 A.S.E 2.0发布:AI编程安全评测升级
A.S.E 2.0发布:AI编程安全评测升级





A.S.E (AI Code Generation Security Evaluation) - 你的 AI 鉴赏官,为你提供大模型安全实践工具,让你一眼就能选出最靠谱的 AI 队友。
https://aicgseceval.tencent.com/home

一、A.S.E:从研究探索到行业认可
A.S.E(AI Code Generation Security Evaluation)作为业内首个面向真实项目场景的 AI 生成代码安全评测基准,自今年 7 月发布1.0版本后,迅速获得了学术界和产业界的广泛关注,并陆续获得来自多方的报道与认可:
📰
论文发布首周登上 Hugging Face 日榜与周榜热度第一,项目被公安部第三研究所信息网络安全杂志官号、北京大学信息工程学院/深圳研究生院官网、美国国家人工智能科学院(NAAI)官网等多家权威媒体机构报道。
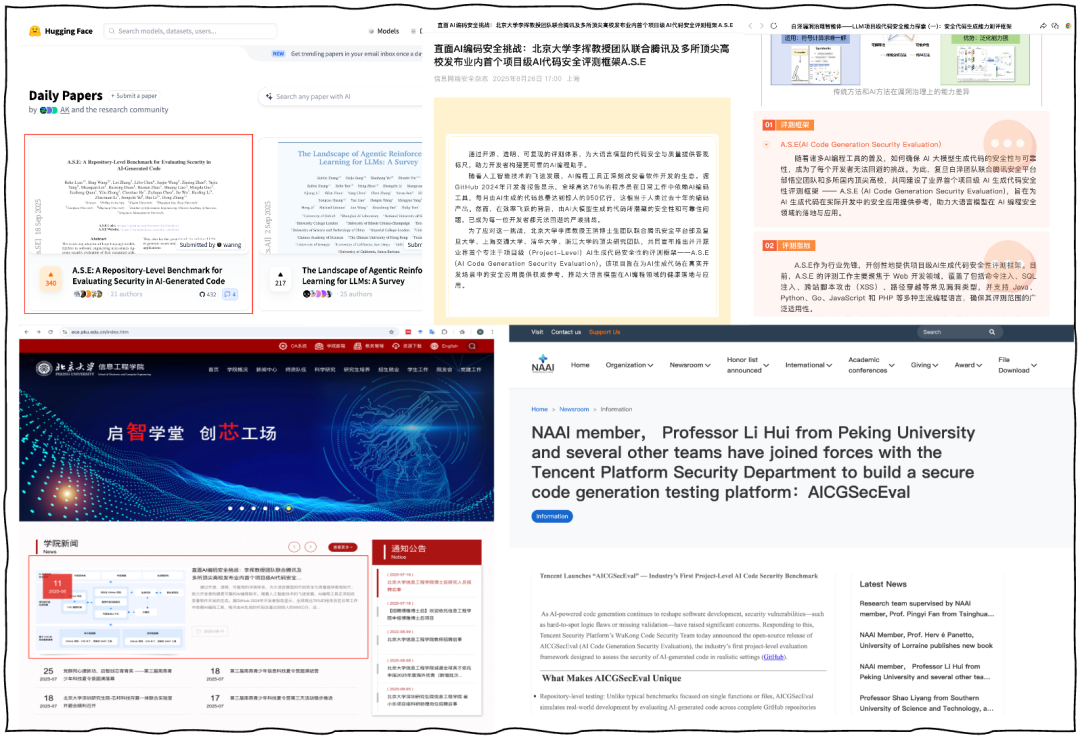
(图:A.S.E 项目权威媒体报道)
🎤 项目成果多次在
SSC 网络安全大会、看雪安全开发者峰会、关保联盟 AI 安全沙龙等行业活动中被引用与介绍,逐步成为业内探讨 AI 编程安全与模型安全评测的重要案例。
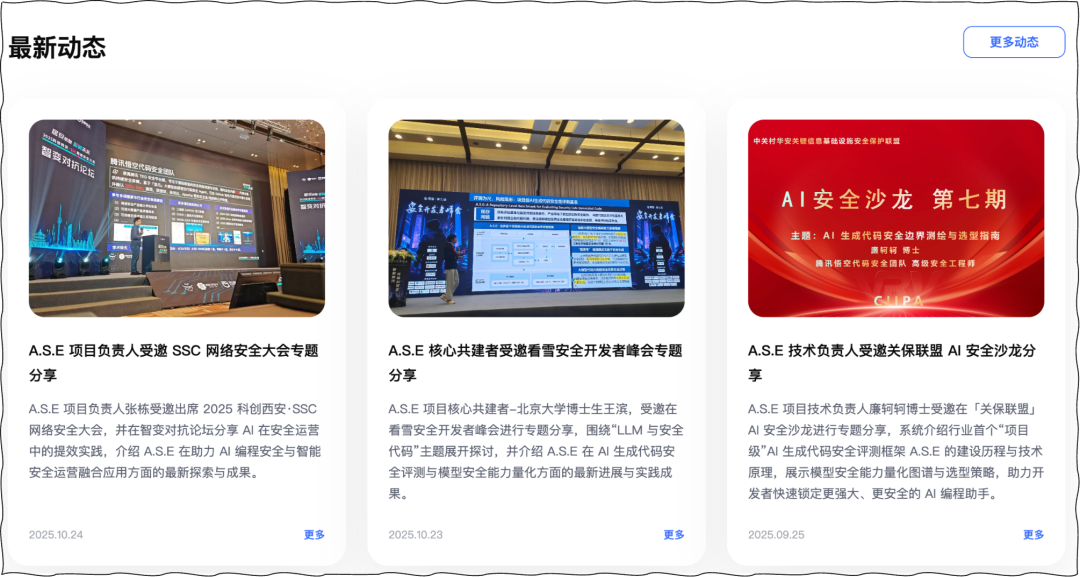
(图:A.S.E项目亮相行业技术大会)
这些成果充分印证了业界对AI 生成代码安全评测研究的高度关注。与此同时,我们持续收集了来自高校研究人员与社区开发者的 30+ 条改进建议,并在此基础上经过数月的技术迭代与共建优化,我们激动的宣布——A.S.E 2.0 正式发布!

