




论文链接:https://aclanthology.org/2025.acl-long.907/
代码:https://github.com/thu-pacman/Tree-KG
引言
在人工智能的研究与应用中,知识图谱(Knowledge Graph, KG)已成为不可或缺的基石。无论是搜索引擎、智能问答,还是学术研究、教育应用,知识图谱都能帮助我们把碎片化的信息组织成结构化的知识网络。
但问题来了:知识密集型领域(例如科学研究、医学、法律等)有两大特点:一是信息复杂、实体与概念多且相互依赖;二是领域知识急速演化,人工维护昂贵且难以及时更新。传统方法(规则系统、监督学习)在可扩展性、泛化能力或构建成本上有明显短板;而纯 LLM 方案虽能抽取很多信息,却缺少明确的知识结构、语义一致性与增量扩展机制,难以直接服务下游需要稳定结构的任务(如推理、课程组织等)。
论文由此出发,提出了利用“人类自然采用的分层组织(比如教科书的章节结构)”作为构建 KG 的起点,既能降低标注/抽取成本,也能为后续的自动扩展提供良好骨架。
1. 人类启示:知识组织的自然方式
当我们学习一个新领域时,通常会从教科书入手。为什么?因为教科书采用了层次化的知识组织方式——从章到节再到小节,层层递进,这种结构符合人类的认知习惯。
清华大学的研发团队从中获得灵感:如果AI也能像人类这样层次化地组织和理解知识,是否能够更有效地构建知识图谱?
研究团队通过分析教科书发现了一个有趣现象:位置相近的实体更可能具有强关联。在同一小节中的实体间关系强度明显高于不同章节的实体。
这一发现成为Tree-KG设计的核心动机——模仿人类层次化组织知识的方式,构建更加智能的知识图谱。
Tree-KG的图谱模式(Schema)采用一种树状的层级化知识图谱结构。每个节点有三种主要属性:
(1)name:节点的名字;
(2)description:最初来自源文本,后来会通过 LLM 把邻居节点的描述整合进来进行丰富;
(3)relations:与其他节点的边。
边的类型分为两大类:
同质的纵向边(homogeneous vertical edges):表示层级或从属关系。Tree-KG 预定义了三类:
has_subsection:章节与子章节之间的关系;has_entity:小节与其中实体的关系;has_subordinate:核心实体与非核心实体之间的从属关系。
异质的横向边(heterogeneous horizontal edges):结合了一个通用类别 + 大模型预测的具体语义关系。
通用类别分为:
section_related(章节之间的关系)、entity_related(实体之间的关系);在具体层面,大模型会给出更细的关系标签,比如 obey(遵循)、has(拥有),如图 2 所示。
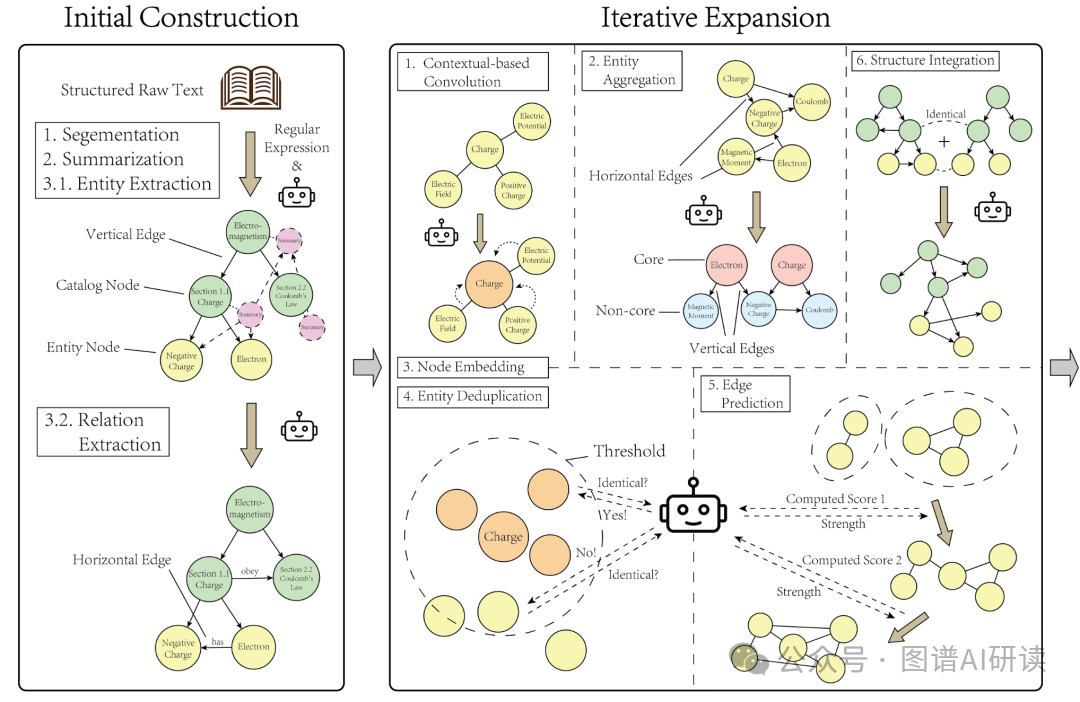
图1 Tree-KG知识图谱构建框架
2. Tree-KG:双阶段构建的知识图谱框架
如图1所示,Tree-KG的创新之处在于采用了双阶段构建流程,完美结合了结构化知识和语义理解的优势。
第一阶段:显式知识图谱构建
