




入门Hadoop存储与计算:实现单词统计的分布式文件处理系统
引言
在当今数字化时代,数据量呈爆炸式增长,传统的数据处理和存储技术已经难以应对这种规模的数据
企业和研究机构迫切需要一种高效、可扩展且可靠的解决方案来管理和分析这些海量数据
Hadoop,作为一种分布式计算框架,凭借其强大的存储和处理能力,成为了大数据领域的明星技术
本文将分析官方文档探讨Hadoop的存储、计算原理,设计并实现一个分布式文件处理系统,该系统能够处理大规模数据文件(统计单词数量),并将处理结果存储回HDFS
HDFS存储
HDFS全称Hadoop Distributed File System(Hadoop分布式文件系统),用于实现大数据场景下的分布式存储
它的设计目标是多节点在廉价的硬件上运行并提供高吞吐量的数据访问,并且提供副本进行数据冗余,实现数据的可靠与可用
架构
HDFS架构通常有DataNode、NameNode常用组件组成:
- DataNode分布在集群中各个节点上,负责实际的存储、检索数据,存储数据时使用数据块(Block)
- NameNode负责文件系统元数据管理,客户端通过它进行交互,它对数据节点进行管理
HDFS架构如下图:
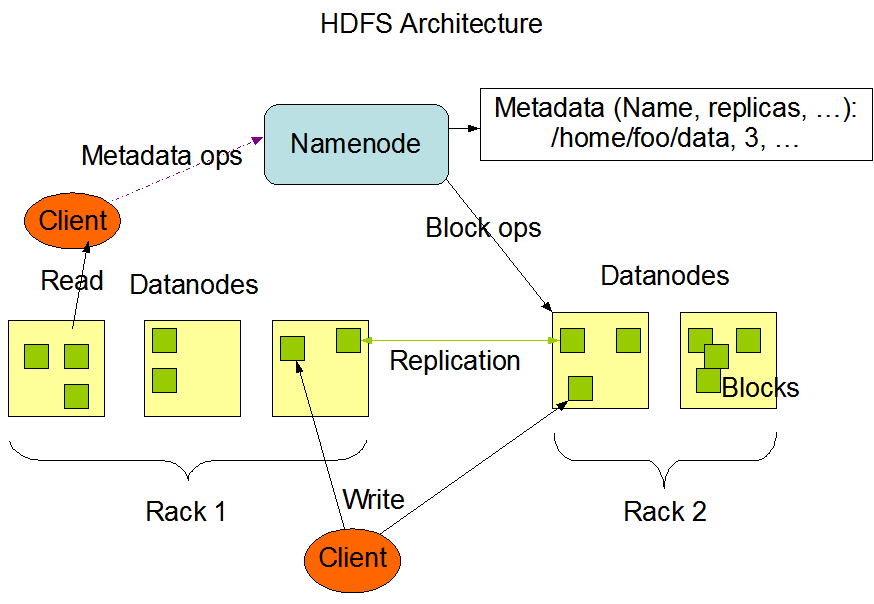
大型HDFS实例在通常分布在许多机架上的计算机群集上运行,DataNode数据节点被分布在不同的机架(Rack)上
不同机架中的两个节点之间的通信必须通过交换机进行,不同机架间节点同步数据带宽通常会大于同机架间数据同步
也就是说不同机架间节点进行数据同步的开销会更大
复制
为了实现可靠与可用,采用数据块副本来实现数据冗余,在写入的同时进行复制副本到其他节点
一种简单的设计方式是将副本平均到不同机架的节点上(比如设置3个副本,就同步到3个不同机架的节点上)
这样可以防止在整个机架出现故障时丢失数据,并允许在读取数据时使用多个机架的带宽,但会增加写入成本,写入需要将块传输到多个机架
HDFS的最佳实现并不是采用这种方式,以三个副本为例:
- 如果(客户端)在数据节点上则放本地,否则写到同机架随机数据节点上
- 不同(远程)机架上的一个节点
- 不同(远程)机架与第二个副本不同的节点
相当于一个副本放在客户端近的机架中,第二、三个副本放在其他机架不同节点上
以官方文档给出的图片为例,id为1、3的块设置2个副本,id为2、4、5的块设置3个副本
2个副本的情况机架均分,而3副本情况远程机架节点副本多占一个(可以把左边四个节点和右边四个节点看出两个机架)
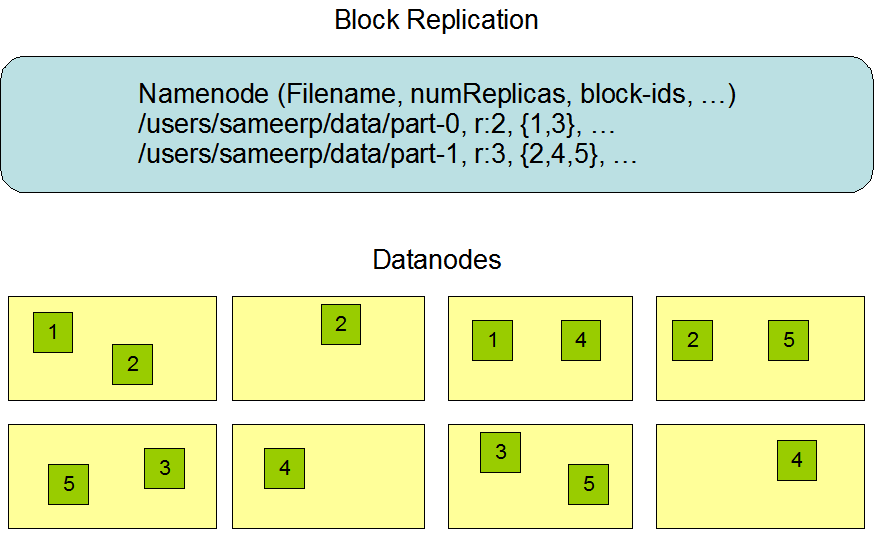
这样的策略,不会将副本平均分配到不同机架上,减少写入的开销,并且不影响数据可靠,同时也可以通过多机架带宽读,但是分布不均匀(三分之二副本在一个机架、三分之一副本在另一个机架)
原文如下:
when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode in the same rack as that of the writer, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack.
MapReduce计算
Hadoop中的计算模型采用MapReduce,MapReduce的核心思想类似分治,将一个大的计算任务分解成多个小的任务,这些小任务可以并行处理,最后将结果汇总
MapReduce模型分为Map、Reduce两个阶段,其中Reduce又分为shuffle, sort and reduce
运行流程
文件上传到HDFS -> 输入 input <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> output 输出 -> 存储到HDFS
- 文件上传到HDFS
