




Linux篇
- cd :进入文件夹
- cd..:返回上一级文件夹
- ls:列出当前目录下的所有文件夹
- cp:复制文件夹
- mv:移动文件夹
- rm:删除文件
- rm –rf:强制删除
- rmkdir:删除空目录
- mkdir:创建文件夹
- touch:创建空文本文件
- grep:关键字过滤
- find:查找文件
- ps:查看进程,加-a显示终端上所有的进程,加-f以完整地格式显示进程信息
- top:查看所有进程动态排行,包括cup、内存等资源占用情况。默认情况下每三秒自动刷新一次
- netstat -ntlp //查看当前所有tcp端口
- netstat -ntulp | grep 80 //查看所有80端口使用情况
- 端口查看的其他指令:
-t (tcp) 仅显示tcp相关选项 -u (udp)仅显示udp相关选项 -n 拒绝显示别名,能显示数字的全部转化为数字 -l 仅列出在Listen(监听)的服务状态 -p 显示建立相关链接的程序名 - vi:文件进入编辑模式,q表示退出;w表示保存退出;q!表示强制退出;输入:不保存退出q!,保存退出 wq
- cat:查看某个文件内容
- head –n:其中n表示行数,当前命令表示查看前面N行数据,不加-n时默认显示前10行
- tail –n:其中n表示行数,当前命令表示查看最新的N行数据,不加-n时默认显示后10行
Git
- 首次克隆代码仓到本地:git clone 仓库远程复制下载地址url
- 初始化本地仓库:git init
- pull-代码复制到本地
- add-代码提交到云仓库的第一个步骤
- commit-代码提交到云仓库的第二个步骤
- push-代码提交到云仓库的最后步骤
- fetch-获取远程分支
- merge changes:拉取远程分支后,切换到master再执行merge changes可合并远程代码到当前主干上
- 回滚历史版本:show history-选择对应的版本-邮件revert
- 强制更新:git push -u origin master -f
-
切换分支:选择分支-checkout表示切换到当前选择的分支
-
合并分支:将分支dev代码合并到master上操作:
-
pull最新的master分支代码
-
pythcarm切换到master
-
master主干上选择merge Changes-选择需要合并到当前master主干的分支
-
合并的代码推送到远程master上:先git-add,后直接git-push(不要使用commited directory,否则会提示no changes)
-
13.拉取原创和本地所有分支:git branch -a (不加-a则表示展示本地分支,不展示远程分支)
SQL篇
1.单表查询
格式:SELECT * FROM 表名WHERE 条件字段='XXX'
2.多表“自关联”查询
格式:SELECT * FROM 表名1 INNER JOIN 表名2 ON 表名1. 条件字段=表名2. 条件字段WHERE 表名1.条件字段='XXX'
作用:自关联查询结果返回的是满足“ON”条件的数据
3.多表“左关联”查询
格式:select * from表名A left join表名B on表名A.条件字段 =表名B.条件字段
作用:左关联查询结果返回的是以left join左边的A表的记录为基础的,也就是说,左表(A)的记录会全部展示出来,而右表(B)只会展示符合搜索条件的记录。
4.多表“右关联”查询
格式:select * from 表名A right join 表名B on表名A.条件字段 =表名B.条件字段
作用:右关联查询结果返回的是以right join右边的B表的记录为基础的,也就是说,右表(B)的记录会全部展示出来,而左表(A)只会展示符合搜索条件的记录
5.查询指定时间区间内的数据
格式:SELECT * FROM 表名1 WHERE create_time BETWEEN '2020-11-27 00:00:00' AND '2020-12-03 23:59:59'
6.统计查询结果
格式:SELECT count(*) FROM (SELECT * FROM表名 WHERE条件字段='XXX' ) as tableA
作用:将查询结果作为新的表B,统计表B的数据总数量
7.单表修改
格式:UPDATE 表名 SET修改字段='XX' WHERE 条件字段='XXX'
8.关联表修改
格式:UPDATE 【表名1】 INNER JOIN 【表名2】 ON 【表名1. 条件字段】=表【名2. 条件字段】 SET 【表名1/2.修改字段】='XXX' WHERE【表名1/2.条件字段】='XXX'
9.指定字段插入数据
格式:INSERT INTO 【表名】 (插入数据的字段1,插入数据的字段2,插入数据的字段3) VALUES ('字段1的值', '字段1的值', '字段1的值')
liunx下操作数据库
1.展示数据库:show databases;
2.选择数据库:use 数据库名;
3.创建数据库:create database 库名;
4.创建表:create table 表名(字段设定列表);
5.查看数据库下的所有表:show tables;
6.查看表结构:describe name;
7.登录数据库:mysql -u 用户名 -p 密码
8.修改密码:
修改mysql的用户密码,分别使用grant、alter、set修改
①mysql> grant all on *.* to '用户名'@'登录主机' identified by '密码';
②mysql> alter user '用户名'@'登录主机' identified by '密码(自定义)';
③mysql> SET PASSWORD FOR '用户名'@'登录主机' = PASSWORD('密码');
修改完后需要刷新权限才可生效:flush privileges;
