




线程概念与控制
线程概念与控制
1. 线程概念
1.1 书本上的定义
- 进程 (Process):之前学习的进程,可以被看作是内核数据结构(如PCB)**与**其独占的代码和数据的集合。它是一个独立的“执行流”,是操作系统进行管理和调度的基本单位。
- 线程 (Thread):操作系统的教科书中通常将线程定义为“进程内部的一个执行分支”或“一个更轻量级的执行流”。
1.2 从资源与调度的角度重新定义
下面将采用以下两个新的定义,它们并不否定旧的定义,而是从不同角度提供了更精确的描述:
- 进程 (Process):是操作系统中承担分配系统资源的基本实体。
- 线程 (Thread):是被CPU调度的基本单位。
-
当用户创建一个进程时,首先想到的是操作系统需要为其分配一系列昂贵的资源:创建PCB、独立的虚拟地址空间、页表、文件描述符表、信号处理表等。进程首先是一个资源的容器,它的存在本身就意味着对系统资源的消耗。
-
而线程,则是这个资源容器中,真正被CPU拿去执行代码的那个“执行者”。CPU的核心工作,就是不断地在不同的线程之间切换并执行它们的指令。
1.3 Linux 中的线程
要真正理解线程,最好的方式是研究一个具体的操作系统实现。由于不同操作系统对线程的实现方案差异巨大,而 Linux 的选择尤为独特和高效,下文以 Linux 中线程的设计进行介绍。
1.3.1 进程的“资源窗口”:虚拟地址空间
一个进程所拥有的绝大部分资源(代码、数据、堆、栈、共享库,乃至通过系统调用访问的内核资源),都是通过它的虚拟地址空间这个“窗口”来看到的。地址空间决定了进程的视野。
- 创建新进程:意味着创建一个全新的、独立的“资源窗口”(即独立的虚拟地址空间和页表),这导致了高昂的创建开销。
- 进程的独立性:正是因为每个进程都有自己独立的“窗口”和映射到不同物理内存的页表,才保证了进程之间的安全隔离。
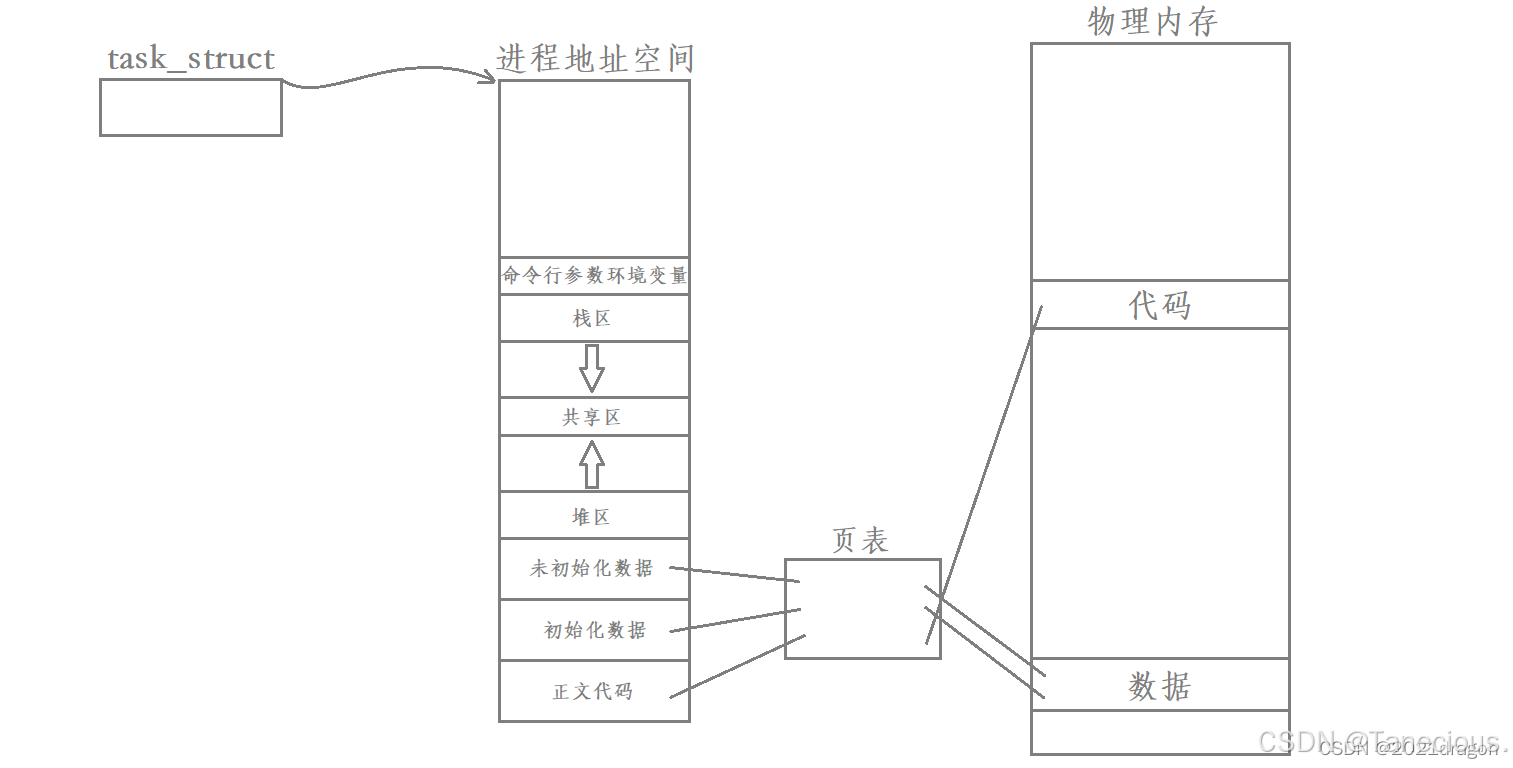
1.3.2 Linux的创举:共享“资源窗口”
现在,设想一种新的执行流创建方式:
创建一个新的执行实体,它也拥有自己的内核数据结构(PCB/
task_struct),可以被独立调度。但不再为它创建一个新的、独立的虚拟地址空间,而是让它与创建它的那个进程共享同一个虚拟地址空间。
- 由于这些新的执行流共享着同一个“资源窗口”,它们自然就能看到并访问同一份代码、同一份全局数据、同一个堆空间、同一组文件描述符。
- 这个仅仅拥有独立PCB(
task_struct),但共享着大部分资源的执行流,就是 Linux 对线程的实现。
