



 本文介绍了如何使用Python的pandas库读取和写入Excel文件。通过`read_excel`函数,可以方便地加载Excel数据,如示例中展示了从data.xlsx读取数据并调整索引来匹配实际需求。同时,利用`to_excel`函数,可以将DataFrame数据写入到Excel文件,如创建economy.xlsx的例子所示。这些功能使得在数据处理和分析中,pandas成为Excel的有效补充工具。
本文介绍了如何使用Python的pandas库读取和写入Excel文件。通过`read_excel`函数,可以方便地加载Excel数据,如示例中展示了从data.xlsx读取数据并调整索引来匹配实际需求。同时,利用`to_excel`函数,可以将DataFrame数据写入到Excel文件,如创建economy.xlsx的例子所示。这些功能使得在数据处理和分析中,pandas成为Excel的有效补充工具。

前言
之前我们介绍了pandas读写csv文件,json文件,本篇文章我们来介绍一下pandas读写Excel文件。
关于Excel
Excel 是由微软公司开发的办公软件之一,它在日常工作中得到了广泛的应用。在数据量较少的情况下,Excel 对于数据的处理、分析、可视化有其独特的优势,因此可以显著提升您的工作效率。但是,当数据量非常大时,Excel 的劣势就暴露出来了,比如,操作重复、数据分析难等问题。Pandas 提供了操作 Excel 文件的函数,可以很方便地处理 Excel 表格。
数据准备
我们获取到2022年部分省份的经济数据,将数据整理到一个Excel文件中,命名为data.xlsx,部分数据如下图所示:
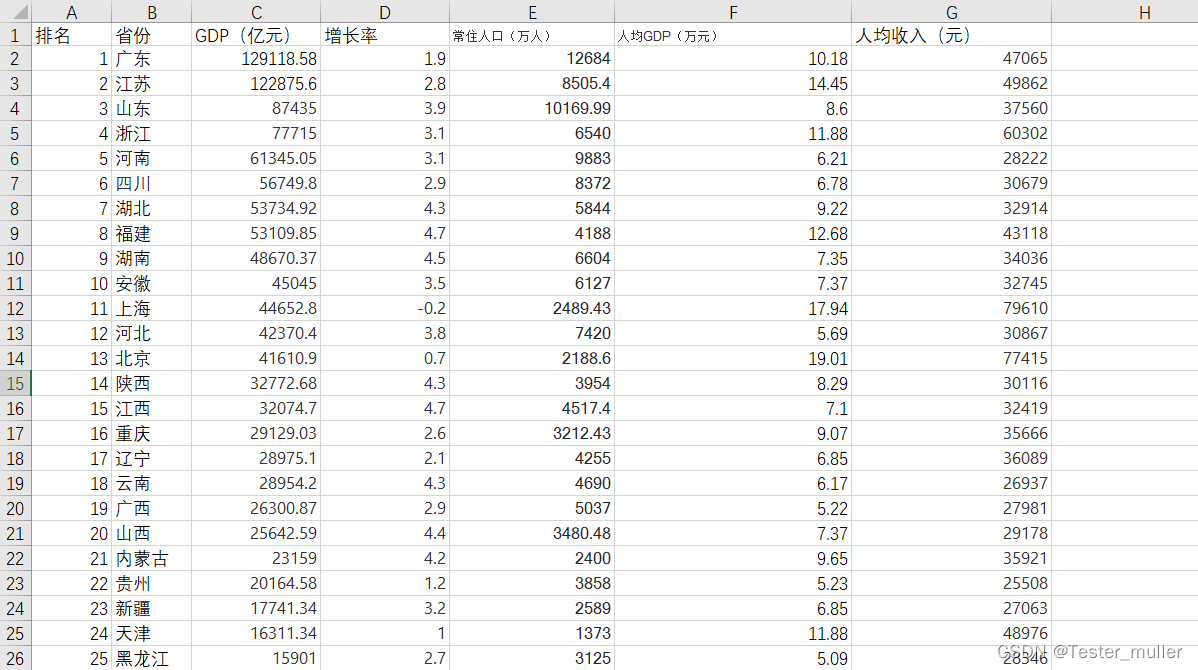
读取数据
pandas提供了read_excel()方法读取Excel中的数据,具体使用方法如下:
import pandas as pd
df = pd.read_excel('data.xlsx')
print(df)
------------------------------
输出结果如下:
排名 省份 GDP(亿元) 增长率 常住人口(万人) 人均GDP(万元) 人均收入(元)
0 1 广东 129118.58 1.9 12684.00 10.18 47065
1 2 江苏 122875.60 2.8 8505.40 14.45 49862
2 3 山东 87435.00 3.9 10169.99 8.60 37560
3 4 浙江 77715.00 3.1 6540.00 11.88 60302
4 5 河南 61345.05 3.1 9883.00 6.21 28222
5 6 四川 56749.80 2.9 8372.00 6.78 30679
6 7 湖北 53734.92 4.3 5844.00 9.22 32914
7 8 福建 53109.85 4.7 4188.00 12.68 43118
8 9 湖南 48670.37 4.5 6604.00 7.35 34036
9 10 安徽 45045.00 3.5 6127.00 7.37 32745
10 11 上海 44652.80 -0.2 2489.43 17.94 79610
11 12 河北 42370.40 3.8 7420.00 5.69 30867
12 13 北京 41610.90 0.7 2188.60 19.01 77415
13 14 陕西 32772.68 4.3 3954.00 8.29 30116
14 15 江西 32074.70 4.7 4517.40 7.10 32419
15 16 重庆 29129.03 2.6 3212.43 9.07 35666
16 17 辽宁 28975.10 2.1 4255.00 6.85 36089
17 18 云南 28954.20 4.3 4690.00 6.17 26937
18 19 广西 26300.87 2.9 5037.00 5.22 27981
19 20 山西 25642.59 4.4 3480.48 7.37 29178
20 21 内蒙古 23159.00 4.2 2400.00 9.65 35921
21 22 贵州 20164.58 1.2 3858.00 5.23 25508