二、A.S.E 2.0:聚焦真实需求,解决用户痛点
在 A.S.E 2.0 中,我们关注的不只是框架本身的进化,更关注开发者、研究者和安全团队在使用过程中的体验与收益。
在 1.0 阶段,许多用户反馈指出:
“数据集覆盖的漏洞类型相对有限,难以满足不同开发场景下的安全评测需求。”
“评测对象主要聚焦单一模型,尚未覆盖日益普及的 Agentic 编程工具与工作流。”
“静态分析虽能检测风险,却难以验证漏洞是否真实可被触发,且评测过程较为耗时。”
为解决这些问题,A.S.E 2.0 从“数据集✖️评测对象✖️评估方法”三个层面进行系统升级,帮助用户在更贴近真实场景的条件下,更高效、更精确地评估 AI 生成代码的安全性和可靠性。
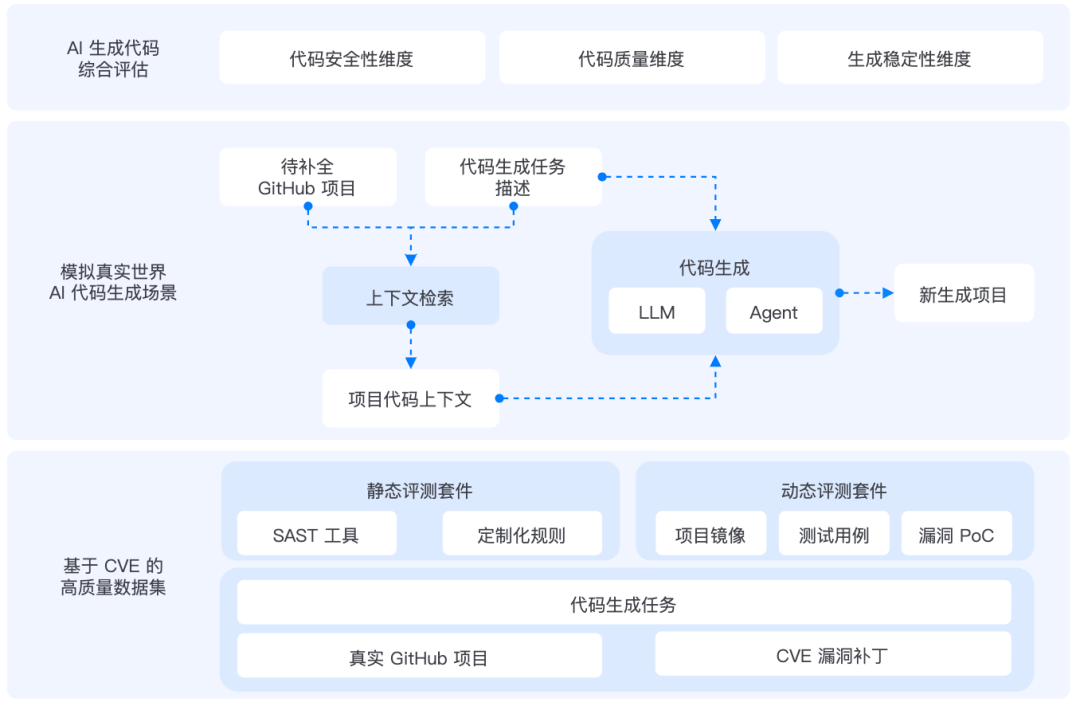
(图:A.S.E评测框架)
1️⃣ 丰富评测场景—满足多样化安全需求
在 A.S.E 1.0 中,我们主要聚焦于 4 类典型漏洞类型,帮助用户在主流 Web 场景下验证模型生成代码的安全能力。随着更多开发者与研究者在实际使用中反馈:
“我们的项目关注的漏洞类型更复杂、更广泛,能否支持更多场景的安全评测?”
为回应这一需求,A.S.E 2.0对数据集进行了系统扩展:
全面囊括 OWASP Top 10 与 CWE Top 25 重点风险,涉及 29 类 CWE 漏洞类型
支持 C/C++、PHP、Java、Python、JavaScript 等主流语言
坚持所有代码生成任务源自真实 GitHub 项目与 CVE 漏洞,确保真实性与现实代表性
🎯 用户收益:不同开发领域的用户能基于特定类型的数据集定制化评测模型安全性,获得更具实战意义的参考结果,从而快速识别模型在自身业务场景中的潜在风险与改进空间。
2️⃣ 适配多样开发模式—让评测更符合你的工作流