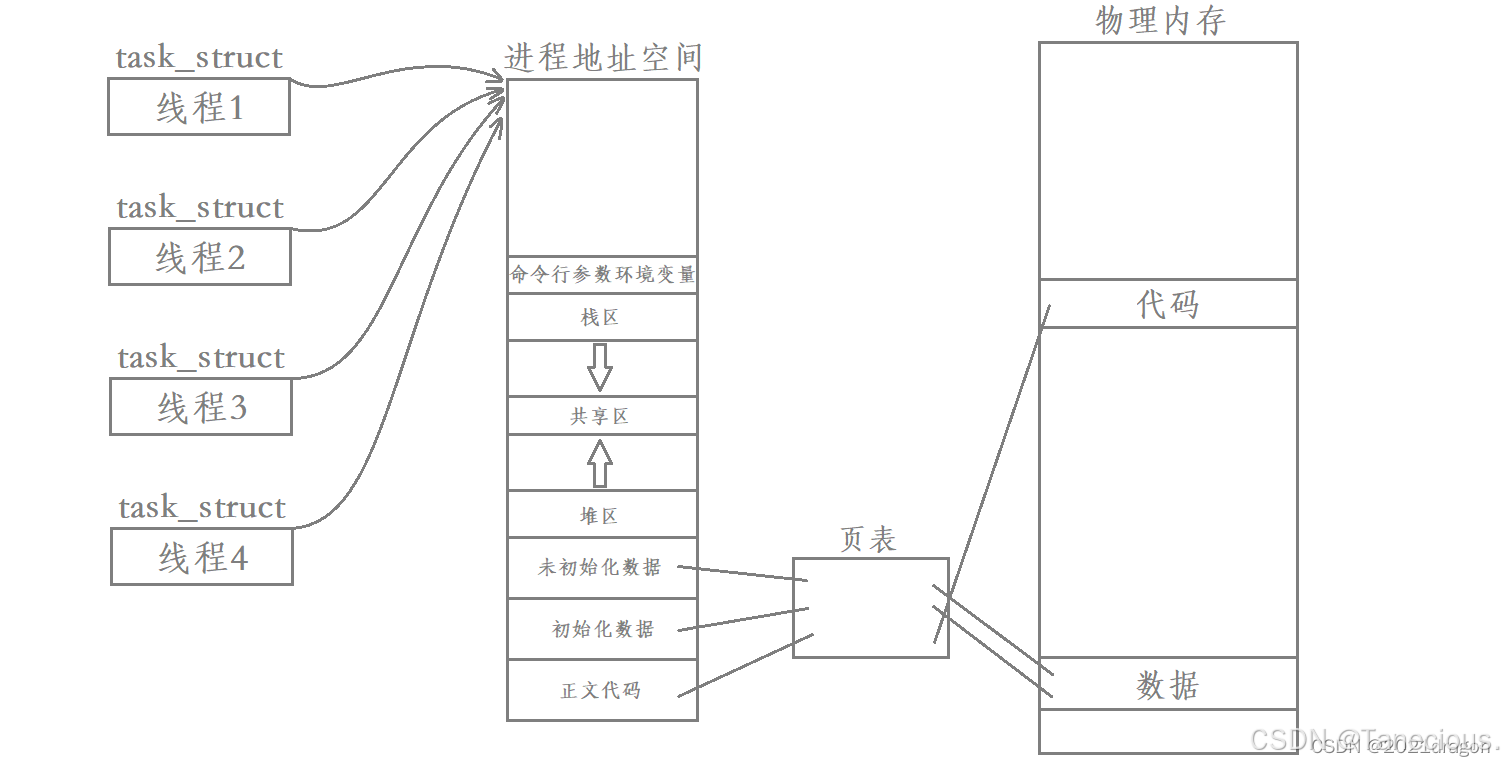
上面这种只创建 task_struct ,并要求创建出来的 task_struct 和父 task_struct 共享进程地址空间和页表的创建结果所产生的就是四个线程。
所以在 Linux 内核的视角中,不存在一个与“进程”截然不同的、“线程”的数据结构。Linux 通过复用进程的PCB(task_struct),并让多个 task_struct 共享同一个 mm_struct (虚拟地址空间)的方式,巧妙地模拟出了线程。
1.3.3 Windows/传统OS模型 vs. Linux模型
- 传统模型 (如Windows):
- 内核中存在两种截然不同的数据结构:进程控制块(PCB)和线程控制块(TCB)。
- PCB负责管理资源(如地址空间),TCB负责代表执行流。一个PCB下可以关联多个TCB。
- 这种设计在概念上很清晰,但增加了内核的复杂性,需要为线程设计独立的管理和调度逻辑。
- Linux模型:
- 内核中只有一种核心的执行流数据结构:
task_struct(PCB)。 - 当创建一个
task_struct时,可以选择是创建一个新的地址空间(传统意义上的进程),还是共享一个已有的地址空间(线程)。 - 这种设计的最大优势在于代码复用。内核无需为线程编写一套全新的管理和调度代码,而是完全复用了经过千锤百炼的进程管理机制。这使得Linux的线程实现更为健壮、高效且易于维护。
- 内核中只有一种核心的执行流数据结构:
1.3.4 几个有关线程的补充问题
1.3.4.1 该如何重新理解之前的进程?
结合现在的认知下面用蓝色方框框起来的内容,将这个整体叫做进程。

因此,所谓的进程并不是通过 task_struct 来衡量的,除了 task_struct 之外,一个进程还要有进程地址空间、文件、信号等等,合起来称之为一个进程。
现在应该站在内核角度来理解进程:承担分配系统资源的基本实体,叫做进程。
换言之,当用户创建进程时是创建一个 task_struct 、创建地址空间、维护页表,然后在物理内存当中开辟空间、构建映射,打开进程默认打开的相关文件、注册信号对应的处理方案等等。
而之前接触到的进程都只有一个 task_struct ,也就是该进程内部只有一个执行流,即单执行流进程,反之,内部有多个执行流的进程叫做多执行流进程。
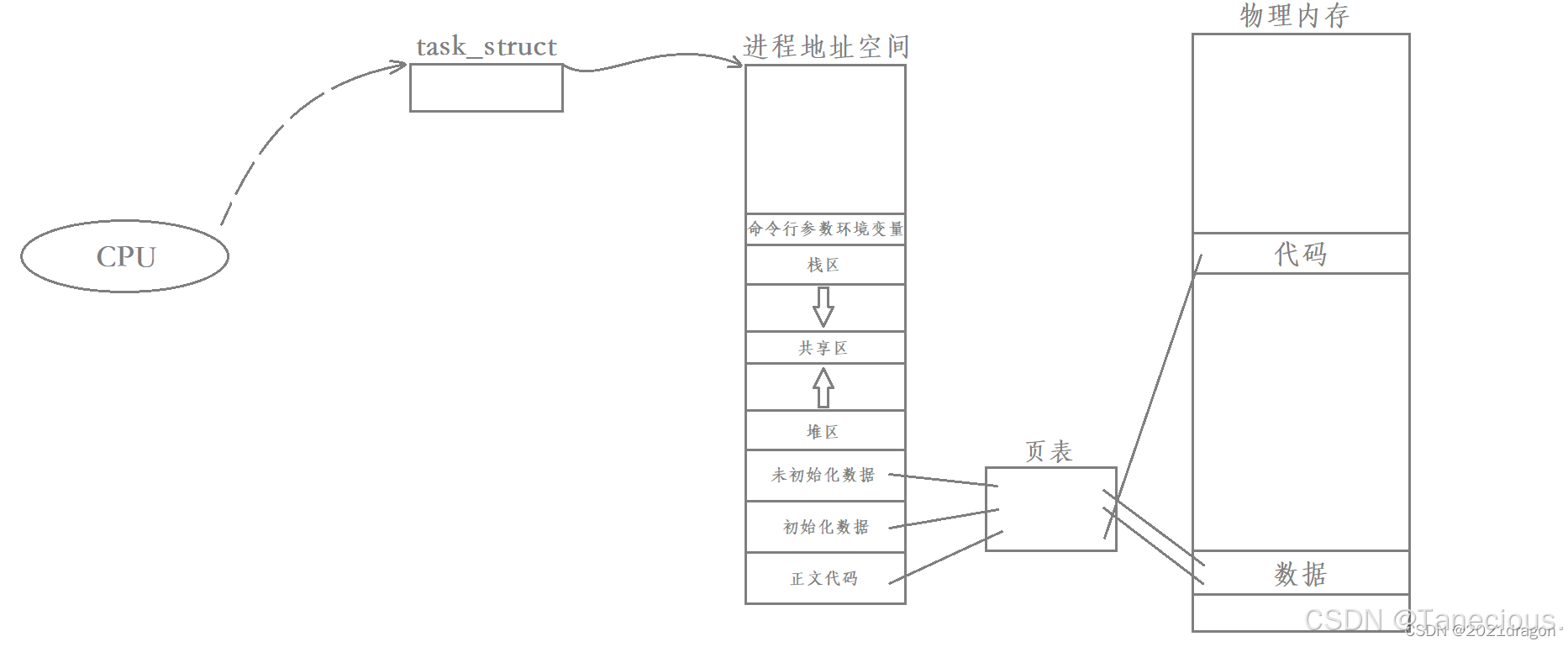
1.3.4.2 站在CPU的角度,能否识别当前调度的 task_struct 是进程还是线程?