9.创建新用户:create user '用户名'@'%' IDENTIFIED BY '密码';
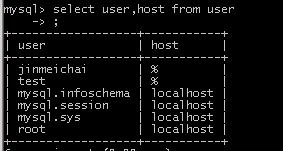
10.查询所有用户、允许通过什么ip访问数据库:select user,host from user;
11.授权权限:grant 权限 on 数据库对象 to 用户

12.允许指定用户通过所有ip访问数据库:@后面地%表示允许所有的ip
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
python篇
Python3 的六个标准数据类型中:
- 不可变数据(3 个):数字Number、字符串String、元组Tuple();
- 可变数据(3 个):列表List[]、字典Dictionary{}、集合Set。
数据类型转化:
转为str:str(x)
转为字典:dic=json.loads(x)
两个列表组合成字典:dic=dict(zip(list_a,list_b)) #其中list_a为字典的key值列表,list_b为字典的value值列表
列表添加元素:list.append(data)
读取excel----【使用xlrd模块】
详细:【实战】python-xlrd读取excel测试用例_Teamo_mc的博客-优快云博客
1.打开文件生成对象:wb=xlrd.open_workbook('文件路径')
2.读取工作表名称:sn=wb.sheet_names()
3.获取测试用例所在工作表:casesheet=wb.sheet_by_name('工作表名称')
4.获取指定单元格数据:case_data=casesheet.cell_values(x,y) #x,y分别为单元格的序号,序号从0开始
5.对获取到的单元格数据进行类型转换:
5.1转为字符串:url=str(case_data) #接口地址是字符串类型,所以读取表格数据后需要转为字符串类型
5.2转为字典:body=json.loads(case_data) #接口入参或信息头一般是json类型的,所以读取表格数据后需要转为字典类型
yaml文件:
打开yaml文件:with open('config.yaml','w',encoding='utf-8') as f:
写入数据:yaml.dump('数据',f)
读取数据:f.read()---读取地数据是str字符串格式,通过yaml.safe_load(f.read())转为dict字典格式
 https://blog.youkuaiyun.com/Teamo_mc/article/details/117985302?spm=1001.2014.3001.5501
https://blog.youkuaiyun.com/Teamo_mc/article/details/117985302?spm=1001.2014.3001.5501发起接口请求-requests库
发起get请求:request.get()
发起post请求:request.post()
发起请求:request.Request(url=,method=,data=,headers=) #根据method的入参定义是get或post请求
pytest框架
文件或函数、类必须以test开头
支持参数化@pytest.mark.parametrize()
支持跳过指定用例:@pytest.mark.skip()
支持初始化或清楚数据:@pytest.fixture()
命令运行:
运行脚本,并生成json格式报告源数据:pytest.main(['-s','test.py','--alluredir=../report/'])
将json源数据转为html:os.system('allure generate 元数据文件夹 -o html数据文件夹')
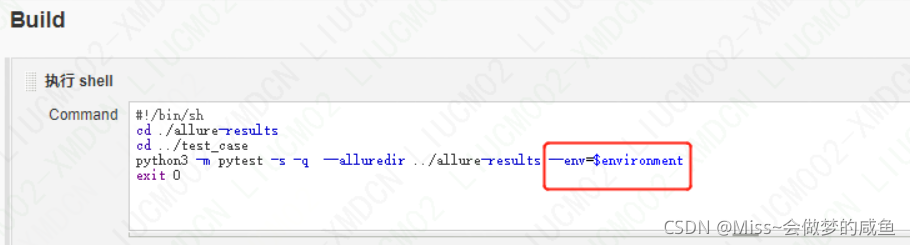
如果是集成到jenkins上,则只需要通过pytest命令运行脚本后生成json源数据即可,jenkins插件会自动将源数据转为html
Allure测试报告:
1.通过装饰器@方法定制测试报告:缺点是装饰器必须写在指定地函数方法上面。
@allure.epic() #定义项目,当有多个项目时使用,往下是feature
@allure.feature() #用例按照模块分区
@allure.story() #一个用例的描述
@allure.title() #一个用例的标题
@allure.testcase() #测试用例的连接地址,自动化用例对应的功能用例存放系统的地址
@allure.issue() #缺陷地址,对应缺陷管理系统里面的缺陷地址
@allure.description() #对测试用例的详细描述
@allure.step() #测试用例的操作步骤
@allure.severity() #用例等级-blocker/critical/normal/minor/trivial
@allure.link() #定义一个在测试报告中需要展示的链接
@allure.attachment() #添加测试报告附件
2.动态定制测试报告:优点是能在函数方法内部实现定制
如果是结合pytest参数化用例时,用装饰器地方式就不太方便定制报告内容,这个时候可以使用dynamic动态定制。
举例将用例标题换成动态地,将装饰器@allure.title() 换成allure.dynamic.title()即可。
jenkins相关操作:
构建前参数化-变量有两种类型,一个是常量,一个是选择项
在pytest运行时引用格式:pytest py脚本 -v --变量名:$变量值
python常用数据加密方式
MD5加密实现过程:
1.导入相关模块hashlib
2.创建md5对象:h1=hashlib.md5()
