<include refid="SimpleField" />
from
seckill_spu
</select>
2.2.2开发业务逻辑层
创建包service.impl
包中创建SeckillSpuServiceImpl实现ISeckillSpuService
代码如下
@Service
@Slf4j
public class SeckillSpuServiceImpl implements ISeckillSpuService {
// 查询秒杀商品spu列表
@Autowired
private SeckillSpuMapper seckillSpuMapper;
// 要想查询pms_spu,必须查询mall_pms数据库,查询这个数据库都是product模块的功能
@DubboReference
private IForSeckillSpuService dubboSeckillSpuService;
// 分页查询秒杀商品信息的方法
// 这个方法的返回值是包含pms_spu表中spu商品的一般信息的
// 所以业务中一定会查询pms_spu表中的信息,最终才能返回满足要求的商品信息
@Override
public JsonPage<SeckillSpuVO> listSeckillSpus(Integer page, Integer pageSize) {
// 分页查询秒杀商品列表
PageHelper.startPage(page,pageSize);
// 执行查询
List<SeckillSpu> seckillSpus=seckillSpuMapper.findSeckillSpus();
// 返回值SeckillSpuVO是既包含秒杀spu信息又包含普通spu信息
// 最终返回它必须在当前方法中去查询spu普通信息,所以先实例化集合以保存它
List<SeckillSpuVO> seckillSpuVOs=new ArrayList<>();
// 遍历从数据库中查询出的秒杀商品列表的集合
for(SeckillSpu seckillSpu : seckillSpus){
// 获得秒杀商品的spuId
Long spuId=seckillSpu.getSpuId();
// 利用dubbo查询当前spuId对应的普通商品信息
SpuStandardVO spuStandardVO=
dubboSeckillSpuService.getSpuById(spuId);
// seckillSpu是秒杀信息,spuStandardVO是普通信息
// 后面要将上面两组信息都赋值到SeckillSpuVO类型对象中
SeckillSpuVO seckillSpuVO=new SeckillSpuVO();
BeanUtils.copyProperties(spuStandardVO,seckillSpuVO);
// 下面将秒杀信息中特有的信息赋值到seckillSpuVO中
seckillSpuVO.setSeckillListPrice(seckillSpu.getListPrice());
seckillSpuVO.setStartTime(seckillSpu.getStartTime());
seckillSpuVO.setEndTime(seckillSpu.getEndTime());
//seckillSpuVO对象既包含了spu秒杀信息,又包含了spu普通信息
seckillSpuVOs.add(seckillSpuVO);
}
// 最后别忘了返回
return JsonPage.restPage(new PageInfo<>(seckillSpuVOs));
}
@Override
public SeckillSpuVO getSeckillSpu(Long spuId) {
return null;
}
@Override
public SeckillSpuDetailSimpleVO getSeckillSpuDetail(Long spuId) {
return null;
}
}
2.2.3开发控制层
创建controller包
创建SeckillSpuController类
代码如下
@RestController
@RequestMapping("/seckill/spu")
@Api(tags = "秒杀spu模块")
public class SeckillSpuController {
@Autowired
private ISeckillSpuService seckillSpuService;
@GetMapping("/list")
@ApiOperation("分页查询秒杀spu商品列表")
@ApiImplicitParams({
@ApiImplicitParam(value = "页码",name="page",required = true,
dataType = "int",example = "1"),
@ApiImplicitParam(value = "每页条数",name="pageSize",required = true,
dataType = "int",example = "10")
})
public JsonResult<JsonPage<SeckillSpuVO>> listSeckillSpus(
Integer page,Integer pageSize){
JsonPage<SeckillSpuVO> jsonPage=seckillSpuService
.listSeckillSpus(page,pageSize);
return JsonResult.ok(jsonPage);
}
}
启动服务
Nacos\Seata\Redis
启动我们的项目
