本项目来源于和鲸社区,使用转载需要标注来源
作者: 段小V
来源: https://www.heywhale.com/mw/project/66cedee2c175d1eb849bc086
import time
import lightgbm as lgb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn import metrics
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
加载数据
In [2]:
train = pd.read_csv('/home/mw/input/homeprice/训练集.csv')
test = pd.read_csv('/home/mw/input/homeprice/测试集.csv')
In [3]:
# 查看列名
train.columns
Out[3]:
Index(['数据ID', '容纳人数', '便利设施', '洗手间数量', '床的数量', '床的类型', '卧室数量', '取消条款', '所在城市',
'清洁费', '首次评论日期', '房主是否有个人资料图片', '房主身份是否验证', '房主回复率', '何时成为房主',
'是否支持随即预订', '最近评论日期', '维度', '经度', '民宿周边', '评论个数', '房产类型', '民宿评分', '房型',
'邮编', '价格'],
dtype='object')
In [4]:
#打印数据大小
print(train.shape,test.shape)
(59288, 26) (14823, 25)
In [5]:
# 查看数据集缺失值
train.shape[0]-train.count()
Out[5]:
数据ID 0
容纳人数 0
便利设施 0
洗手间数量 160
床的数量 104
床的类型 0
卧室数量 78
取消条款 0
所在城市 0
清洁费 0
首次评论日期 12702
房主是否有个人资料图片 160
房主身份是否验证 160
房主回复率 14641
何时成为房主 160
是否支持随即预订 0
最近评论日期 12672
维度 0
经度 0
民宿周边 5509
评论个数 0
房产类型 0
民宿评分 13395
房型 0
邮编 761
价格 0
dtype: int64
In [6]:
# 查看数据类型
train.dtypes
Out[6]:
数据ID object
容纳人数 int64
便利设施 object
洗手间数量 float64
床的数量 float64
床的类型 int64
卧室数量 float64
取消条款 int64
所在城市 int64
清洁费 int64
首次评论日期 object
房主是否有个人资料图片 object
房主身份是否验证 object
房主回复率 object
何时成为房主 object
是否支持随即预订 int64
最近评论日期 object
维度 float64
经度 float64
民宿周边 object
评论个数 int64
房产类型 int64
民宿评分 float64
房型 int64
邮编 object
价格 float64
dtype: object
In [7]:
# 价格密度分布
train['价格'].plot.kde()
Out[7]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fc7ad52bef0>
数据预处理
类别变量数据预处理
In [8]:
train.select_dtypes(include=['object']).columns
Out[8]:
Index(['数据ID', '便利设施', '首次评论日期', '房主是否有个人资料图片', '房主身份是否验证', '房主回复率', '何时成为房主',
'最近评论日期', '民宿周边', '邮编'],
dtype='object')
In [9]:
train['便利设施数量']=train['便利设施'].apply(lambda x:len(x.lstrip('{').rstrip('}').split(',')))
test['便利设施数量']=test['便利设施'].apply(lambda x:len(x.lstrip('{').rstrip('}').split(',')))
train['便利设施数量'].head()
Out[9]:
0 17
1 18
2 11
3 1
4 13
Name: 便利设施数量, dtype: int64
In [10]:
no_features = ['数据ID', '价格','便利设施']
In [11]:
# 其他类别变量,暂时先直接简单的类别编码
data = pd.concat([train, test], axis=0)
for col in train.select_dtypes(include=['object']).columns:
if col not in no_features:
lb = LabelEncoder()
lb.fit(data[col].astype(str))
train[col] = lb.transform(train[col].astype(str))
test[col] = lb.transform(test[col].astype(str))
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:2: FutureWarning: Sorting because non-concatenation axis is not aligned. A future version
of pandas will change to not sort by default.
To accept the future behavior, pass 'sort=False'.
To retain the current behavior and silence the warning, pass 'sort=True'.