答案是不能,也不需要了,因为CPU只关心一个一个的独立执行流。无论进程内部只有一个执行流还是有多个执行流,CPU都是以task_struct为单位进行调度的。
单执行流进程被调度:
多执行流进程被调度:
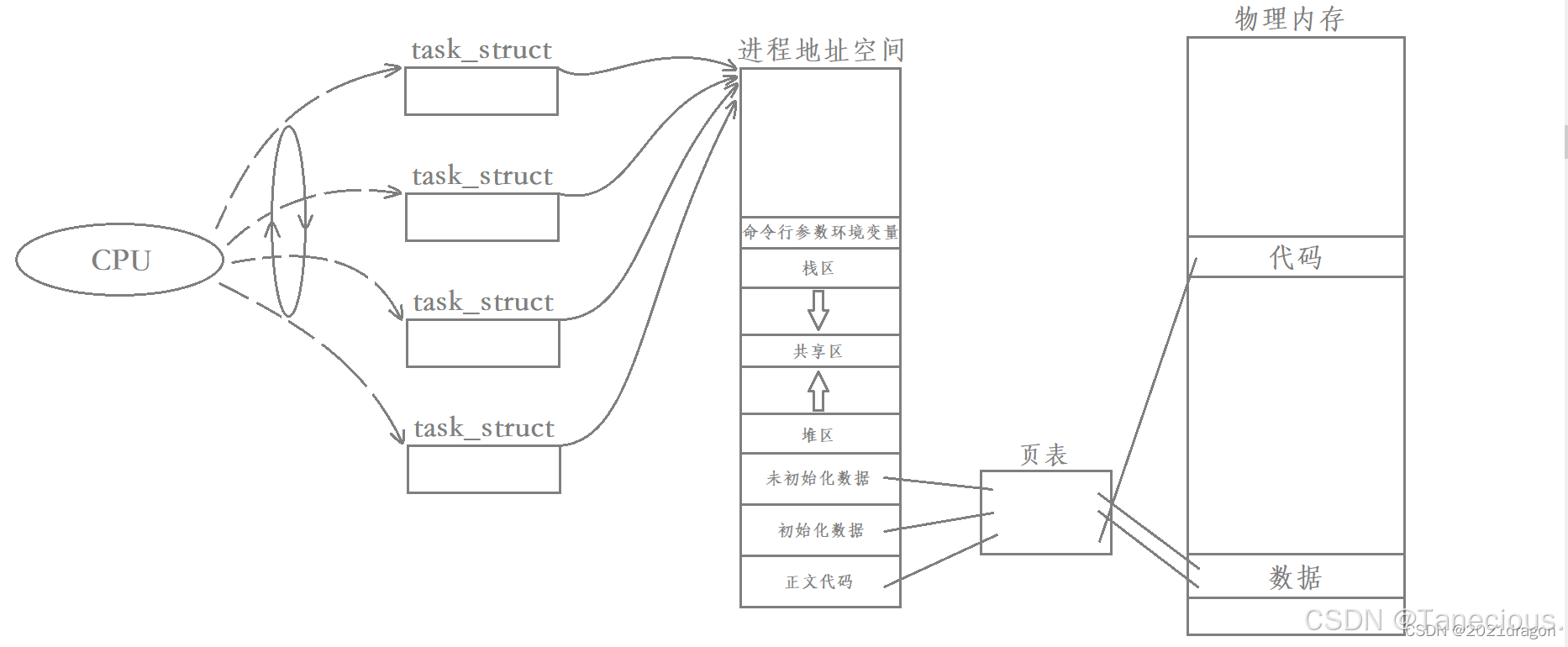
因此,CPU看到的虽说还是task_struct,但已经比传统的进程要更轻量化了。
并且 Linux 中用 task_struct 来同时表示传统进程和线程,同时内核在调度时,它调度的到底是进程还是线程并不是内核需要关心的。
- 内核调度器的视角:调度器不关心一个
task_struct背后是独立的进程还是共享资源的线程。它眼中只有一系列平等的、可被调度的执行流。 - CPU硬件的视角:CPU更加“无知”,它只是从内核那里接收一个
task_struct的上下文(寄存器信息、指令指针等),然后开始执行。
这个在 Linux 内核中被统一调度的执行实体—— task_struct,有一个更精确的名字,叫做轻量级进程(Light-Weight Process, LWP)。
1.3.4.3 有关线程的系统调用
在Linux没有真正意义的线程,那么也就绝对没有真正意义上的线程相关的系统调用
这很好理解,既然在 Linux 中都没有真正意义上的线程了,那么自然也没有真正意义上的线程相关的系统调用了。但是 Linux 可以提供创建轻量级进程的接口,也就是创建进程,共享空间,其中最典型的代表就是 vfork 函数。
vfork 函数的功能就是创建子进程,但是父子共享空间,函数 vfork 的函数原型如下:
pid_t vfork(void);
vfork 函数的返回值与 fork 函数的返回值相同:
-
给父进程返回子进程的PID。
-
给子进程返回0。
只不过 vfork 函数创建出来的子进程与其父进程共享地址空间,例如在下面的代码中,父进程使用 vfork 函数创建子进程,子进程将全局变量 g_val 由100改为了200,父进程休眠3秒后再读取到全局变量 g_val 的值。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
int g_val = 100;
int main()
{
pid_t id = vfork();
// child
if (id == 0)
{
g_val = 200;
printf("child:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);
exit(0);
}
// father
sleep(3);
printf("father:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);
return 0;
}
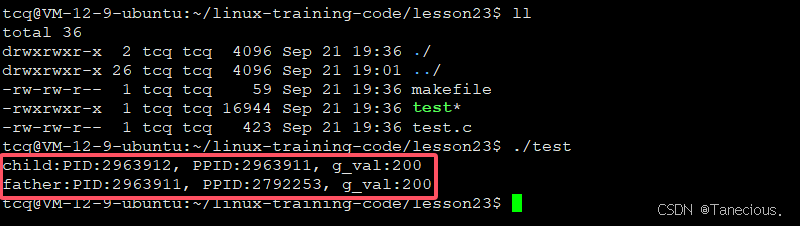
可以看到,父进程读取到 g_val 的值是子进程修改后的值,也就证明了 vfork 创建的子进程与其父进程是共享地址空间的。
1.3.5 一个现实世界的比喻:进程与线程的“家庭模型”
为了将前面讨论的“资源分配实体”和“CPU调度单位”这两个核心概念具体化,让我们来看一个现实世界中的类比。
1.3.5.1 进程:社会资源分配的基本实体——“家庭”
在我们的社会中,什么是分配社会资源的基本单位?这里的社会资源包括房子、汽车、教育、医疗等。答案是家庭。
通常,社会会将一套房子、配套的社区服务等核心资源分配给一个家庭。一个家庭一旦建立,就拥有了这些资源,并以此为基础承担相应的社会责任。
这与进程的概念完美对应。当一个程序运行时,操作系统会为其创建一个进程。这个过程就如同组建一个新“家庭”。操作系统会为这个进程“家庭”分配其所需的一切核心资源:独立的虚拟地址空间(房子)、文件描述符表(家里的各种钥匙)、代码和数据段(家具和电器)等等。因此,进程就像一个家庭,是系统分配资源的基本实体。
1.3.5.2 线程:家庭中的独立行为单位——“家庭成员”
一个家庭由多个家庭成员组成,比如父母、子女、祖父母。每个成员都是一个独立的个体,在同一时间做着不同的事情:
- 孩子在房间里学习。
- 父母在外工作赚钱。
- 祖父母在公园锻炼身体。
尽管每个成员执行的任务不同,但他们的所有活动,都共享着家庭的公共资源(客厅、厨房、电视机),并为了一个共同的目标——让家庭生活更美好——而努力。
这正是线程的写照。家庭成员就像进程中的线程。它们是真正“干活”的单位,是独立的行为个体。在一个进程“家庭”中,可以有多个线程“成员”:
- 一个线程负责网络通信。
- 一个线程负责数据计算。
- 一个线程负责用户界面响应。
它们是真正被CPU轮流调度执行的单位,就像社会上的不同岗位安排给了不同的家庭成员。
1.3.5.3 资源的共享与独占
这个比喻也完美地解释了线程间的资源关系:
- 共享资源:就像家庭中的客厅、电视、冰箱是所有成员共享的一样,一个进程的大部分资源也是被其内部所有线程共享的。这包括:
- 进程的地址空间(代码段、数据段、堆)
- 打开的文件描述符
- 信号处理函数等
- 独占资源:每个家庭成员也有自己私有的物品,比如自己的日记本、作业本、银行存折。同样,每个线程也必须拥有自己的一套独占资源,以保证其独立运行。这主要包括:
- 线程的栈(Stack):用于存储自己的局部变量、函数调用信息。每个线程的函数调用轨迹是独立的,因此栈必须是私有的。
- 线程的寄存器:保存了线程当前的运算数据和执行状态。
- 线程的
errno、线程ID等。
1.3.5.4 回归单进程模型
那么,之前学习的“进程”是什么呢?