product\passport\seckill
测试端口10007
2.3开发根据SpuId查询秒杀Sku列表信息
我们将秒杀的商品Spu列表查询出来
当用户选择一个商品时
我们要将这个商品的sku也查询出来
也就是根据SpuId查询Sku的列表
创建SeckillSkuMapper
@Repository
public interface SeckillSkuMapper {
// 根据SpuId查询sku列表
List<SeckillSku> findSeckillSkusBySpuId(Long spuId);
}
SeckillSkuMapper.xml文件添加内容
<sql id="SimpleField">
<if test="true">
id,
sku_id,
spu_id,
seckill_stock,
seckill_price,
gmt_create,
gmt_modified,
seckill_limit
</if>
</sql>
<select id="findSeckillSkusBySpuId" resultMap="BaseResultMap">
select
<include refid="SimpleField" />
from
seckill_sku
where
spu_id=#{spuId}
</select>
2.4根据当前时间查询正在进行秒杀的商品
根据给定时间查询出正在进行秒杀的商品列表
在秒杀过程中,一定会将当前时间正在进行秒杀商品查询出来的
首先保证数据库中的seckill_spu表的数据正在秒杀时间段(检查数据,如果不在秒杀时间段,将结束时间后移如2024年)
SeckillSpuMapper添加方法
// 根据指定时间,查询正在进行秒杀的商品信息
List<SeckillSpu> findSeckillSpusByTime(LocalDateTime time);
SeckillSpuMapper.xml
<!-- 根据指定时间,查询正在进行秒杀的商品信息 -->
<select id="findSeckillSpusByTime" resultMap="BaseResultMap">
select
<include refid="SimpleField" />
from
seckill_spu
where
start_time < #{time}
and
end_time > #{time}
</select>
2.5根据SpuId查询秒杀商品详情
SeckillSpuMapper接口添加方法
// 根据spuId查询spu商品信息
SeckillSpu findSeckillSpuById(Long spuId);
SeckillSpuMapper.xml添加内容
<!-- 根据spuId查询spu商品信息 -->
<select id="findSeckillSpuById" resultMap="BaseResultMap">
select
<include refid="SimpleField" />
from
seckill_spu
where
spu_id=#{spuId}
</select>
2.6查询所有秒杀商品的SpuId
这个查询需要时为了后面布隆过滤器加载数据库中包含的所有SpuId时使用
因为布隆过滤器的特性,只需要查询出所有商品的spu_id即可
SeckillSpuMapper接口添加方法
// 布隆过滤器用,查询所有商品的spuId
Long[] findAllSeckillSpuIds();
SeckillSpuMapper.xml添加内容
<!-- 布隆过滤器用,查询所有商品的spuId -->
<select id="findAllSeckillSpuIds" resultType="long">
select spu_id from seckill_spu
</select>
2.7缓存预热思路
在即将发生的高并发业务之前,我们将一些高并发业务中需要的数据保存到Redis中,这种操作,就是"缓存预热",这样发生高并发时,这些数据就可以直接从Redis中获得,无需查询数据库了
我们要利用Quartz周期性的将每个批次的秒杀商品,预热到Redis
例如每天的12:00 14:00 16:00 18:00进行秒杀
那么就在 11:55 13:55 15:55 17:55 进行预热
我们预热的内容有
-
我们预热的内容是将参与秒杀商品的sku查询出来,根据skuid将该商品的库存保存在Redis中
还要注意为了预防雪崩,在向Redis保存数据时,都应该添加随机数
-
(待完善).在秒杀开始前,生成布隆过滤器,访问时先判断布隆过滤器,如果判断商品存在,再继续访问
-
在秒杀开始之前,生成每个商品对应的随机码,保存在Redis中,随机码可以绑定给有Spu,防止有用户投机在秒杀开始之间购买商品
2.8设置定时任务
2.8.1将库存和随机码保存到Redis
利用Quartz将库存和随机码保存到Redis
1.创建Job接口实现类
2.创建配置类,配置JobDetail和Trigger
在seckill包下创建timer.job包
在seckill包下创建timer.config包
随笔
每个Spu都有Id
我们一般的购买或查询都是通过Id来绑定
但是商品的id并不是机密,通过技术手动很容易能获取
这样的话就会有人利用这个id直接访问控制器,控制器拿到这个id就要到数据库中查询
查询就需要数据库的效率,会严重影响服务器整体效能
我们放弃使用spuId访问商品
改而使用随机码访问,这样即使有投机者知道了商品的Id,他也不能知道访问商品的路径

















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