- 输入分片:将输入数据分割成多个分片,每个分片会被分配给一个Map任务
- Map任务:每个Map任务读取一个分片的数据,调用Map函数处理数据,生成中间键值对
- Shuffle:将Map任务生成的中间键值对按照键进行分区,发送到相应的Reduce任务
- Sort:在Reduce任务接收到中间键值对后,按照键进行排序
- Reduce任务:接收到一组具有相同键的中间键值对,调用Reduce函数进行聚合处理,生成最终的输出键值对
- 输出:Reduce任务将最终的输出键值对写入到输出文件中存储到HDFS
实战
实战阶段在搭建环境后,通过官网统计单词的案例来进行演示
环境搭建
具体流程包括可能踩坑的地方可以查看从零搭建Hadoop的文章
这里简略进行说明:
- 创建Hadoop用户
#添加用户
sudo useradd hadoop
#设置密码
sudo passwd hadoop
#切换用户
su hadoop
- 配置SSH
#安装
yum install openssh
#需要密码校验
ssh localhost
#登陆成功后退出 开始配置免密登陆
exit
cd ~/.ssh
#生成密钥 回车几下
ssh-keygen -t rsa
#添加
cat ./id_rsa.pub >> ./authorized_keys
#确保有权限
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
#再次登陆不需要密码
ssh localhost
- JDK安装配置
#更新包索引
sudo yum update -y
#安装JDK
sudo yum install java-1.8.0-openjdk-devel -y
#找到JDK目录 JDK通常在/usr/lib下
#/usr/lib/jvm
pwd
#目录名太长改成jdk8
mv java-1.8.0-openjdk-1.8.0.432.b06-2.oc8.x86_64/ jdk8
#配置环境变量 在末尾追加环境变量
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jdk8
export PATH=$JAVA_HOME/bin:$PATH
#环境变量生效
source ~/.bashrc
#查看版本号 判断是否安装成功
java -version
- 下载Hadoop解压
#解压
sudo tar -zxf hadoop-3.4.1.tar.gz
#进入目录
cd hadoop-3.4.1
#查看版本 如果没找到JDK说明 JDK环境变量配的有问题
./bin/hadoop version
- 配置Hadoop环境变量
#末尾追加 我的Hadoop目录是:/home/lighthouse/hadoop-3.4.1
vim ~/.bashrc
export HADOOP_HOME=/home/lighthouse/hadoop-3.4.1
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
#这里也有JAVA的环境变量
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
- 配置数据文件和hdfs地址
vim core-site.xml
<configuration>
<!-- 临时文件 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/lighthouse/hadoop-data/tmp</value>
<description>Abase for other temporary directories. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