它就像一个单人家庭(例如,独居的年轻人)。这个家庭虽然只有一个成员,但它依然是一个完整的家庭,独立拥有社会分配给它的所有资源(房子等)。在这个家庭里,唯一的那个成员既是家庭的全部,也是唯一的行为单位。
这与单线程进程完全一致。它是一个完整的资源分配实体,但内部恰好只有一个执行流(线程)。我们之前所学的进程,实际上是多线程进程的一种特殊情况。
2. 分页式存储管理
2.1 物理内存管理
上文得出一个核心结论:理解线程的关键在于理解资源的划分与共享。而进程/线程所拥有的大部分资源,最终都对应到物理内存。物理内存是所有代码和数据的最终载体。
要理解高层的虚拟地址空间是如何被划分的,必须先反向追溯,看看操作系统是如何管理最底层的物理内存的。
2.1.1 页框:物理内存的基本单位
一个现代操作系统通常管理着数GB乃至更多的物理内存。如果以字节(Byte)为单位进行管理,那么管理成本(用于记录每个字节状态的数据结构)将是天文数字。
因此,操作系统借鉴了磁盘文件系统的管理思想,将整块连续的物理内存,逻辑上划分为一个个大小固定的单元进行管理。这个单元就是页框(Page Frame)。
- 大小:在32/64位的Linux系统中,一个页框的大小通常是 4KB。
- 与磁盘的协同:这个4KB的大小并非偶然。它与文件系统中的**数据块(Data Block)**大小保持一致。这种设计使得内存与磁盘之间的I/O操作(例如,加载程序、读写文件)变得极为高效,因为它们使用了相同的基本数据交换单位。
- OS的抽象:需要强调的是,RAM芯片本身并没有4KB的物理分隔。这种划分完全是操作系统在软件层面为了便于管理而进行的一种逻辑抽象。
2.1.2 管理页框的方案:“先描述,再组织”
假设一个可用的物理内存有 4GB 的空间。按照一个页框的大小 4KB 进行划分,4GB
的空间就是 4GB / 4KB = 1048576 个页框。有这么多的物理页,操作系统必须精确地追踪每一个页框的状态:
- 哪些是空闲的?哪些已被占用?
- 哪些页框属于内核?哪些属于用户进程?
- 哪些页框被锁定在内存中,不能被换出到磁盘?
- 哪些页框是多个进程共享的?
为了应对这个复杂的管理任务,Linux内核采用了经典的管理思想:“先描述,再组织”。
-
描述 (Describe):
内核定义了一个名为struct page的核心数据结构。每一个物理页框,在内核中都有一个对应的struct page实例来描述它。这个结构体虽然本身很小,但包含了管理一个页框所需的所有关键信息:/* include/linux/mm_types.h */ struct page { /* 原子标志,有些情况下会异步更新 */ unsigned long flags; union { struct { /* 换出页列表,例如由zone->lru_lock保护的active_list */ struct list_head lru; /* 如果最低位为0,则指向inode * address_space,或为NULL * 如果页映射为匿名内存,最低为置位 * 而且还指针指向anon_vma对象 */ struct address_space* mapping; /* 在映射内的偏移量 */ pgoff_t index; unsigned long private; }; struct { /* slab, slob and slub */ union { struct list_head slab_list; /* uses lru */ struct { /* Partial pages */ struct page* next; #if defined(CONFIG_64BIT) int pages; /* Nr of pages left */ int pobjects; /* Approximate count */ #else short int pages; short int pobjects; #endif }; }; struct kmem_cache* slab_cache; /* not slob */ /* Double-word boundary */ void* freelist; /* first free object */ union { void* s_mem; /* slab: first object */ unsigned long counters; /* SLUB */ struct { /* SLUB */ unsigned inuse : 16; /* 用于SLUB分配器: 对象的数量 */ unsigned objects : 15; unsigned frozen : 1; }; }; ... }; }; union { /* 内存管理子系统中映射的页表项计数,用于表示页是否已经映射,还用于限制逆向映射搜索 */ atomic_t _mapcount; unsigned int page_type; unsigned int active; /* SLAB */ int units; /* SLOB */ }; ... #if defined(WANT_PAGE_VIRTUAL) /* 内核虚拟地址 (如果没有映射则为NULL,即高端内存) */ void* virtual; #endif /* WANT_PAGE_VIRTUAL */ ... };其中有几个比较重要的参数:
-
flags:一组标志位,用来存放页的状态。这些状态包括页是不是脏的,是不是被锁定在内存中等。flag 的每一位单独表示一种状态,所以它至少可以同时表示出 32 种不同的状态。这些标志定义在<linux/page-flags.h>中。其中一些位特性非常重要,如
PG_locked用于指定页是否锁定,PG_uptodate用于表示页的数据已经从块设备读取并且没有出现错误。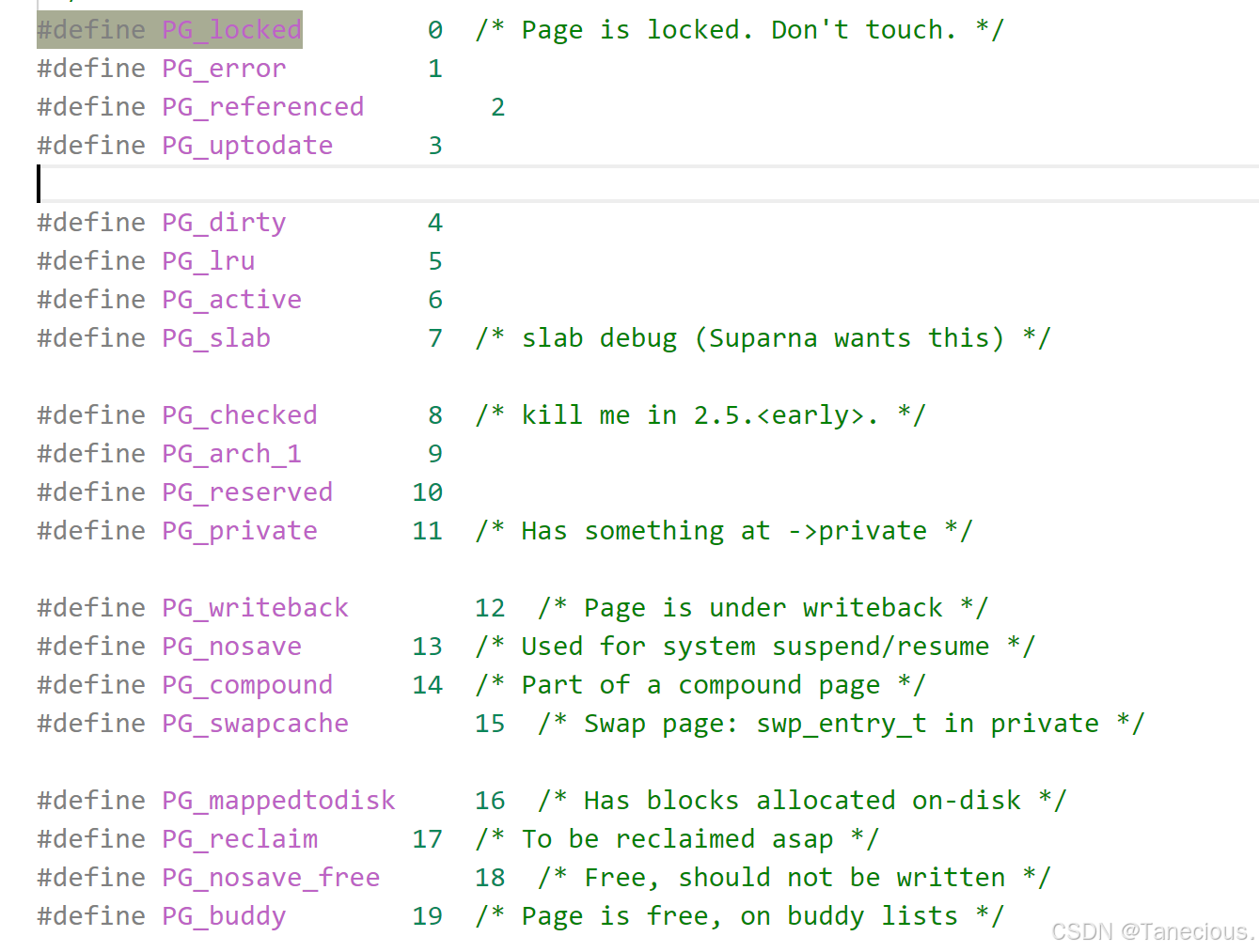
-
_mapcount:一个映射计数器,记录有多少个页表项指向了这个物理页框。当计数值为0时,表明该页框可以被回收。当计数值变为 -1 时,就说明当前内核并没有引用这一页,于是在新的分配中就可以使用它。 -
lru:用于将页框链接到不同的LRU(最近最少使用)链表中,这是内存回收算法的基础。 -
mapping:一个指针,如果该页框缓存的是文件数据,它会指向该文件对应的address_space结构。 -
virtual:是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址。有些内存(即所谓的高端内存)并不永久地映射到内核地址空间上。在这种情况下,这个域的值为 NULL,需要的时候,必须动态地映射这些页。
-
-
组织 (Organize):
内核在启动时,会为整个系统的所有物理页框,创建一个巨大的struct page数组,通常被称为mem_map。struct page mem_map[TOTAL_PAGE_FRAMES];- 这个数组就是整个物理内存的“名册”。数组的第
n个元素,就代表了物理内存中第n个页框。 - 从此,对物理内存的管理,就被巧妙地转化为了对这个
mem_map数组的操作。
- 这个数组就是整个物理内存的“名册”。数组的第
2.1.3 页框的物理地址
根据上面的元阿莫可以发现,struct page 中并没有一个字段来存储它所代表的那个页框的物理地址。这是因为它根本不需要!