In [12]:
train.head(2)
Out[12]:
数据ID 容纳人数 便利设施 洗手间数量 床的数量 床的类型 卧室数量 取消条款 所在城市 清洁费 ... 维度 经度 民宿周边 评论个数 房产类型 民宿评分 房型 邮编 价格 便利设施数量
0 train_0 4 {TV,"Cable TV",Internet,"Wireless Internet","A... 1.5 3.0 4 2.0 0 3 0 ... 34.109039 -118.273390 323 12 17 97.0 0 454 64.918531 17
1 train_1 2 {TV,"Wireless Internet",Kitchen,"Free parking ... 1.0 1.0 4 1.0 2 4 1 ... 40.812897 -73.919163 371 6 0 87.0 0 150 54.918531 18
2 rows × 27 columns
In [13]:
# 输入特征列
features = [col for col in train.columns if col not in no_features]
features
Out[13]:
['容纳人数',
'洗手间数量',
'床的数量',
'床的类型',
'卧室数量',
'取消条款',
'所在城市',
'清洁费',
'首次评论日期',
'房主是否有个人资料图片',
'房主身份是否验证',
'房主回复率',
'何时成为房主',
'是否支持随即预订',
'最近评论日期',
'维度',
'经度',
'民宿周边',
'评论个数',
'房产类型',
'民宿评分',
'房型',
'邮编',
'便利设施数量']
In [14]:
X = train[features] # 训练集输入
y = train['价格'] # 训练集标签
X_test = test[features] # 测试集输入
模型训练
定义一个LightGBM回归模型
进行5折交叉验证训练
In [15]:
n_fold = 5
folds = KFold(n_splits=n_fold, shuffle=True,random_state=1314)
In [16]:
# 祖传参数
params = {
'learning_rate': 0.1,
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'feature_fraction': 0.6,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'num_leaves': 1000,
'verbose': -1,
'max_depth': -1,
'seed': 2019,
# 'n_jobs': -1,
# 'device': 'gpu',
# 'gpu_device_id': 0,
}
In [17]:
oof = np.zeros(len(X))
prediction = np.zeros(len(X_test))
for fold_n, (train_index, valid_index) in enumerate(folds.split(X)):
X_train, X_valid = X[features].iloc[train_index], X[features].iloc[valid_index]
y_train, y_valid = y[train_index], y[valid_index]
model = lgb.LGBMRegressor(**params, n_estimators=50000, n_jobs=-1)
model.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_valid, y_valid)],
eval_metric='rmse',
verbose=50, early_stopping_rounds=200)
y_pred_valid = model.predict(X_valid)
y_pred = model.predict(X_test, num_iteration=model.best_iteration_)
oof[valid_index] = y_pred_valid.reshape(-1, )
prediction += y_pred
prediction /= n_fold
Training until validation scores don't improve for 200 rounds.
[50] training's l1: 2.50955 training's rmse: 3.51182 valid_1's l1: 4.00062 valid_1's rmse: 5.54678
[100] training's l1: 1.67517 training's rmse: 2.37551 valid_1's l1: 4.00067 valid_1's rmse: 5.56198
[150] training's l1: 1.1836 training's rmse: 1.70484 valid_1's l1: 4.01786 valid_1's rmse: 5.58762
[200] training's l1: 0.858059 training's rmse: 1.25716 valid_1's l1: 4.03001 valid_1's rmse: 5.60145
[250] training's l1: 0.632487 training's rmse: 0.947884 valid_1's l1: 4.03837 valid_1's rmse: 5.61397
Early stopping, best iteration is:
[51] training's l1: 2.48324 training's rmse: 3.47721 valid_1's l1: 3.9978 valid_1's rmse: 5.54418
Training until validation scores don't improve for 200 rounds.
[50] training's l1: 2.52211 training's rmse: 3.52777 valid_1's l1: 3.99311 valid_1's rmse: 5.54752
[100] training's l1: 1.68729 training's rmse: 2.38666 valid_1's l1: 3.97864 valid_1's rmse: 5.53823
[150] training's l1: 1.19122 training's rmse: 1.70633 valid_1's l1: 3.98319 valid_1's rmse: 5.55346
[200] training's l1: 0.860449 training's rmse: 1.25289 valid_1's l1: 3.99099 valid_1's rmse: 5.56535
[250] training's l1: 0.631739 training's rmse: 0.937761 valid_1's l1: 3.99794 valid_1's rmse: 5.57606
Early stopping, best iteration is:
[81] training's l1: 1.95203 training's rmse: 2.75026 valid_1's l1: 3.97051 valid_1's rmse: 5.52464
Training until validation scores don't improve for 200 rounds.
[50] training's l1: 2.50947 training's rmse: 3.51603 valid_1's l1: 3.98525 valid_1's rmse: 5.51465
[100] training's l1: 1.67565 training's rmse: 2.38033 valid_1's l1: 3.98162 valid_1's rmse: 5.51442
[150] training's l1: 1.18302 training's rmse: 1.70379 valid_1's l1: 3.99318 valid_1's rmse: 5.53784
[200] training's l1: 0.854505 training's rmse: 1.24884 valid_1's l1: 4.00959 valid_1's rmse: 5.56068
[250] training's l1: 0.627659 training's rmse: 0.936065 valid_1's l1: 4.01792 valid_1's rmse: 5.57399
Early stopping, best iteration is:
[87] training's l1: 1.84757 training's rmse: 2.61448 valid_1's l1: 3.97655 valid_1's rmse: 5.507
Training until validation scores don't improve for 200 rounds.
