



转载公众号 | 老刘说NLP
基于知识图谱进行数据合成是一个很前沿的方向,也是社区最近的关注的点,我们也写过多个文章介绍,如MedReason。
所以,社区今天进行了两个工作的研读,从论文跟代码出发,也就是多跳推理数据合成的方案,尤其是面向Deepresearch数据的合成,看两个工作,共同点都是从维基百科中构建多跳推理路径,也是初始化实体,然后迭代构成图,然后基于图来生成问题这类思路。
先说结论,基于图谱的方式做推理数据合成的两个思路,这块是llm跟kg结合的方向,感兴趣的可看看,尤其是学生群体。工业界的,可以借鉴里面的代码实现逻辑,虽然方式都很粗糙。
多总结,多归纳,多从底层实现分析逻辑,会有收获。
一、基于医疗百科数据合成推理多跳数据-MedResearcher-R1
第一个工作,MedResearcher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework,https://github.com/AQ-MedAI/MedResearcher-R1,https://arxiv.org/abs/2508.14880,https://huggingface.co/AQ-MedAI/MedResearcher-R1-32B,医学DeepResearch agent,构造医疗领域的多跳推理数据,其核心的核心也是数据合成,通过医学知识图谱生成复杂的多跳问答对,<Question, Reasoning, Answer>。这个可以借鉴。
1、实现思路
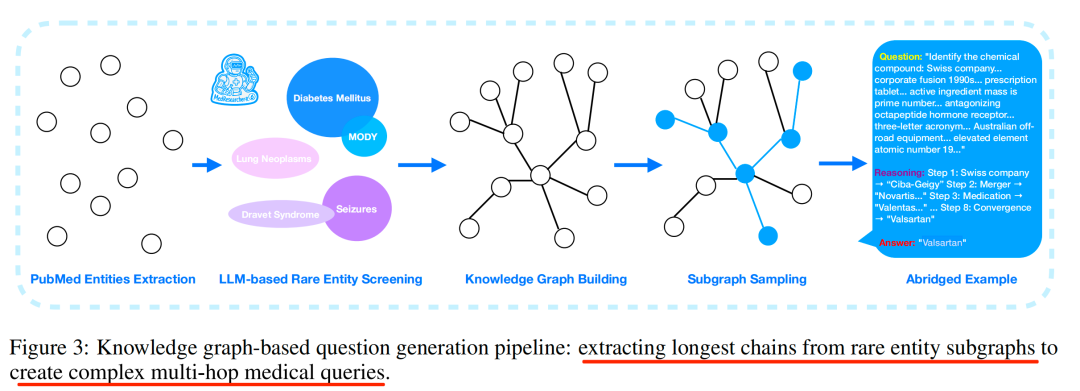
1)获取初始化实体,从超过3000万篇PubMed摘要中提取医学实体,然后,筛选罕见实体,通过频率分析,找出在医学文献中出现频率低于10⁻⁶的医学实体。假设是,这些实体非常罕见,但可能在临床上很重要。最后,人工筛选+LLM辅助评估,过滤掉那些可能是拼写错误或过于常见的实体,确保选出的实体既罕见又具有临床意义
->2)构建图谱,以这些罕见医学实体为中心,例如,构建知识图谱子图,子图包含了与罕见实体相关的其他医学概念和关系,这个过程是迭代构建,逐步扩展,每次扩展时,会随机选择邻居节点或通过私有医学检索引擎发现新的实体。
-> 3)生成最长推理链。对于每个罕见实体的子图,计算最长的推理路径【先算连通图,然后最长路径采样】,然后路径随后被转化为自然语言问题,生成的问题需要多个推理步骤(平均4.2步),这里的answer也是已知,question 和reason_path同步输出来。
2、先从问题生成说起