22 23 新疆 17741.34 3.2 2589.00 6.85 27063
23 24 天津 16311.34 1.0 1373.00 11.88 48976
24 25 黑龙江 15901.00 2.7 3125.00 5.09 28346
25 26 吉林 13070.24 -1.9 2375.37 5.50 27975
26 27 甘肃 11201.60 4.5 2490.02 4.50 23273
27 28 海南 6818.22 0.2 1020.46 6.68 30957
28 29 宁夏 5069.57 4.0 725.00 6.99 29599
29 30 青海 3610.10 2.3 594.00 6.08 27000
30 31 西藏 2132.64 1.1 366.00 5.83 26675
注:使用pandas读取Excel数据时,需要提前安装openpyxl库。
我们可以发现,索引和我们需要的实际排名刚好差了1,我们想要将索引去掉,直接以排名做索引应该如何操作呢? pandas提供了index_col参数来解决这个问题,我们使用这个参数就可以实现我们的需求,代码如下:
import pandas as pd
df = pd.read_excel('data.xlsx', , index_col='排名')
print(df)
---------------------------
输出结果如下:
省份 GDP(亿元) 增长率 常住人口(万人) 人均GDP(万元) 人均收入(元)
排名
1 广东 129118.58 1.9 12684.00 10.18 47065
2 江苏 122875.60 2.8 8505.40 14.45 49862
3 山东 87435.00 3.9 10169.99 8.60 37560
4 浙江 77715.00 3.1 6540.00 11.88 60302
5 河南 61345.05 3.1 9883.00 6.21 28222
6 四川 56749.80 2.9 8372.00 6.78 30679
7 湖北 53734.92 4.3 5844.00 9.22 32914
8 福建 53109.85 4.7 4188.00 12.68 43118
9 湖南 48670.37 4.5 6604.00 7.35 34036
10 安徽 45045.00 3.5 6127.00 7.37 32745
------
# 篇幅所限没有将全部输出复制过来
写入数据
pandas同样可以向Excel文件中写入数据,通过 to_excel() 函数可以将 Dataframe 中的数据写入到 Excel 文件。如果想要把单个对象写入 Excel 文件,那么必须指定目标文件名;如果想要写入到多张工作表中,则需要创建一个带有目标文件名的ExcelWriter对象,并通过sheet_name参数依次指定工作表的名称。示例代码如下:
import pandas as pd
#创建DataFrame数据
info_enonomy = pd.DataFrame({'国家': ['美国', '中国', '日本', '德国', '印度', '英国', '法国', '意大利', '加拿大', '韩国'],
'排名': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'地域': ['北美洲', '亚洲', '亚洲','欧洲', '亚洲', '欧洲', '欧洲', '欧洲', '北美洲', '亚洲' ],
'GDP': [22.94, 16.86, 5.1, 4.23, 3.11, 2.95, 2.94, 2.12, 2.02, 1.82]})
#创建ExcelWrite对象
writer = pd.ExcelWriter('economy.xlsx')
info_enonomy.to_excel(writer)
writer.save()
print('输出成功')
生成的Excel表格如下:
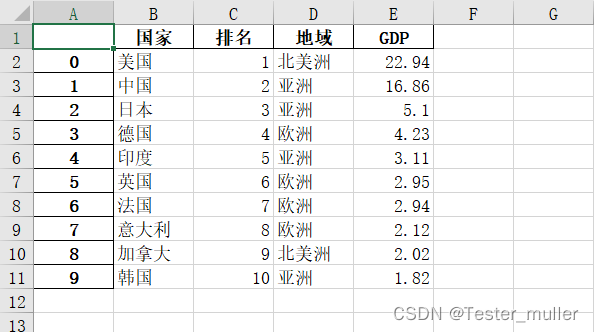
总结
本文主要介绍了使用pandas读取和写入Excel文件的方法,后面我们将介绍pandas对时间的处理。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