由于 mem_map 数组与连续的物理内存是一一对应的,内核可以通过一个简单的数学公式,从一个 struct page 在数组中的下标(index)结合 mem_map 的起始地址(MEM_START_ADDR),直接计算出对应页框的起始物理地址:
physical_address = MEM_START_ADDR + (index * 4KB)
反之,给定一个物理地址,也能迅速计算出它属于哪个页框,并定位到 mem_map 数组中对应的 struct page 描述符。
2.1.4 物理内存管理的影响
理解了物理内存以4KB页框为单位进行管理的底层事实后,之前学习的很多“规则”就有了答案:
- 内存分配:操作系统所有对物理内存的分配,其最小单位都是一个页框(4KB)。即使你只
malloc(1)一个字节,在物理层面,操作系统也必须为用户保留至少一个4KB的页框。 - 共享内存:
shmget()创建共享内存时,其大小必须是4KB的整数倍,因为共享内存的本质就是分配一个或多个连续的物理页框,并将其映射到不同进程的虚拟地址空间。 - 写时拷贝 (Copy-on-Write):当子进程试图修改一个与父进程共享的页面时,内核并非只为那个被修改的变量复制一份,而是将整个4KB的页框复制一份,再进行修改。
- 程序加载:当执行一个程序时,内核会为其分配空闲的页框,然后以4KB为单位,将磁盘上程序文件的内容(ELF格式中的各个段)读入到这些页框中。
2.2 虚拟地址空间与页表
结束对物理内存管理的探讨,接下来,继续向上层探索,看看操作系统是如何在这些被管理起来的物理页框之上,为每个进程构建起一个独立、私有的虚拟地址空间的。
2.2.1 问题引入
在以前学习页表的时候,对页表的认识都是为每个进程创建一对一的映射表,表的左边是虚拟地址,右边是物理地址。
但是实际情况并不是如此简单,以32位系统为例,虚拟内存的最大空间都是是 4GB,由上面的物理内存管理可知操作系统对于内存是以 4KB 为一页进行划分。那么就可以算出一共需要 4GB / 4KB = 1048576 个表项。如下图所示:
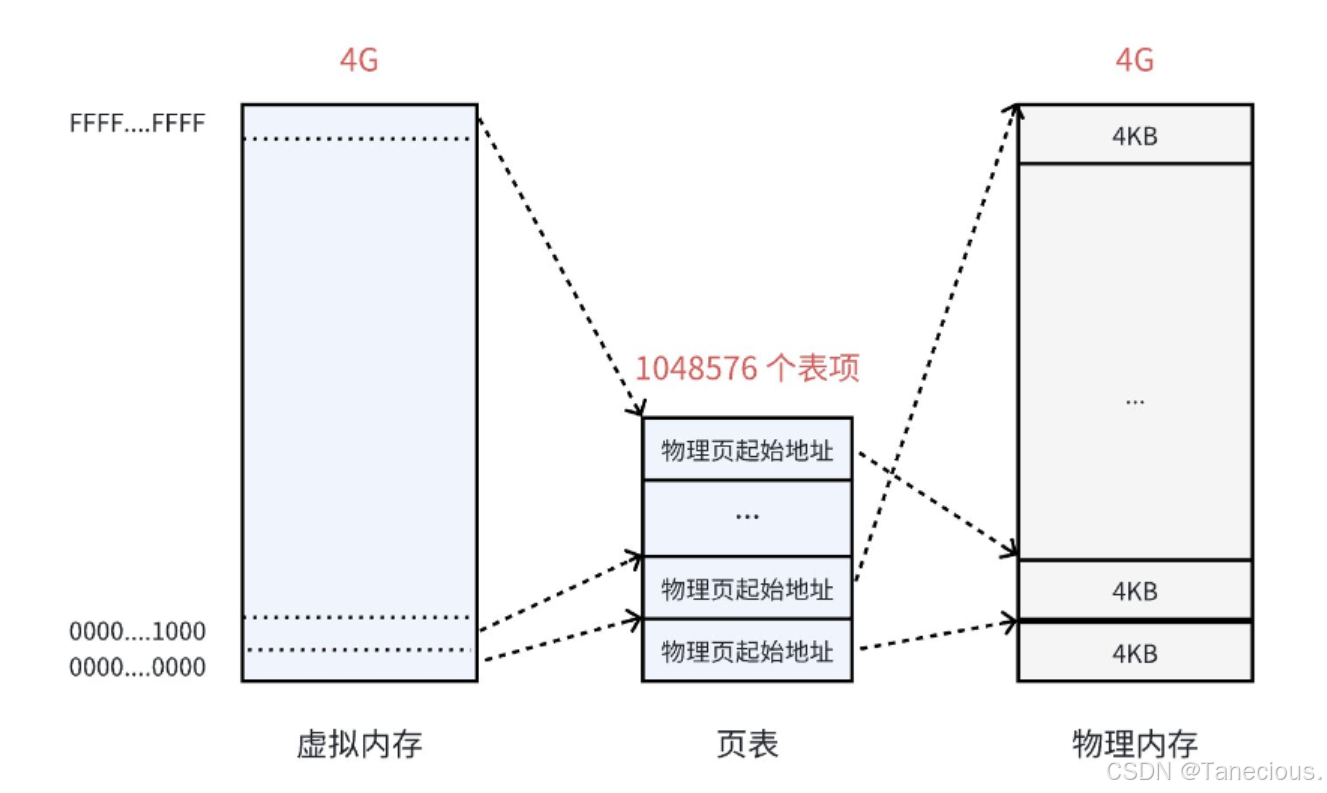
如果为 4KB 的虚拟地址的每一个字节都创建一个映射条目,那么一个进程就需要
2
32
2^{32}
232 (约40亿) 个映射条目。每个条目包含一个虚拟地址(4字节)和一个物理地址(4字节),共8字节。那么,仅仅是存储这张页表本身,就需要 4GB * 8 = 32GB 的内存空间!
