




 深度卷积神经网络在图像分类领域取得了显著成就。ResNet通过引入残差学习机制解决了深层网络的退化问题,允许网络层数进一步增加而不损失性能。本文详细介绍了ResNet的工作原理、网络结构及其实现细节。
深度卷积神经网络在图像分类领域取得了显著成就。ResNet通过引入残差学习机制解决了深层网络的退化问题,允许网络层数进一步增加而不损失性能。本文详细介绍了ResNet的工作原理、网络结构及其实现细节。
ResNet
Introduction
深度卷积神经网络曾在图像分类领域做出了重大突破。
深度网络可以吸收各种维度层次的特征,而这个特征的深度我们可以通过加深神经网络层数来得到。
我们知道网络深度是一个非常重要的影响网络性能的因素。很多的图像领域的神经网络模型也都是基于比较深层次的网络结构的。
但这样深层次的网络结构是否容易训练,容易学习样本分布呢?
出现的问题
大家应该也都知道,梯度爆炸和梯度消失的问题在深度学习中经常会出现,这极大的影响了我们训练的收敛性。 但是这个问题在一些中间层或预处理层添加一些标准化操作就可以解决。
但另一个问题也出现了,那就是退化问题。当我们把网络层数加深之后,准确率开始慢慢变得饱和,但再增加层数之后,准确率会下降。 但这个问题并不是由过拟合导致的,而且在我们添加更多的网络层之后,训练误差会随之上升。
这个退化问题表明,并不是所有的系统都是那么容易去优化的。让我们考虑一个浅层的结构,以及一个特殊的深层网络模型(是结构A加上更多的网络层)。
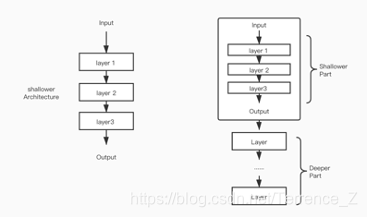
对于那个深层的网络模型,作者做了一个处理,就是在deeper part的layer全部做identity mapping,也就是恒等映射,shallower part 是跟对比的那个浅层模型相同的,这样的话,深层模型就不会比浅层模型产生更高的训练误差。
基于这个思想,deep residual learning framework就应运而生了。与传统的将堆叠层去学习样本分布不同,ResNet 是去学习残差的映射的。
残差学习
那为什么这个学习是残差学习呢?
我们是将堆叠层的学习目标改为残差F(x) = H(x) – x,但最终输出的feature map还是H(x) = F(x) + x,所以我们添加一个shortcut在堆叠层的输入之后,得到F(x) + x。
这里,在极端情况下,如果我们假设恒等映射是最优的情况,我们会更容易将残差去降低到0,而不是通过多层非线性层,去将输出接近identity mapping. 也就是说残差映射会比原先的映射要更容易优化,
我们这里可以把F(x) + x看作是一个前向神经网络加上一个短路连接。(也就是在ppt上展示的residual Unit。),短路连接通常会跳过一层或多层的网络层(在ResNet中,都是多层),而且这个shortcut connection是由恒等映射计算的,并且结果会与跳过的网络层输出结合起来,由于恒等映射不会添加任何的参数,而且也不会提高任何的计算复杂度。
如果我们将H(x)设为堆叠层需要去拟合的映射的话,如果非线性堆叠层能拟合H(x),那也意味着非线性堆叠层能拟合残差方程H(x) – x,所以我们可以直接将非线性堆叠层的目标设为F(x) = H(x) – x。这样的话,就如我们之前所说,原先学习的目标就变为了F(x) + x。
Y=F(Xi,ωi)+xY=F(X_i, \omega_i) + xY=F(Xi,ωi)+x
这里F(x,wi)表示了需要学习的残差映射,比如在我们之前看到的Residual unit里,有两层网络加上一个shortcut connection。
这里F=ω2σ(ω1x)F = \omega_2\sigma(\omega_1x)F=ω2σ(ω1x)
这里sigma代表relu function.
我们在网络结构中可以看出,他们的参数数量,深度,广度,以及计算代价都是一样的。
这里x和F的维度必须相同,如果不是的话,我们需要添加一个线性映射Ws来处理shortcut connections。
即变为:y=F(x,ωi)+ωsxy = F(x, \omega_i) + \omega_sxy=F(x,ωi)+ωsx
Shortcut connection 需要跳过两个或多个网络层,不然的话,以上的方程就会变成一个线性变换, y=ω1x+xy = \omega_1x + xy=ω1x+x,就没有任何的优点了。
网络结构
论文中plain network 是基于VGG nets的网络结构的。

卷积层基本都由3*3的filter 组成。
同时ResNet有两个简单的设计原则:
- 若输出的特征图 相同的情况下,卷积层有着同样数量的filter
- 若feature map的大小变成了一半,那么卷积层的filter 数量就会成为两倍。来保持各层之间时间复杂度的相同。
同时使用了步长为2的下采样卷积层。
网络的最后,使用了全局平均池化层,以及1000维的线性层和softmax函数。
Ps: FLOP:每秒所执行的浮点运算次数
Residual network
在之前介绍的plain network结构之上,增加了shortcut connections(短路连接)
当输入和输出的维度一样的时候,短路连接可以直接使用,但如果维度增加的时候(也就是图中的虚线连接的时候),作者采取了两种措施:
- 短路连接仍旧采用恒等映射,但会通过零padding来提高维度,这个做法没有添加新的参数
- 第二个做法是在短路连接上不用恒等映射而是通过一层卷积层,卷积核是1*1的大小。

Details
Plain networks:
比较18-layer and 34-layer plain nets的话,会发现34层的结构比18层的结构有更高的测试误差,观察training / validation error的话,我们可以发现在训练过程中,出现了退化问题。
Residual network:
每对3*3的卷积核添加一个shortcut connection
都用恒等映射,对增加的dimension使用zero-padding来处理。
通过18-layer的ResNet和plain net的比较可以看出,ResNet在早期就可以让SGD更快的优化网络。
比较了三种shortcut connection的方法:
- 全都使用恒等映射
- 在需要提高维度的shortcut使用卷积,其他使用恒等映射
- 全都使用卷积
效果是3>2>1, 但是差距比较小,而且内存和时间复杂度会提升很多。所以在之后的结果讨论中,都使用了第一种shortcut
ResNet50的结构与ResNet34的结构不同,是每三个卷积层加一个shortcut,使用第二种shortcut
】


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