这块来拆解下实现过程,主要代码在https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/KnowledgeGraphConstruction/lib/runs_qa_generator.py,直接拿来取子图生成问题,生成参数包括:sample_size: 子图采样大小; sampling_algorithm:采样算法 ("mixed", "augmented_chain", "community_core_path", "dual_core_bridge", "max_chain", "connected_subgraph",是有很多采样算法的); use_unified_qa: 是否使用统一QA生成器; num_questions: 生成问题数量。
基于子图生成多跳推理问题的prompt,如下:
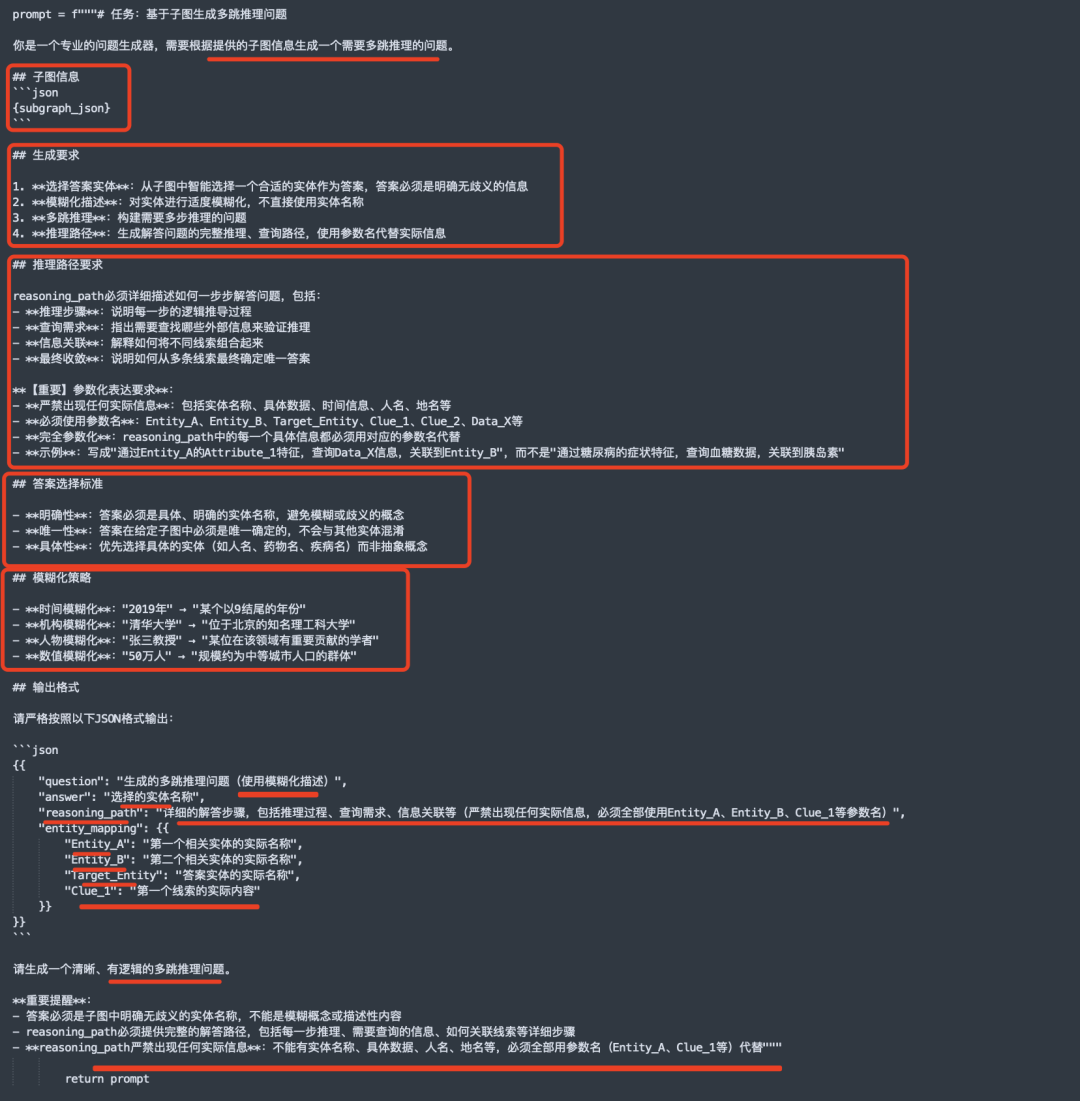
核心还是prompt设计:例如这个步骤,就是将采样后的subgraph输入后,丢个llm做生成,这里用的是gpt-3.5-turbo,输入subgraph,然后输出question ,answer, reason_path,以及entity mapping【因为reasoning path里面提到的是符号化过的,比如entity_A等】。注意,还特意做的模糊化,用来提升问题难度,例如,时间模糊化:"2019年"→"某个以9结尾的年份",*机构模糊化**:"清华大学"→"位于北京的知名理工科大学",人物模糊化:"张三教授"→"某位在该领域有重要贡献的学者",数值模糊化:"50万人"→"规模约为中等城市人口的群体"。
最终得到的结果是:

3、往回反推,看subgraph怎么弄
,这个很简单,因为已经有个图,那么只需要做成连通图,然后做采样即可。https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/KnowledgeGraphConstruction/lib/graph_sampler.py,
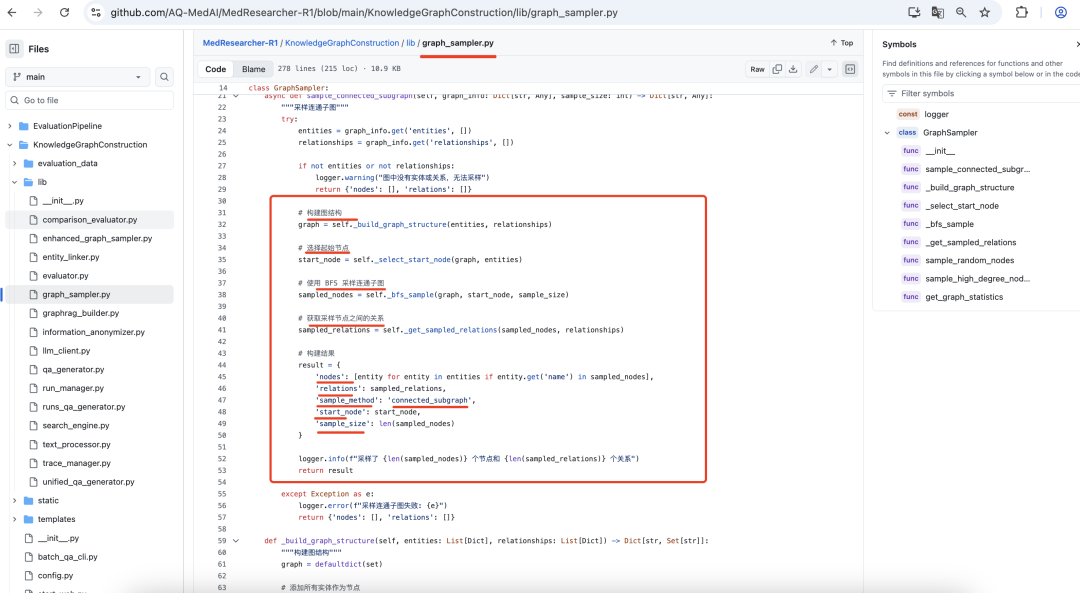
采样后,再选择最长的,策略有多种,包括("mixed", "augmented_chain", "community_core_path", "dual_core_bridge", "max_chain", "connected_subgraph"),https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/KnowledgeGraphConstruction/lib/enhanced_graph_sampler.py,最长链采样 (Max Chain Sampling)以尽可能长的逻辑链为核心,在此基础上对链条的邻居进行随机拓展。
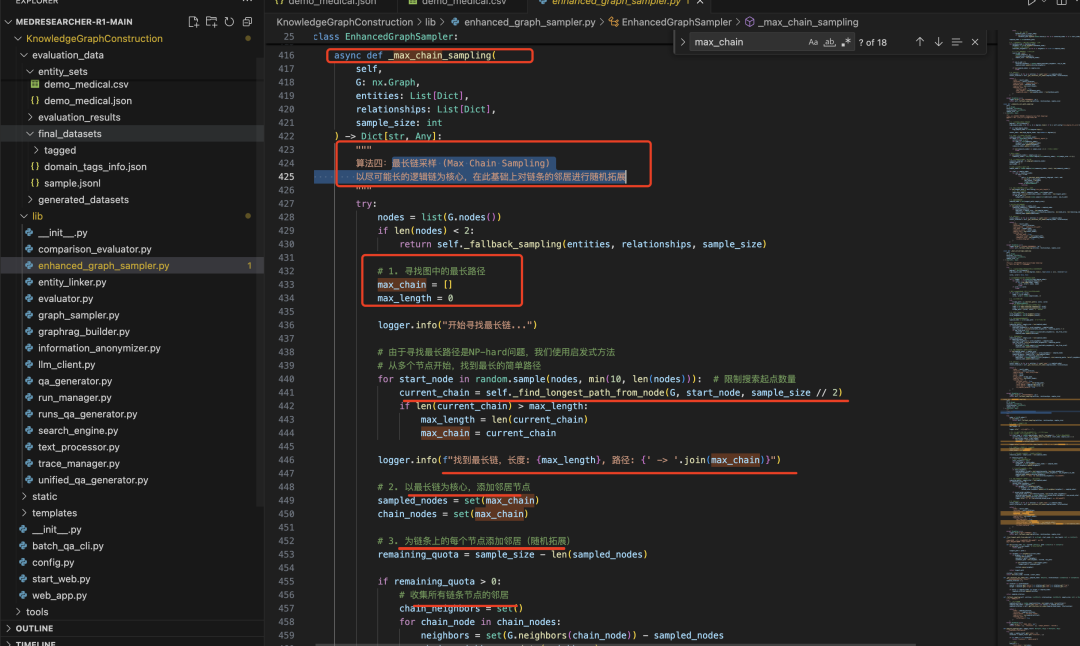
4、再往前推,这个Graph怎么建立?