系统首先解析教科书等结构化文本,识别出章、节、小节的层次结构。就像我们先浏览书籍的目录,把握整体框架一样。
接着,使用大语言模型为每个小节生成摘要,并自底向上逐层汇总,形成完整的知识框架。在这个过程中,系统还会提取关键实体和它们之间的关系,构建起知识图谱的“骨架”。
第二阶段:隐藏知识挖掘与扩展
这只是开始。真正的亮点在于第二阶段——通过一系列精心设计的操作符逐步揭示那些不那么明显但极为重要的“隐藏知识”。
这些操作包括:
Convolution:受到图卷积思想启发,用 LLM 将某个实体 v 与其邻居 N(v) 的信息结合,生成更新后的实体描述。
Aggregation:LLM 给每个实体分配局部角色
core或non-core。对core实体将相邻non-core聚为其子节点并把横向边转换为纵向has_subordinate边,从而把实体层构建为双层(core / non-core),区分核心实体和次级实体,形成更清晰的层次。Embedding:把每个节点描述映射为单位范数向量 z,用于检索、相似度计算和后续的去重/合并。
Deduplication:自动去重,合并重复概念;用 FAISS 检索每个实体的最近 20 个邻居,筛选满足距离小于阈值且角色相同的候选对,然后按距离从小到大询问 LLM 是否为同一实体。
Edge Prediction:结合语义相似度、Adamic-Adar分数和共同祖先数,预测实体之间是否具有潜在关系;
Merge:支持将新文本源(结构化和非结构化)融合至现有图谱中。
3. 实验验证:全面领先的性能表现
为了验证Tree-KG的有效性,研究团队构建了包含约69,000份专业材料的大规模数据集,涵盖教材/讲义/论文,覆盖 ~100 子领域,约 9.95M知识点。
研究团队在 物理学、电子学、教育心理学等多个领域测试了 Tree-KG,并与当前主流方法(GraphRAG、LangChain 等)做了对比。
准确率:在多个基准上,Tree-KG 的 F1 分数比其他方法高出 12%–16%;在“文本标注”数据集上达到了 0.81的高分。
结构保真度:Tree-KG 构建出的图谱在结构连通性和结构对齐度上明显优于对手,更接近人工构建的知识体系。
成本控制:在物理学领域数据上,Tree-KG 的总 token 消耗约 610 万,花费约 18 元人民币,性价比远超一些消耗 1500 万 token 的方法。
可以说,Tree-KG 在“质量”与“成本”之间找到了一个难得的平衡点。
4. 展望未来
当然,Tree-KG 也存在一些局限:
依赖于有层次结构的文本(如教材),在网络论坛、百科等无序文本中表现可能不如结构化语料;
部分步骤仍然依赖大模型的判断,可能受到模型幻觉的影响;
在复杂推理和任务定制方面,还需要进一步探索。
但整体来看,Tree-KG 已经为我们打开了一条新路:从“人类的知识组织方式”出发,构建更符合认知习惯、又能自动进化的知识图谱。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 1439
1439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