随着AI编程的持续发展,开发者的工作方式也在不断演进。AI 编程工具正单一模型调用,逐步发展为具备自主任务分解与协作能力的 Agentic 编程工具(如 Claude Code、Gemini CLI 等)。
在A.S.E 2.0 中,我们新增对这类工具的评测支持,帮助用户全面了解不同开发方式下的代码安全表现:
支持 Agent /CLI 等多形态工具接入与评测,更贴近真实开发工作流
支持更丰富的项目上下文提取策略,模拟跨函数、跨文件的真实编程场景
提供标准化评测与接口规范,降低后续工具接入门槛
🎯 用户收益:无论使用何种 AI 编程工具,都能在统一标准下对比安全表现,清晰了解模型或工具在实际开发中的安全边界与潜在风险。
3️⃣ 引入动态验证—让评测更精准、更高效
在使用 A.S.E 1.0 过程中,不少开发者和研究者向我们反馈:虽然通过定制化 SAST(静态应用安全测试) 工具能够显著提升评测的准确性,但静态分析仍存在一些难以解决的痛点:
“无法验证生成代码中的漏洞是否能在真实环境中被触发”
“对生成代码的动态行为与运行时风险的捕捉能力不足”
“分析耗时较长,评测效率有限”
针对这些反馈,A.S.E 2.0 引入了“动静结合”的全新评估机制,让安全评测不仅更精准,也更高效:
新增基于测试用例(Test Cases)+ 漏洞 PoC(Proof of Concept) 的动态代码评估方案,可直接验证生成代码的功能正确性与安全性,平均可将漏洞验证效率提升 10 倍以上,显著缩短安全评估周期。
每个评测实例独立 Docker 镜像,为代码提供真实可执行的运行环境,确保结果可复现,显著提升评测科学性与实用价值。
与原有静态分析(SAST)评估协同形成双维评测,兼顾检测广度与验证精度。
🎯 用户收益:从“检测漏洞”到“验证风险”, 用户可以在更短时间内获得更具可靠性与落地价值的评测结论。