这显然是荒谬的。操作系统本身、连同所有进程的数据和代码,都需要在这有限的物理内存中运行。一个进程的页表绝不可能比整个系统的物理内存还要大几十倍。
核心结论一:页表绝不可能是覆盖整个地址空间的一张单一、平坦的巨大表格。它必须采用一种更节省空间、更具结构化的设计。
2.2.2 多级页表
2.2.2.1 多级页表的设计
为了解决单一页表的空间爆炸问题,现代操作系统和CPU硬件共同采用了一种多级页表(Multi-level Page Table)的结构。在32位Linux系统中,这通常是一个二级页表模型。
其核心思想是:不再为每个字节建立映射,而是将虚拟地址进行逻辑上的切分,并利用切分后的部分作为不同级别页表的索引。
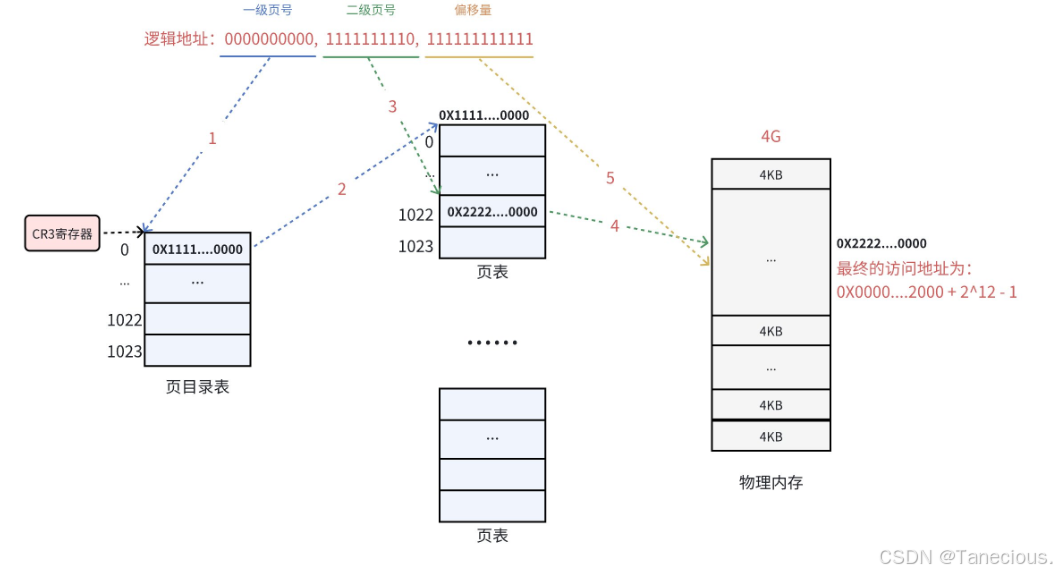
一个32位的虚拟地址,虽然在数值上是连续的,但在地址翻译时,硬件(MMU)会将其看作三个部分:
| 10 bits | 10 bits | 12 bits |
|---|---|---|
| 页目录索引 | 页表索引 | 页内偏移 |
| (Directory Index) | (Table Index) | (Offset in Page) |
2.2.2.2 虚拟到物理的翻译流程
这个翻译过程由CPU内部一个专门的硬件单元**内存管理单元(MMU, Memory Management Unit)**自动完成。为了更好地理解这个过程,我们先看一个具体的例子,然后再引入其性能优化机制。
2.2.2.2.1 具体示例
假设有一个32位的逻辑地址,其三段式结构为:(页目录索引, 页表索引, 页内偏移)。具体地址为:(0000000000, 1111111110, 111111111111)
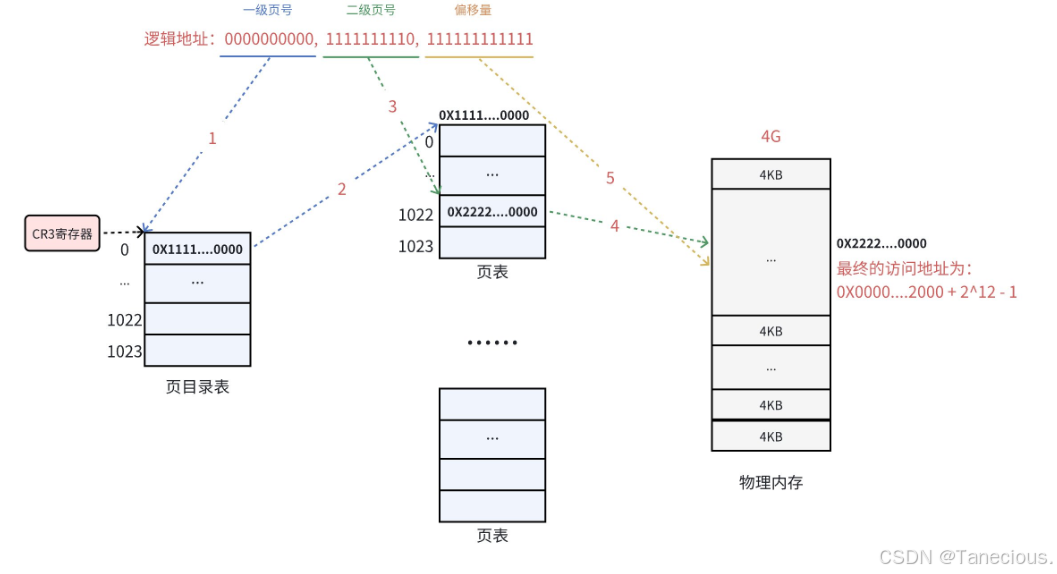
-
第一级查询(页目录):
- MMU从
CR3寄存器中获得当前进程的页目录基地址。 - 它使用地址的第一部分
0000000000(十进制为0) 作为索引,在页目录中查找第0个条目(PDE)。 - 这个条目中包含了下一级页表的物理基地址。
- MMU从
-
第二级查询(页表):
-
MMU使用地址的第二部分
1111111110(十进制为1022) 作为索引,在刚刚找到的页表中查找第1022个条目(PTE)。 -
这个条目中包含了最终目标物理页框的基地址。
-
注:由于物理页框的地址一定是4KB对齐的(即其地址的低12位全为0),因此在PTE中,实际上只需要存储页框地址的高20位即可,剩下的12位可以用于存储权限、状态等标志位。
-
-
最终地址合成:
- MMU将上一步得到的物理页框基地址,与地址的第三部分页内偏移
111111111111(十进制为4095)——相加。 最终物理地址 = 物理页框基地址 + 4095- 这样,就完成了从一个虚拟地址到最终物理地址的转换。
- MMU将上一步得到的物理页框基地址,与地址的第三部分页内偏移
2.2.2.2.2 性能瓶颈:多次内存访
上述的查找过程被称为**“页表遍历”(Page Table Walk)**。可以看到,为了翻译一个地址,MMU需要:
- 访问一次内存来读取页目录项(PDE)。
- 再访问一次内存来读取页表项(PTE)。
- 最后访问一次内存来读取目标数据。
对于二级页表,一次地址翻译变成了三次内存访问。如果是在64位系统下采用四级页表,那么就需要五次内存访问!这种额外的开销会严重拖慢CPU的执行速度,因为内存访问相对于CPU计算来说是极其缓慢的。
多级页表虽然解决了空间问题,却带来了严重的时间效率问题。
性能优化:TLB (转译后备缓冲器)
计算机科学中的一句名言是:“任何问题都可以通过增加一个中间层来解决”。为了解决页表遍历的性能瓶,MMU引入了一个强大的“武器”——TLB(Translation Lookaside Buffer,转译后备缓冲器)。
TLB本质上是一个高速的、容量很小的硬件缓存,它位于MMU内部,专门用于存储近期使用过的“虚拟页号 -> 物理页框号”的映射关系。
有了TLB之后,MMU的地址翻译流程升级为:
- 第一步:查询TLB
当CPU发出一个虚拟地址时,MMU首先将该地址的虚拟页号(高20位)与TLB中缓存的所有条目进行并行、快速的比较。 - 第二步:TLB命中 (Cache Hit)
如果在TLB中找到了匹配的条目,这被称为**“TLB命中”**。MMU会直接从TLB中取出对应的物理页框号,然后与虚拟地址的页内偏移结合,形成最终的物理地址。这个过程完全在MMU内部完成,无需访问内存,速度极快。地址翻译就此完成。 - 第三步:TLB未命中 (Cache Miss)
如果在TLB中没有找到匹配的条目,即**“TLB未命中”,MMU别无选择,只能启动“慢速模式”,即前文所述的页表遍历(Page Table Walk)**,从CR3寄存器开始,一级一级地查询内存中的页表,最终找到物理页框地址。 - 第四步:更新TLB
在通过慢速的页表遍历找到映射关系后,MMU在将物理地址发送给内存总线的同时,会将这个新发现的映射关系(虚拟页号 -> 物理页框号)存入TLB中。这样做的目的是,根据局部性原理,该页面很可能在不久的将来会再次被访问,届时就可以实现快速的TLB命中了。
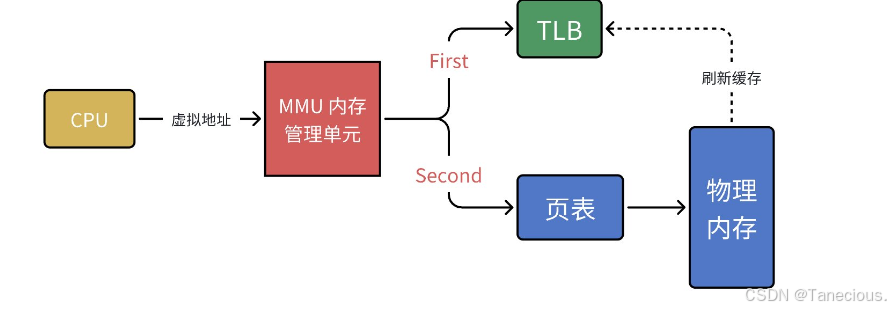
2.2.2.3 多级页表的优势
这种二级结构极大地节省了空间。
- 一个页目录有
2^10 = 1024个条目。 - 一个页表有
2^10 = 1024个条目。 - 假设每个条目占4字节,那么一个页目录或一个页表的大小恰好是
1024 * 4B = 4KB,正好可以装在一个物理页框中。 - 一个进程最多需要1个页目录(4KB)和1024个页表(
1024 * 4KB = 4MB)。总大小约为4MB,远小于之前计算的32GB。
更重要的是,这4MB是理论上限。一个普通进程可能只使用了几百MB的内存,因此它只需要少数几个页表即可。大部分页目录项都是空的,操作系统无需为不存在的映射分配页表,从而实现了按需分配,极大地节省了内存。
2.2.2.4 关键细节剖析
2.2.2.4.1 为何页内偏移是12位?