构建的过程在https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/KnowledgeGraphConstruction/lib/graphrag_builder.py,采用的方式很粗暴,基于GraphRag的方式,直接拿来用。
步骤:1)获取初始实体,例如【糖尿病、高血压、心脏病、癌症、阿尔茨海默病、帕金森病、哮喘、肺炎、抑郁症、焦虑症】,这是上面说的筛选出来的,从超过3000万篇PubMed摘要中提取医学实体,然后,筛选罕见实体,通过频率分析,找出在医学文献中出现频率低于10⁻⁶的医学实体
->2)对初始实体进行搜索拓展,迭代去抽实体关系,使用Tavily搜索内容【这个抽取还是用了词扩展查询,https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/KnowledgeGraphConstruction/lib/llm_client,py】,直接获取搜索结果的content内容,现在获取前5个结果
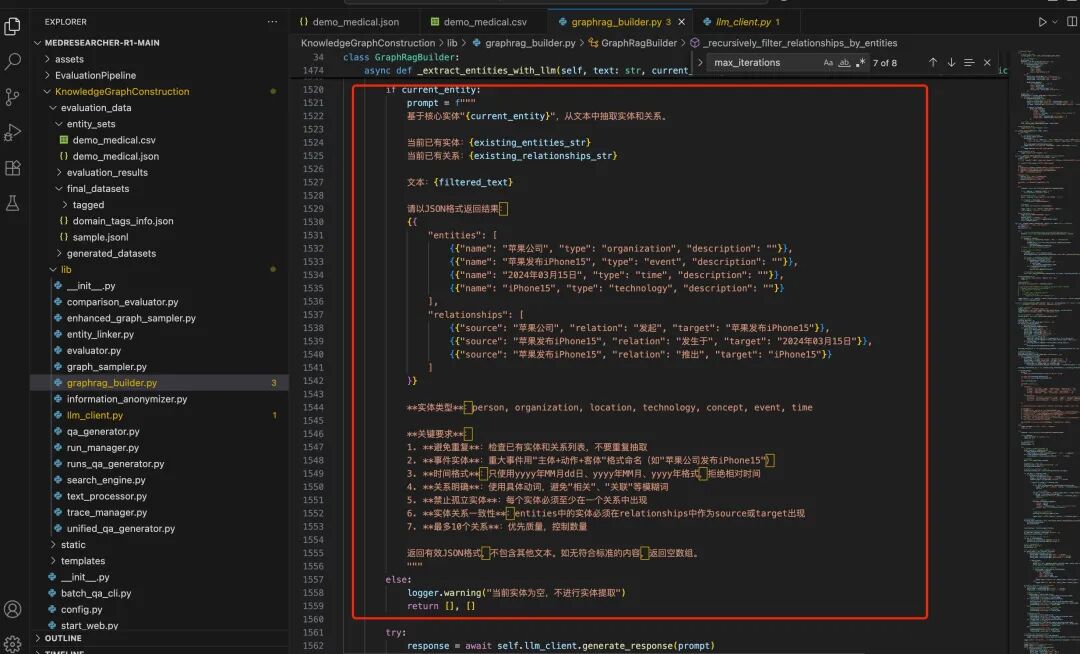
->3)使用LLM从文本中抽取实体和关系(这个实直接用的Prompt提示,graphrag_builder.py),并进行Wikidata实体链接(https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/KnowledgeGraphConstruction/lib/entity_linker.py),链接的目的是为了做实体对齐->3)迭代更新实体关系,最多迭代 max_iterations = 100次。【可以看到,这个粗糙,抽取对不对,扩展对不对,都很不可控】