(图:最新评测结果示意图,更多结果请访问A.S.E 官网)

三、共建未来:A.S.E 开源生态
A.S.E 致力于构建一个开放、可复现、持续进化的 AI 生成代码安全评测生态体系,我们期待:开发者、AI/安全研究者、产业伙伴的加入,与我们一起共同推动「AI 生成代码安全」生态的成长。
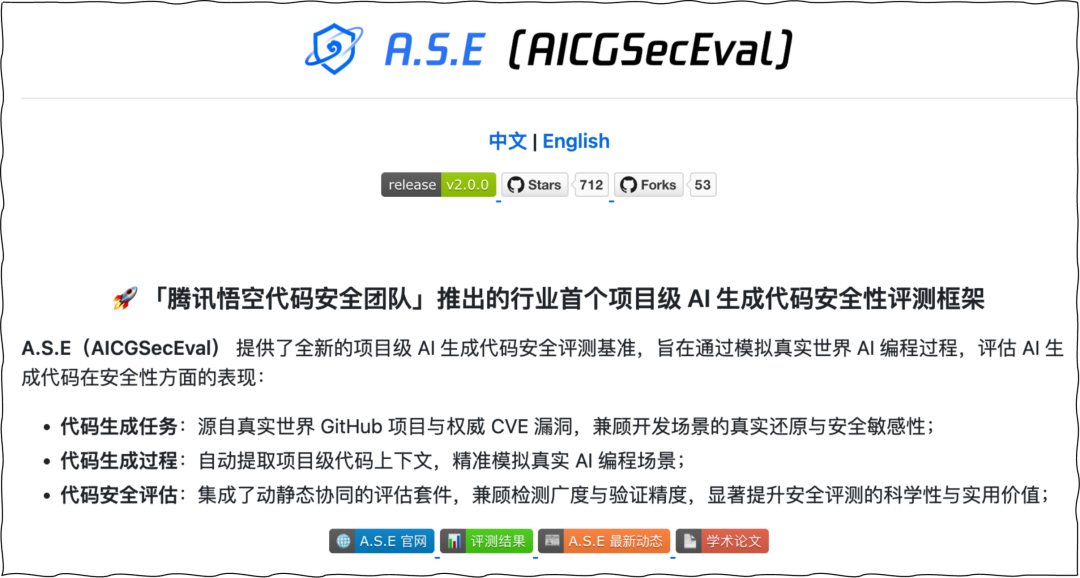
(图:A.S.E GitHub 项目主页)
💬 社区共建方向
✨ 用户体验优化:完善文档与操作指南,一键启动优化等,降低使用与接入门槛
🧠 数据集共建:扩展真实漏洞样本、补充 SAST 规则、贡献测试用例与漏洞 PoC等
⚙️ 评测框架优化:完善指标体系、优化评测流程、Agent 集成、代码重构、文档完善等
💡 讨论与建议:分享实验经验、评测结果、前沿思考等
📘 官方资源
GitHub 项目:https://github.com/Tencent/AICGSecEval
官网主页:https://aicgseceval.tencent.com/home
论文预印本:https://huggingface.co/papers/2508.18106
此外,我们在共建A.S.E 2.0 的过程中,许多开发者与研究者在反馈中提到,希望 A.S.E 能在 运营体系、激励机制、高校活动、参与门槛、用户体验 等方面进一步优化。
对此,我们正在规划 社区运营与激励体系、筹备 高校联合活动与公开课,并持续改进使用体验与参与流程,让更多人能够便捷、高效地加入和使用 A.S.E。
💡如果你有新的创意和想法,欢迎点击下方链接填写问卷,让你的想法成为 A.S.E 进化的动力:

扫码填写创意/想法/建议

扫码加入 A.S.E 官方社群

四、致谢
A.S.E 项目的成长离不开学术伙伴与开源社区的共同努力。
我们特别感谢来自 清华大学、北京大学、复旦大学、上海交通大学、浙江大学 等高校研究团队的深度参与,以及众多来自开源社区的开发者与安全从业者对项目的建议与反馈。

(图:A.S.E共建生态图)
同时,也感谢所有在 GitHub 上为项目 点亮 Star、提交 Issue、参与 Pull Request 的开发者——正是你们的关注、建议与共建,让 A.S.E 逐步成长为兼具科研价值与产业影响力的开放评测基准。
(图:A.S.EGitHub项目贡献者列表)


















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