这个数字并非巧合,它与系统的**页面大小(Page Size)**直接相关。
- Linux系统标准的页面大小是4KB。
2^12 = 4096。- 因此,一个12位的二进制数,其取值范围正好是0到4095,可以精确地寻址到一个4KB页面内的任意一个字节。
这个4KB的“魔法数字”贯穿了整个系统设计,它统一了磁盘I/O(数据块大小)、物理内存管理(页框大小)和虚拟地址划分(页内偏移),使得各层之间可以高效协作。
2.2.2.4.2 局部性原理 (Locality of Reference)
将虚拟地址的高位用于选择页、低位用于页内偏移的设计,也完美地契合了局部性原理。程序在运行时,其内存访问通常具有高度的局部性,即访问了某个地址后,很可能会接着访问其附近的地址。
由于这些“附近”的地址其虚拟地址的高20位大概率是相同的,它们会被映射到同一个物理页框中。这意味着,当CPU因为访问一个变量而将一个页面加载到内存和缓存时,它很可能已经把接下来需要的指令或数据“顺便”一起加载进来了,这极大地提升了程序的执行效率。
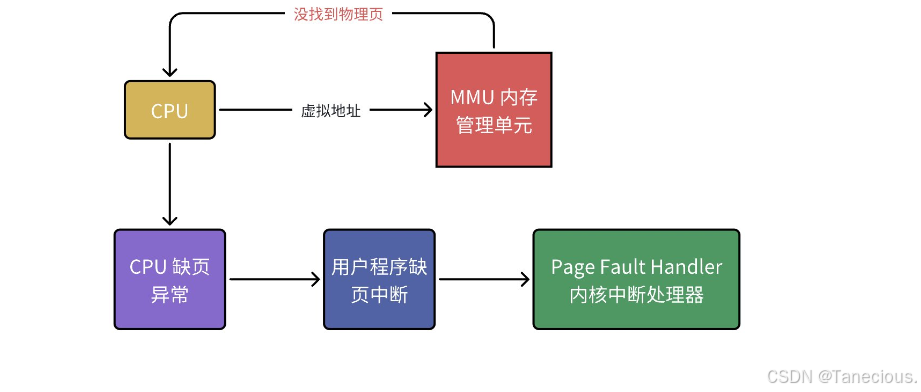
2.2.2.4.3 缺页中断 (Page Fault)
MMU在进行地址翻译的过程中,如果发现页目录项或页表项无效(例如,对应的页面不在物理内存中),它不会继续执行,而是会触发一个硬件异常,即缺页中断。
CPU会暂停当前进程,跳转到操作系统预设好的缺页中断处理程序。这个程序会:
- 判断这次内存访问是否合法(是否在进程的地址空间范围内)。
- 如果不合法,则发送
SIGSEGV信号终止进程。 - 如果合法,说明数据只是暂时不在内存。此时,操作系统会:
- 调用物理内存管理模块,申请一个空闲的物理页框(
struct page)。 - 从磁盘等外部存储中,将需要的数据加载到这个页框中。
- 更新页表,建立新的虚拟地址到物理页框的映射关系。
- 返回,让MMU重新执行刚才失败的地址翻译。
- 调用物理内存管理模块,申请一个空闲的物理页框(
这个过程对用户进程是完全透明的,但它揭示了操作系统是如何将物理内存管理、虚拟地址和磁盘I/O无缝地结合在一起的。
2.2.2.5 重新定义“进程的资源”
通过对页表的学习,可以对“进程的资源”有一个更深刻的理解。
- 进程的地址空间(如
mm_struct)定义了其虚拟地址的合法范围,但它本身不占用大量内存,更像是一份“蓝图”。 - 进程真正拥有的物理资源,体现在其页表中建立的有效映射关系的数量上。
malloc或new申请内存时,操作系统很多时候只是在进程的地址空间“蓝图”上预留了一段虚拟地址范围,并不会立即分配物理内存。只有当程序第一次访问这段地址时,才会触发缺页中断,从而按需地、延迟地分配物理内存并建立页表映射。
核心结论二:进程资源的多少,本质上取决于其页表的复杂程度和映射的物理页框数量。而资源划分与共享的本质,就是对进程虚拟地址空间和页表的划分与操纵。
2.2.3 源码剖析
2.2.3.1 页表项(PTE):一个精心打包的unsigned long
上文将页表项(Page Table Entry, PTE)描述为一个包含 “物理页框地址” 和 “权限/状态位” 的结构。在内核源码中,这个概念被精炼地实现为一个无符号长符号长整型 (unsigned long)。
2.2.3.1.1 pte_t 与 pgd_t 的定义
// ⻚表项 (Page Table Entry)
typedef struct { unsigned long pte; } pte_t;
// ⻚全局⽬录项 (Page Global Directory Entry)
typedef struct { unsigned long pgd; } pgd_t;
从定义可以看出,无论是页目录项(pgd_t)还是页表项(pte_t),其本质都只是一个 unsigned long 整数。这种设计的背后是C语言的哲学:地址本身就是一个数字。一个32位的 unsigned long 足以容纳一个32位的物理地址,同时还能利用剩余的比特位来存储状态信息。
2.2.3.1.2
页表项中的标志位
在一个32位、页面大小为4KB的系统中,一个物理页框的基地址一定是4096( 2 12 2^{12} 212)的倍数,这意味着其地址的低12位永远为0。因此,在页表项中存储页框地址时,只需要存储其高20位即可。剩下的12个比特位,就可以被用来作为标志位,描述该页面的状态和权限。
以下是内核中定义的一些关键标志位:
/* 页表标志位 */
#define L_PTE_PRESENT (1 << 0) // 物理页存在位 (Present)
#define L_PTE_FILE (1 << 1) // only when !PRESENT
#define L_PTE_YOUNG (1 << 1) // 访问位 (Accessed),常用于页面置换算法
#define L_PTE_CACHEABLE (1 << 3) /* matches PTE */
#define L_PTE_USER (1 << 4) // 用户/内核位 (User/Supervisor)
#define L_PTE_WRITE (1 << 5) // 可写位 (Writable)
#define L_PTE_EXEC (1 << 6) // 可执行位 (Executable)
#define L_PTE_DIRTY (1 << 7) // 脏位 (Dirty),表示页面是否被写过
#define L_PTE_COHERENT (1 << 9) // I/O coherent (xsc3)
#define L_PTE_SHARED (1 << 10) // 共享页
#define L_PTE_ASID (1 << 11) // non-global (use ASID, v6)
这完美地解释了下面的页表结构图:一个条目中不仅有物理地址,还有一系列用于权限检查和状态管理的标志位。MMU硬件在进行地址翻译时,会同时读取并解析这些标志位。

2.2.3.2 页表的分配:一个4KB的物理页
页目录和页表本身也需要存储空间,它们就存放在物理内存中。内核在需要时,会为它们申请一个完整的、大小为4KB的物理页框。
// 分配一个页目录 (Page Global Directory)
pgd_t *pgd_alloc(struct mm_struct *mm)
{
pgd_t *ret, *init;
// __get_free_page 从伙伴系统中申请一个完整的物理页 (4KB)
ret = (pgd_t *) __get_free_page(GFP_KERNEL | __GFP_ZERO);
init = pgd_offset(&init_mm, 0UL);
if (ret) {
#ifdef CONFIG_ALPHA_LARGE_VMALLOC
memcpy (ret + USER_PTRS_PER_PGD, init + USER_PTRS_PER_PGD,
(PTRS_PER_PGD - USER_PTRS_PER_PGD - 1) * sizeof(pgd_t));
#else
pgd_val(ret[PTRS_PER_PGD-2]) = pgd_val(init[PTRS_PER_PGD-2]);
#endif
}
/* The last PGD entry is the VPTB self-map. */
pgd_val(ret[PTRS_PER_PGD-1])
= pte_val(mk_pte(virt_to_page(ret), PAGE_KERNEL));
return ret;
}
// 分配一个页表 (Page Table)