[50] training's l1: 2.51465 training's rmse: 3.52322 valid_1's l1: 3.98707 valid_1's rmse: 5.5369
[100] training's l1: 1.67888 training's rmse: 2.38065 valid_1's l1: 3.98119 valid_1's rmse: 5.54957
[150] training's l1: 1.18353 training's rmse: 1.70332 valid_1's l1: 3.99946 valid_1's rmse: 5.56963
[200] training's l1: 0.857588 training's rmse: 1.25382 valid_1's l1: 4.01033 valid_1's rmse: 5.58856
[250] training's l1: 0.62821 training's rmse: 0.940656 valid_1's l1: 4.02037 valid_1's rmse: 5.60475
Early stopping, best iteration is:
[65] training's l1: 2.20591 training's rmse: 3.10073 valid_1's l1: 3.97691 valid_1's rmse: 5.53289
Training until validation scores don't improve for 200 rounds.
[50] training's l1: 2.51855 training's rmse: 3.53134 valid_1's l1: 3.96679 valid_1's rmse: 5.52852
[100] training's l1: 1.6783 training's rmse: 2.38498 valid_1's l1: 3.9572 valid_1's rmse: 5.52841
[150] training's l1: 1.18495 training's rmse: 1.71336 valid_1's l1: 3.97783 valid_1's rmse: 5.55451
[200] training's l1: 0.86262 training's rmse: 1.27311 valid_1's l1: 3.99426 valid_1's rmse: 5.57768