其中,抽取的prompt如下:
借助搜索引擎,扩展查询,搜索对应网页的prompt如下:
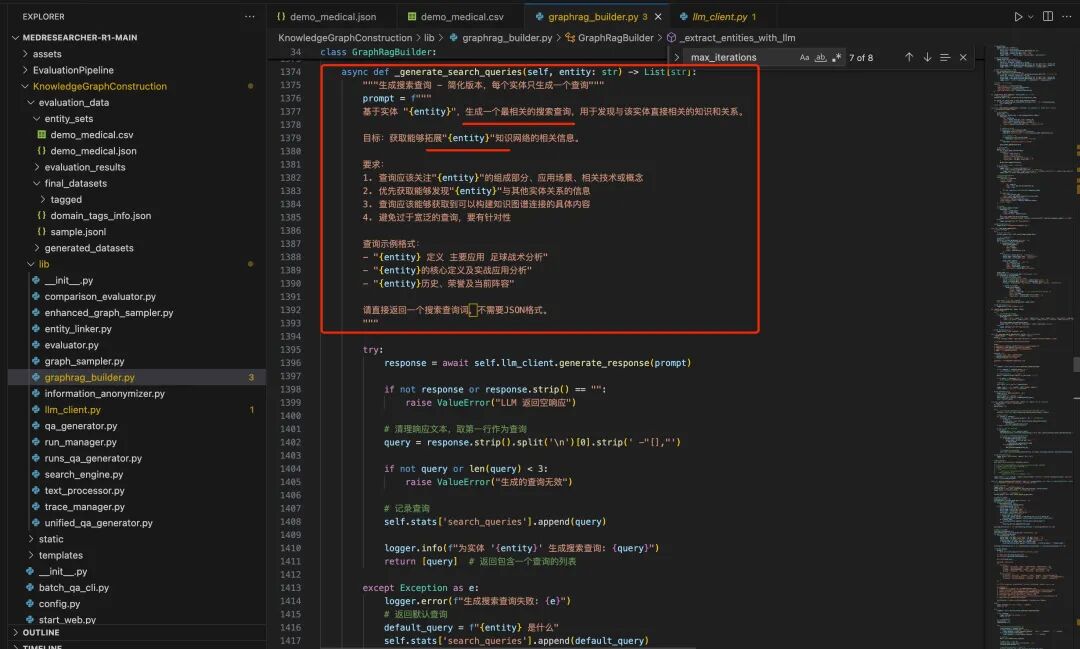
请求互联网网页内容的过程在https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/KnowledgeGraphConstruction/lib/search_engine.py,这个在AI搜素领域也是常用。
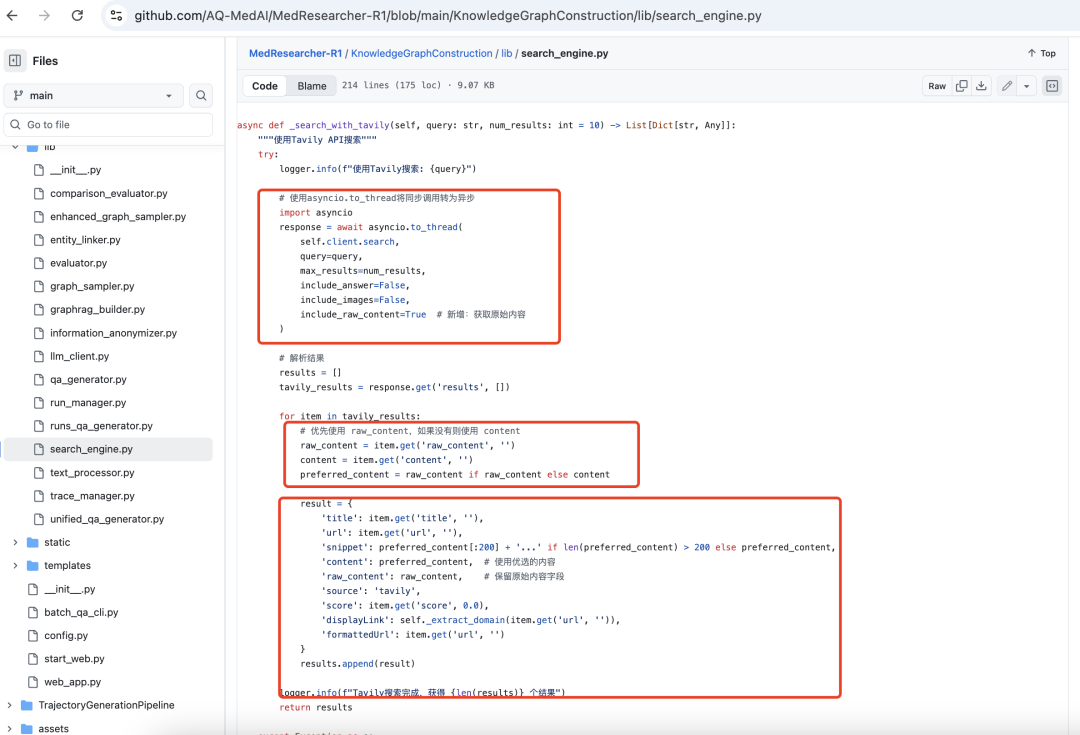
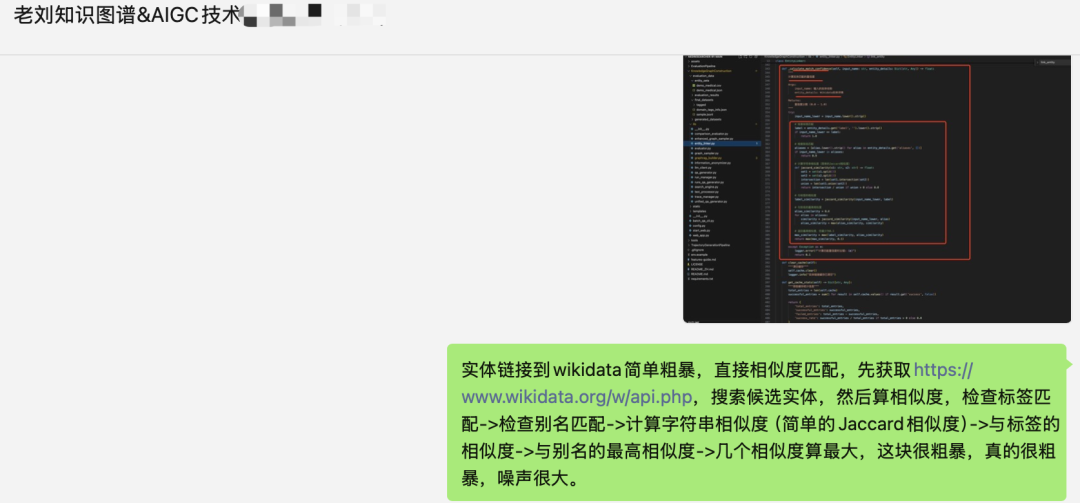
实体链接到wikidata简单粗暴:
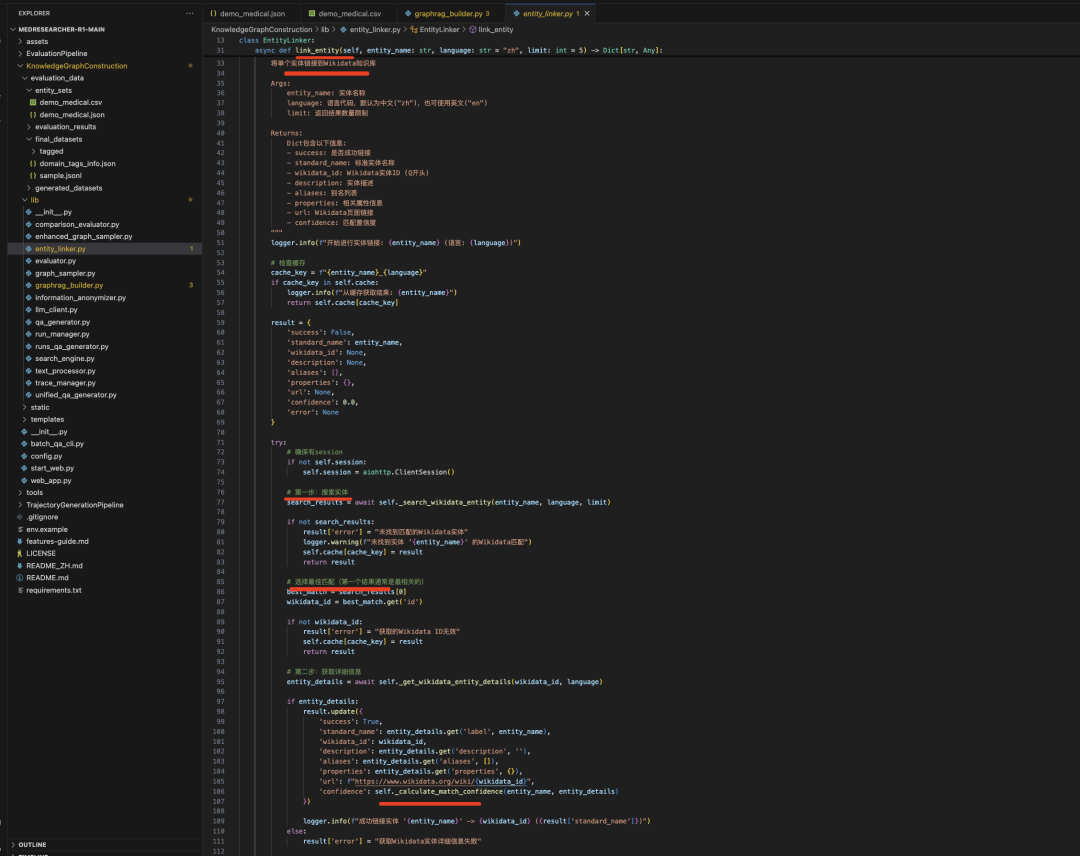
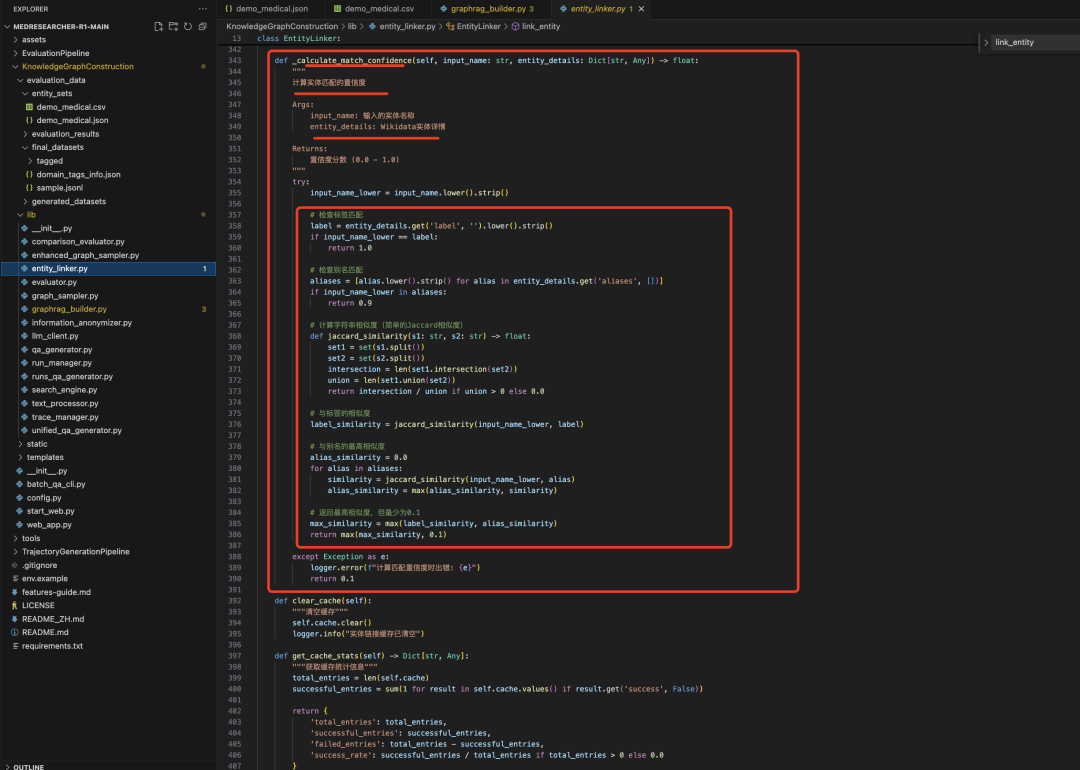
直接相似度匹配,先获取https://www.wikidata.org/w/api.php,搜索候选实体,然后算相似度,检查标签匹配->检查别名匹配->计算字符串相似度(简单的Jaccard相似度)->与标签的相似度->与别名的最高相似度->几个相似度算最大,这块很粗暴,真的很粗暴,噪声很大。
二、InfoSeek基于通用百科超链接合成推理数据
InfoSeek 框架,OPEN DATA SYNTHESIS FOR DEEP RESEARCH,https://arxiv.org/pdf/2509.00375,https://github.com/VectorSpaceLab/InfoSeek/blob/main/infoseek/data_construction/ConstructTreeData.py,从维基百科中构建多跳推理路径,为深Deep Research任务合成数据集,核心就是下面这个依赖:

直白理解就是:
InfoSeek,在answer已知,通过维基百科实体,超链接游走的方式,来获取process为中间多跳路径中间过程,来最终生成questioin,形成<question ,process, answer>这种具有顺序、依赖关系的多步骤动作预测、搜索网页的过程。
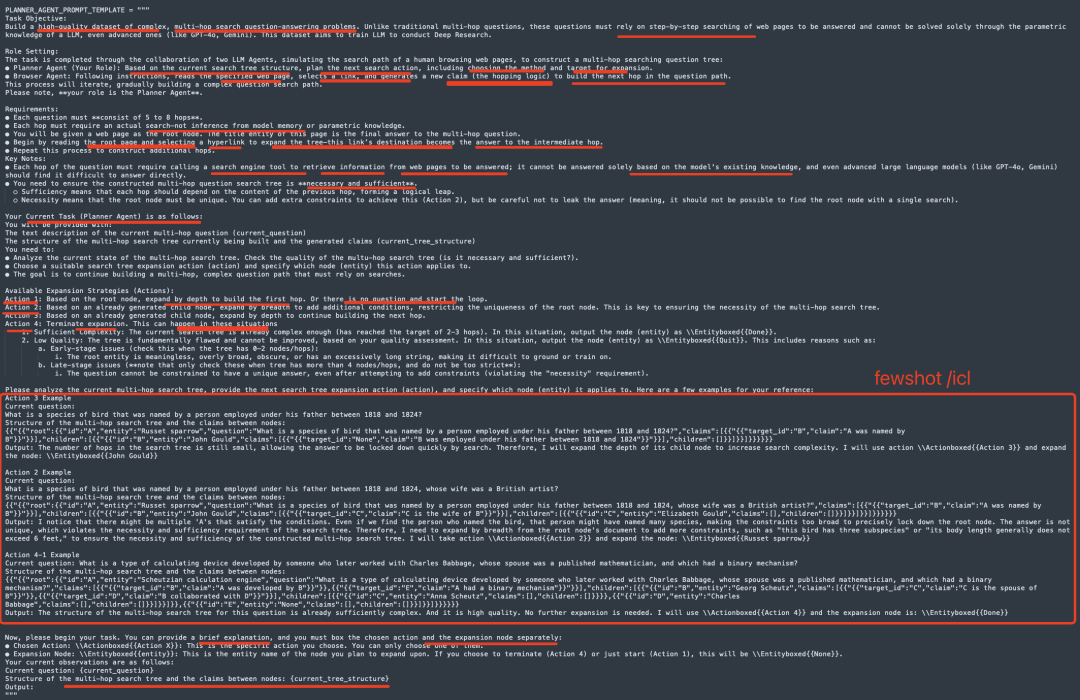
核心思路是将DeepResarch任务形式化为层次约束满足问题,每个层次的约束都依赖于下一层的满足情况,并将这种结构化的推理过程通过树形结构来表示,其中每个节点代表一个子问题,边代表实体之间的逻辑关系。通过Planner Agent 和 Browser Agent从网页中递归构建,并将中间节点模糊化为有效的子问题,并将这些树转换为需要遍历整个层次结构的自然语言问题。
实现步骤为:1)初始化(从维基百科和网页中选择一个实体作为研究树的根节点)->2)模糊父节点(通过增加约束条件来模糊父节点,确保每个节点都有足够的约束来唯一确定答案)->3)扩展树(通过添加新的子节点来增加树的深度,每个新节点代表一个新的实体或事实->4)终止和问题生成(当研究树达到所需的复杂度时,生成最终的自然语言问题)。
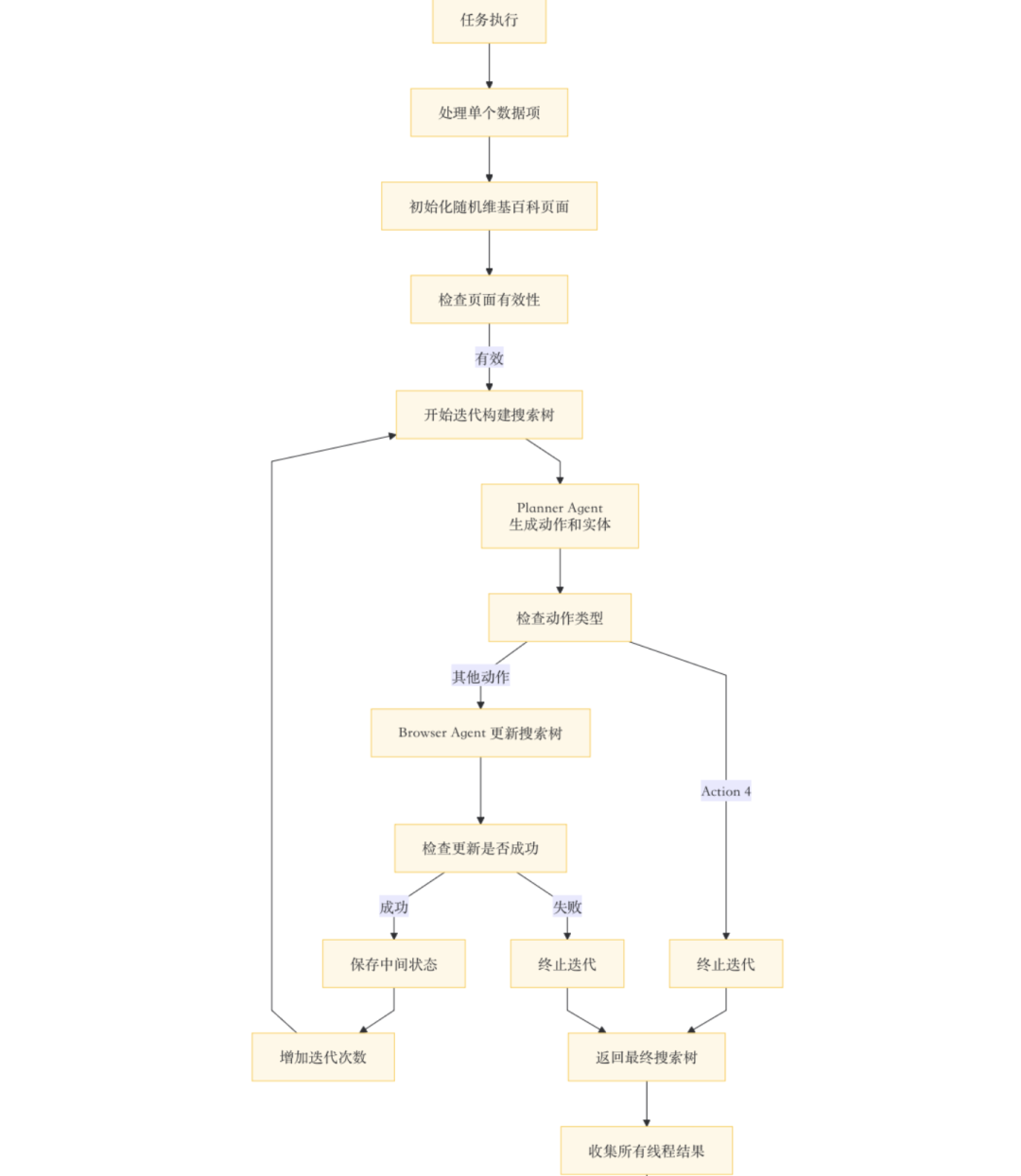
从代码上来拆解:https://github.com/VectorSpaceLab/InfoSeek/blob/main/infoseek/data_construction/ConstructTreeData.py
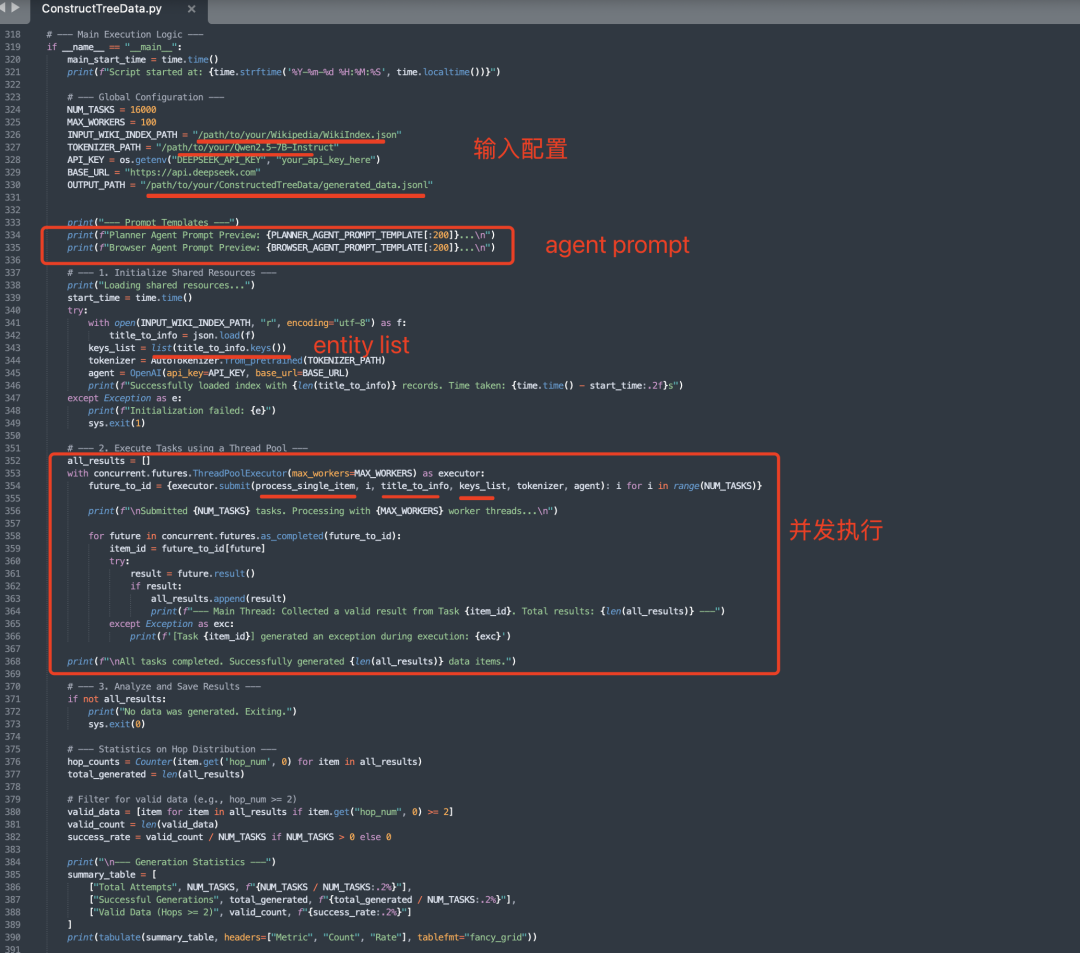
