



 本文深入探讨了SQL中的聚合函数如AVG(), COUNT(), MAX()等的使用方法,以及GROUP BY, HAVING子句的功能与应用。同时,介绍了子查询、联结、自连接、UNION操作的细节,帮助读者掌握高级SQL查询技巧。
本文深入探讨了SQL中的聚合函数如AVG(), COUNT(), MAX()等的使用方法,以及GROUP BY, HAVING子句的功能与应用。同时,介绍了子查询、联结、自连接、UNION操作的细节,帮助读者掌握高级SQL查询技巧。
《MYSQL必知必会》12-17章
AVG()只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。为了获得多个列的平均值,必须使用多个AVG()函数。
COUNT()
使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
MAX()
在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行。
才采用distinct中,不允许使用count(distinct *)!!!DISTINCT必须使用列名
GROUP BY ()
使用WITH ROLLUP关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值 (个人觉得没有意义)
SELECT 初始评级,COUNT(*)
FROM 拍拍贷.LC
GROUP BY 初始评级 WITH ROLLUP
返回结果如下:
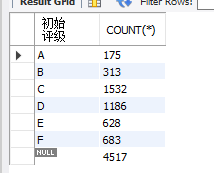
对分组过滤 用HAVING
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。

子查询:
列必须匹配 在WHERE子句中使用子查询(如这里所示),应该保证SELECT语句具有与WHERE子句中相同数目的列。通常,
子查询将返回单个列并且与单个列匹配,但如果需要也可以使用多个列。
相关子查询(correlated subquery) 涉及外部查询的子查询。
联结:
可伸缩性(scale) 能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称之为可伸缩性好(scale well)。
SELECT vend_name,prod_name ,prod_price
FROM vendors,products
WHERE vendors.id=products.id
order by vend_name,prod_name
笛卡儿积(cartesian product) 由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘
以第二个表中的行数。
自连接
SELECT p1.prod_id,p1.prod_namr
FROM products p1, products p2
where p1.venid=p2.venid and p2.prod_id="wrong"
join(),left join(),right join()
UNION

UNION规则:
1.UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合4条SELECT语句,将要使用3个UNION关键字)。
2.UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
3. 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
使用 UNION ALL 则不取消重复的行。
在用UNION组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