[250] training's l1: 0.634659 training's rmse: 0.961603 valid_1's l1: 4.00527 valid_1's rmse: 5.59218
Early stopping, best iteration is:
[68] training's l1: 2.1569 training's rmse: 3.04038 valid_1's l1: 3.95122 valid_1's rmse: 5.51852
In [19]:
# 验证集评估
from sklearn.metrics import mean_squared_error
score=mean_squared_error(oof,train['价格'].values)
score
Out[19]:
30.530722712549625
提交结果
In [20]:
test['价格'] = prediction
test[['数据ID', '价格']].to_csv('sub.csv'.format(score), index=None)
In [21]:
test[['数据ID', '价格']].head()
Out[21]:
数据ID 价格
0 test_0 59.854565
1 test_1 68.861567
2 test_2 68.583587
3 test_3 77.517740
4 test_4 56.493932
TODO
可以做更细粒度的特征
尝试不同的模型
模型融合
...
最新发布




](https://i-blog.csdnimg.cn/blog_migrate/a42a6b4afa327c8bf63d0388abee0c37.png)
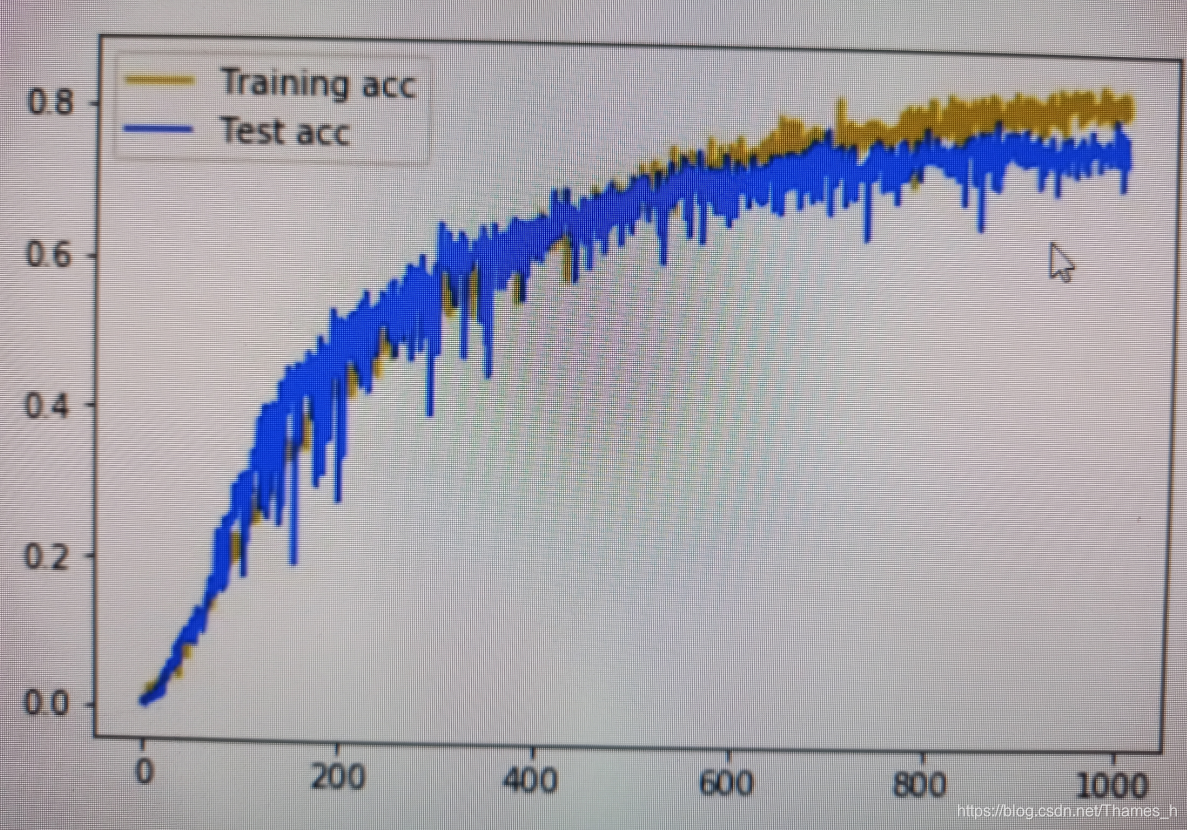
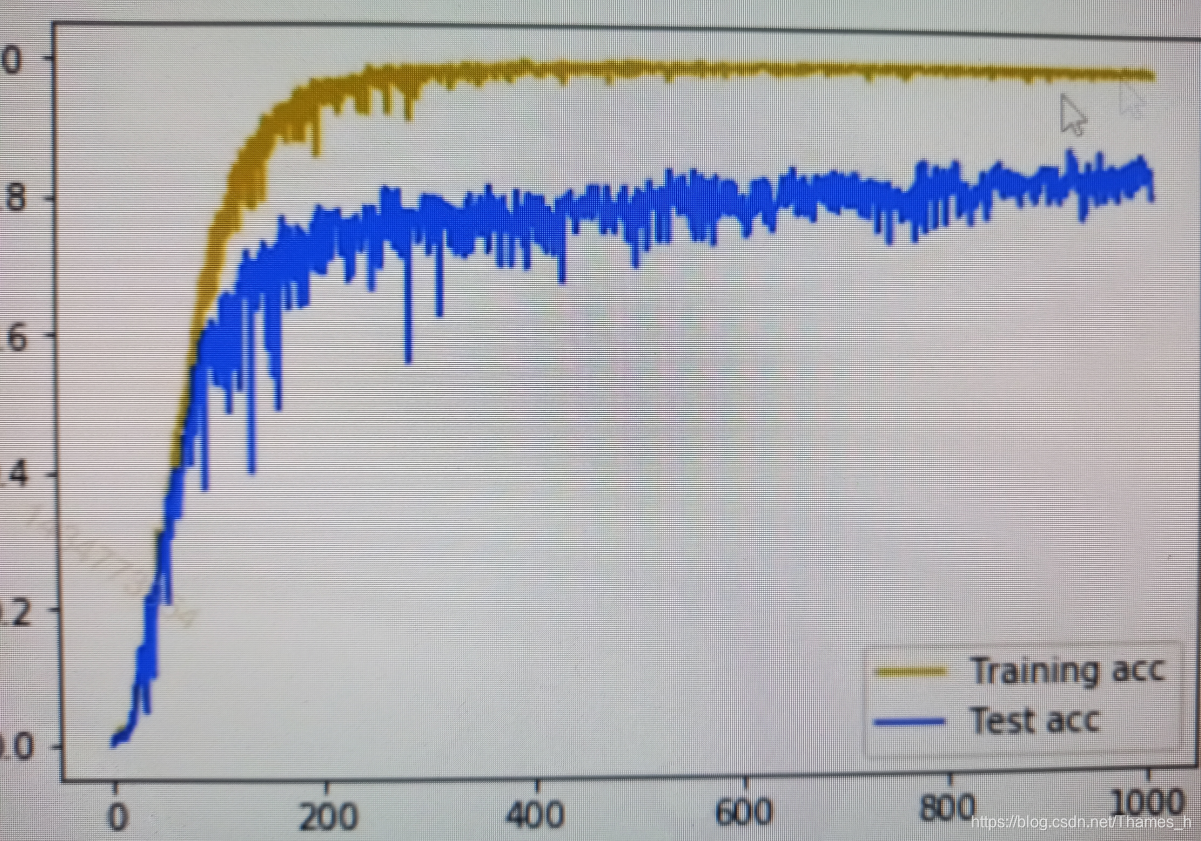
 本文探讨了如何通过添加dropout层解决过拟合问题,并通过调整神经元数量提高网络拟合,最终通过实例展示了调整策略的有效性。
本文探讨了如何通过添加dropout层解决过拟合问题,并通过调整神经元数量提高网络拟合,最终通过实例展示了调整策略的有效性。
 4301
4301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