核心就是这个搜索树,具体执行步骤:
输入的是wikipedia的页面,两个agent,分别是PlannerAgent和BrowserAgent,根据wikipedia进行随机采样实体,送process_single_item做处理,负责构建单个数据项的多跳推理路径(搜索树),这个是整个工作的核心:
1)初始化随机维基百科页面,随机选择一个页面标题,从title_to_info中获取该页面的位置信息,从文件中读取该页面的内容,检查页面内容是否有效(文本长度大于10),如果有效,对页面内容进行截断处理,确保其长度符合要求如果10次尝试后仍未找到有效页面,任务终止
->2)初始化变量,包括current_action当前动作、current_search_tree当前搜索树、iter_num当前迭代次数、max_iter_num最大迭代次数(5次)以及all_tree_states保存所有中间状态的列表
->3)迭代构建搜索树,当前动作不是“Action4”(终止标识)且迭代次数小于最大迭代次数时,继续迭代
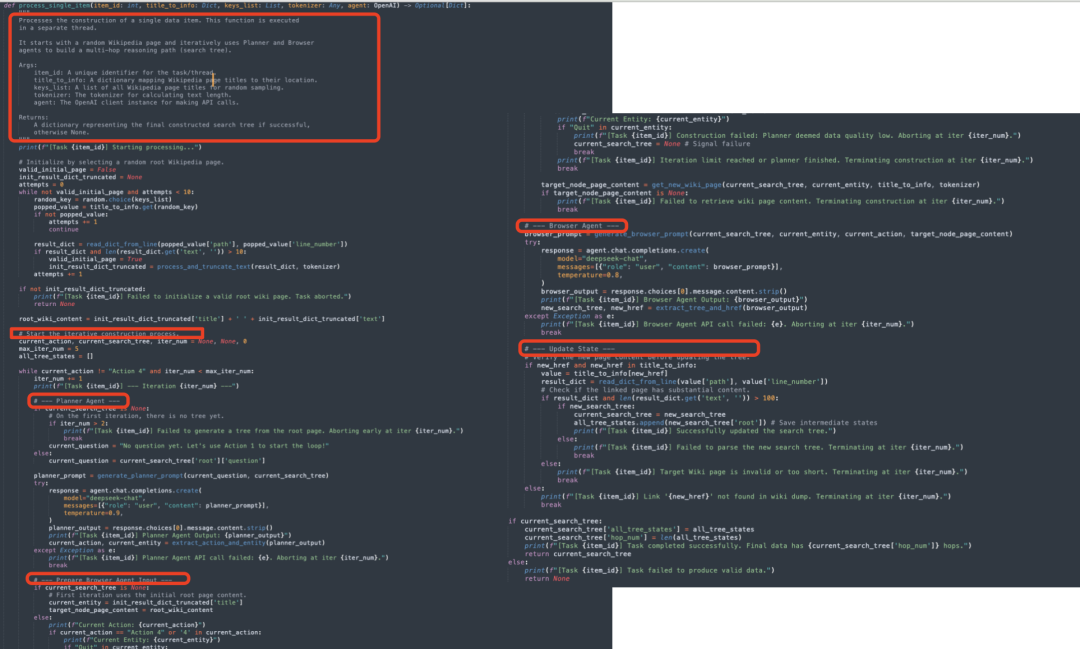
->4)单次迭代,使用PlannerAgent生成当前动作和实体,如果当前没有搜索树,使用默认问题启动循环,生成PlannerAgent的提示,调用OpenAIAPI获取PlannerAgent的输出,从输出中提取动作和实体,如果API调用失败,任务终止。其审查当前搜索树的结构,并策略性地决定下一步的构建动作(Action)和要操作的节点(Entity)。
对应的prompt如下:
->5)BrowserAgent根据当前动作和实体,获取目标节点的页面内容,如果当前没有搜索树,使用初始页面内容。如果动作是“Action4”(终止标识),检查是否需要终止。否则,调用get_new_wiki_page获取目标节点的页面内容,如果无法获取页面内容,任务终止->生成BrowserAgent提示,调用OpenAIAPI获取BrowserAgent的输出,从输出中提取新的搜索树和链接;
BrowserAgent:作为PlannerAgent负责接收指令,阅读指定网页的内容,并通过扩展操作更新搜索树。输入的信息包括1)Current_Search_Tree:一个JSON对象,表示到目前为止构建的多跳问题搜索树的完整结构;2)Entity_To_Expand:一个字符串,表示PlannerAgent指令中要扩展的实体名称;3)Action_To_Execute:一个字符串,表示PlannerAgent决定执行的具体动作。
Action1:基于根节点的网页文档,执行深度扩展以构建第一跳;Action2:基于某个节点的网页文档,执行广度扩展以添加约束条件,使节点更模糊但确保唯一性;Action3:基于某个节点的网页文档,执行深度扩展以增加搜索跳数;Action4:终止扩展。原因可能是当前搜索树已经足够复杂(超过5个节点),或者当前节点实体与网页内容无法以有价值的方式扩展。4)Target_Node_Page_Content:一个长字符串,包含要分析的网页内容(纯文本格式,包括超链接标签,如<ahref="political/20philosophy">politicalphilosophy),网页内容对应于Action_To_Execute指向的目标节点。
对应的prompt如下:
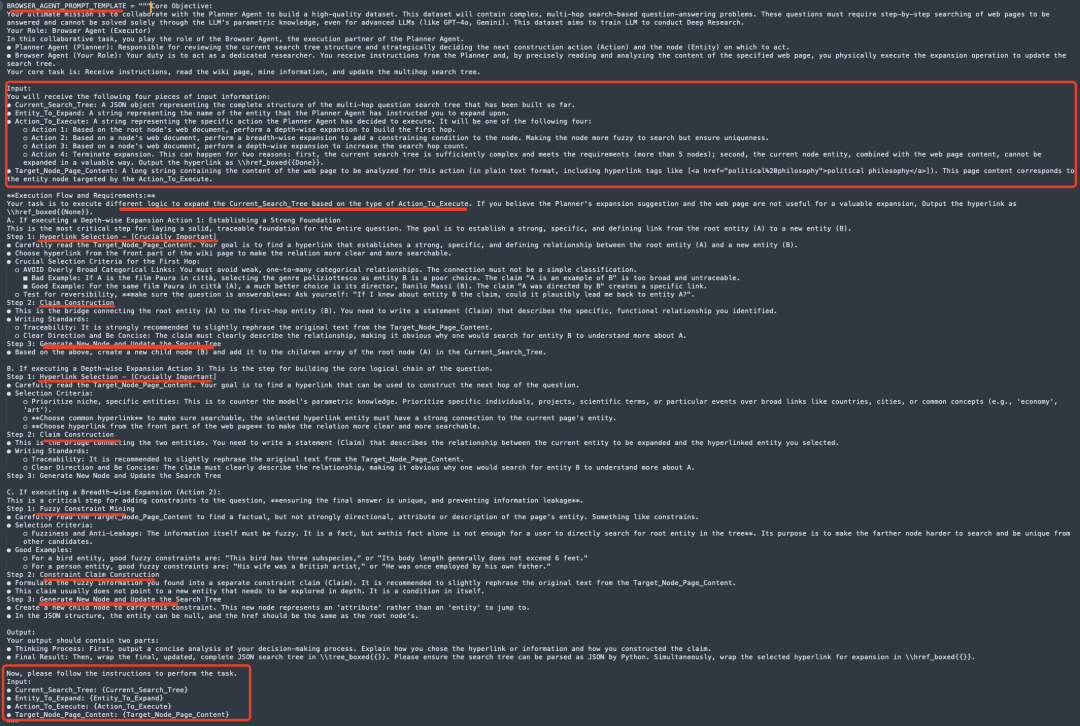
->6)更新搜索树,验证新页面内容并更新搜索树。检查新链接是否有效。从文件中读取新页面的内容,检查页面内容是否有效(文本长度大于100),如果新搜索树有效,更新当前搜索树并保存中间状态。