3.数据若为中文,则需要先进行中文加密:str='中文'.encode('utf-8')
4.对数据进行md5加密:h1.update(str)
5.获取加密后的数据:msg=h1.hexdigest()
其他加密方式ase、base64等
post和get的区别:
- 参数传递方式:get请求是url传递参数,post请求是通过body传递参数
- 参数大小限制:get请求因为url有限制长度,所以参数不能太大一般在2K-4k;post请求的参数在消息体,大小可以无限制,一般由php.ini配置决定
- 数据包数量:get请求传递一个tcp包,包含了header和data;post请求需要两个tcp,先发header给服务端,根据服务端返回的消息决定是否再发送body。
- 缓存问题:get请求能短暂的缓存在浏览器中,所以回退的时候能返回上一个页面;post请求不缓存,所以返回的话变成重新提交数据。
post请求的四种方式:
根据请求头content_type决定post请求数据的类型:
xml格式:,通过data字段传递
urlencode格式:数据以键值对的方式展示,都做url编码,通过data字段传递
json格式:数据是json格式的,可以,通过data=json.dumps(pyload)传递,也可以直接使用json=pyload传递
form-data格式:一般用于文件传递,通过data字段传递
Jmeter篇
接口基础
- 一个基础的接口请求至少包含三部分
- 设置请求信息头headers
- 发起请求:Sample(请求)
- 校验请求结果是否正确:Assertion(断言)
- 查看请求日志:Listener (监听)
- 常用的断言方式有哪些?
- 通过JSON Assertion断言
- 通过标准响应response assertion断言
- 高级的可使用BeanShell Assertion自定义脚本断言
- 使用什么定义请求的信息格式(信息头)?
Jmeter提供HTTP Header Manager,一般定义Content-Type(定义信息的格式)、charset(定义编码格式)两个字段
- 如何提取用户登录成功后的身份信息?
Jmeter提供后置提取器(Post Processors)来从接口响应数据中,提取指定的身份信息,常见的后置提取器有:
- JSON Extractor:响应体是json格式时,可通过json语法获取指定数据
- Regular Expression Extractor:响应体无指定格式时,可使用正则表达式获取指定数据
- BeanShell PostProcessor:自定义脚本断言获取指定数据
- 使用什么保存登录信息?
Jmeter提供HTTP Cookie Manager用于管理用户的登录信息,使用时需要定义使用cookie的请求地址,否则无法引用
- 接口入参参数化的方式?
Jmeter常用的两种参数化方式分别为
- CSV Data Set Config(通过CSV外部文件参数化)
- User Parameters(用户自定义参数)
- 如何管理环境变量/用户账号密码信息
Jmeter提供用户自定义变量User Defined Variables,用于同一管理可变的变量,当变量发生变化时,可在User Defined Variables内直接修改对应的变量值即可,脚本内引用变量的方式为${变量名}
- 如何解决单线程登录问题?
使用逻辑控制器,jmeter提供单次逻辑控制器,控制登录线程仅运行一次
- 如何解决多线程登录问题?
使用全局变量保存登录信息,Jmeter提供设置全局变量的函数_setproperty()可将登录的cookie设置为全局变量,便于不同线程调用
jmeter性能相关:
1.持续压测指定时间
Jmeter的线程组(threader group)提供Duration(seconds)字段,用于设置压测的持续时间
2.同步定时器
同步定时器可以设置请求累计多少个后,释放请求集合;不足数量的通过设置超时时间,到达时间后同步释放剩余的请求。
测试开发-Django
1.django的框架模块?
MTV:model模型、template模板、view视图;传统的框架模型是MVC-model模型、view视图、controler用户控制器
2.django视图函数如何返回数据给前端?
django必备三种基础方法:
1.1.通过Httpresponse返回字符串给前端
1.2通过render返回html页面以及即将渲染到页面的数据给前端
1.3通过redirect返回重定向地址给前端
3.django如何将数据渲染到html页面上?
通过模板技术,将数据成功渲染到html页面上。主要用到的模板技术有:
1.var变量:
实际场景引用:登录成功后,在页面上显示用户名
视图函数内返回:{‘html_var’:view_value}
在html内引用视图函数返回的值,引用格式:{{html_var}}
2.for 循环控制器:
返回的是个列表类型的数据时,需要通过for循环遍历读取;
实际场景引用:web端的列表数据展示,接口返回的数据是:[{version:v1,name:v2},{version:v11,name:v22},{version:v111,name:v222}]---代表返回三条数据,每个数据里面有两个参数
视图函数内返回:{'html_datalist':value_datalist}
在html内循环读取视图函数返回的数据列表,引用格式:
{% for data in html_datalist%}
<li>{{data.k}} --{{data.name}}- </li> <!--循环读取数据,以段落li标签的形式展示数据每一条数据-->
{% endfor%}


















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