所以,这么一拆解,思路大致就清楚了,整个的合成的目标,其实就是做<question, process, answer>这个三元组。
其中,answer就是维基百科的一个词条。然后这个process就是靠这个树来组织,也就是答案是已知的,那么就根据这个初始维基百科的词条的内容,本身可以生成一跳的问题(比如已知巴黎这个词条,可以生成【“法国的首都是哪儿?】这个问题。
为了生成二跳,去找它的页面超链接,比如里面提到的法国,构成二跳实体,然后,为了回答法国这个实体,又可以扩展一次,如扩展成西班牙,西班牙跟法国接壤,这样question又可以变成【"跟西班牙接壤的国家首都是哪个?"】的问题,进而,又可以把西班牙这个实体作为一个答案再去找西班牙的词条,然后不断扩展,比如生成【跟一项斗牛活动紧密相关国家接壤的国家首都是什么】的三跳问题。
但会出现一个歧义性问题,跟斗牛活动相关的国国家会有很多,跟西班牙接壤的国家又有很多,所以这个时候需要加一个claim作为约束条件,比如西班牙的领导人唯一的确定到西班牙,法国的也有一个claim,比如有著名埃菲尔铁塔建筑;因此,这么一组织,从原始节点出发,逐步到二跳、三跳,往后走,都是前面的children节点,这个其实就process。然后,最终综合所有多跳实体,然后最终生成一个question。
豁然开朗。
也就是如下这个数据:

参考文献
1、https://arxiv.org/pdf/2509.0037
2、https://github.com/AQ-MedAI/MedResearcher-R1
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