pte_t *pte_alloc_one_kernel(struct mm_struct *mm, unsigned long address)
{
// 同样申请一个完整的物理页
pte_t *pte = (pte_t *)__get_free_page(GFP_KERNEL|__GFP_REPEAT|__GFP_ZERO);
return pte;
}
从 pgd_alloc 和 pte_alloc_onernel 这两个函数可以看出:
- 页表即页框:一个页目录或一个页表,在物理上就是一个4KB的页框。
- 页表即数组:
__get_free_page返回的是一个物理页的起始地址(一个unsigned long)。通过将其强制类型转换为pgd_t *或pte_t *,内核就可以像操作一个数组一样,通过索引(pgd[index])来访问其中的每一个条目。
这再次印证了我们的理论:一个4KB的页可以存放 1024 个4字节的页表项,而虚拟地址中被拆分出的10位正好可以作为 0-1023 的索引来访问这个“数组”。
2.2.3.3 与进程的关联:mm_struct
那么,操作系统是如何找到一个特定进程的页表的呢?答案就在进程的内存描述符mm_struct中。
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct *mmap_cache; /* last find_vma result */
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr,
unsigned long len,
unsigned long pgoff,
unsigned long flags);
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
pgd_t *pgd; // 页目录起始地址
}
mm_struct 是内核用于管理一个进程虚拟地址空间的核心数据结构。其中有一个至关重要的指针成员 pgd,它就指向了该进程页全局目录(PGD)的物理地址。
当操作系统进行进程上下文切换时,其中一步关键操作就是将下一个要运行进程的 mm_struct->pgd 的值,加载到CPU的 CR3 寄存器中。这样,MMU就知道该从内存的哪个位置开始查找页表,从而为新进程进行地址翻译了。
2.3 进程的优点
- 创建一个新线程的代价要比创建一个新进程小得多。
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少得多。
- 线程占用的资源比进程要少。
- 能够有效利用多处理器的可扩展量。
- 在等待操作时操作系统的时间开销时,程序可执行其他的计算任务。
- 计算密集型应用,为了能够在多处理器系统上运行,将计算任务分解到多个线程中实现。
- I/O密集型应用,为了提高性能,将I/O操作重置,线程可以同时等待不同的I/O操作。
概念说明:
- 计算密集型:执行计算的部分占据多,主要以计算为主。比如加密解密、太复杂的计算等。
- I/O密集型:执行计算的部分少,主要以I/O为主。比如网络通信、访问数据库、访问文件等。
2.4 线程的缺点
-
性能损失: 一个很少被外部事件阻塞的计算密集型线程往往无法与其他线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
-
健壮性降低: 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因为共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说,线程之间是缺乏保护的。
-
缺乏访问控制: 进程是访问控制的基本粒度,在一个线程中调用某些 OS 函数会对整个进程造成影响。
-
编程难度提高: 编写与调试一个多线程程序比单线程程序困难得多。
2.5 线程异常
- 单个线程如果出现异常,野指针等问题导致线程崩溃,进程也会随着崩溃。
- 线程是进程的执行分支,线程出现异常,就类比进程出现异常,进而触发信号机制,终止进程,进程结束,该进程内的所有线程也就随即退出。
2.6 线程用途
- 合理的使用多线程,能提高CPU密集型程序的执行效率。
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)。
3. Linux 进程 VS 线程
在操作系统中,进程(Process)和线程(Thread)是两个核心且紧密相关的概念。长久以来,进程被视作资源分配的基本单位,而线程则被定义为CPU调度的基本单位。为了真正理解这一区别,必须深入其资源模型的内部,剖析哪些资源是共享的,哪些是私有的。
3.1 独占资源 vs. 共享资源
- 进程 (Process): 强调资源隔离与独立。每个进程都拥有自己独立的虚拟地址空间、文件描述符表、用户ID等。这种独立性保证了进程之间的安全性,一个进程的崩溃不会直接影响其他进程。
- 线程 (Thread): 强调资源共享与协作。一个进程内的所有线程共享该进程的大部分资源,但为了能够被独立调度,每个线程也必须拥有自己的一小部分私有资源。
3.2 线程的私有资源:独立性的基石
一个实体能够被操作系统独立调度的前提是,它必须拥有自己独一无二的执行上下文。线程的私有资源正是为此而生。
3.2.1 线程栈 (Stack)
这是线程最重要的私有资源。理解了线程栈的独立性,就理解了线程独立执行的本质。
- 函数调用机制: 程序的执行本质上是一系列函数调用。每次调用函数时,都会在栈上创建一个栈帧(Stack Frame),用于存放该函数的局部变量、参数、返回地址等信息。
- 独立的执行路径: 每个线程都有自己独立的执行序列,意味着它们会独立地调用不同的函数,形成自己专属的调用链。
- 结论: 因此,每个线程必须拥有自己独立的栈空间。这个独立的栈保证了线程在执行函数调用时,其内部的局部变量不会与其它线程相互干扰。在面试中,能够清晰地阐述线程栈的私有性,是证明深刻理解线程模型的关键。
3.2.2 上下文数据 (Context Data)
这指的是线程在被调度时,需要被保存和恢复的一组CPU寄存器状态。它代表了线程执行的“快照”,主要包括:
- 程序计数器 (PC): 指示线程下一条要执行的指令地址。
- 栈指针 (SP): 指向当前线程栈的栈顶。
- 通用寄存器: 用于暂存计算过程中的数据。
当线程切换发生时,操作系统会将被换下线程的这一整套寄存器信息保存到其线程控制块(task_struct)中,然后将即将运行线程的上下文信息加载到CPU寄存器中。
3.2.3 其他私有属性
- 线程ID (TID): 每个线程在内核中都有一个唯一的标识符。
- 错误码 (
errno): C语言库函数在出错时会设置一个全局的errno变量。在多线程环境下,errno必须是线程私有的,以防止一个线程的错误码被另一个线程覆盖。 - 信号掩码 (Signal Mask): 每个线程可以独立地选择阻塞或忽略某些信号。
- 优先级与调度属性: 每个线程都可以有自己的优先级,被调度器独立评估。
3.3 线程的共享资源:高效协作的源泉
除了上述明确为私有的资源外,一个进程内的所有其他资源都被其包含的所有线程共享。
- 虚拟地址空间 (Virtual Address Space): 这是最核心的共享资源。进程地址空间内的所有内容,包括代码段、数据段(全局变量、静态变量)、堆(动态分配的内存),都是所有线程共享的。这意味着,一个线程可以直接读写另一个线程创建的全局变量或堆内存,这是线程间通信最高效的方式。
- 文件描述符表: 进程打开的所有文件(或套接字)对该进程内的所有线程都是可见的。一个线程打开的文件,可以由另一个线程进行读写或关闭。
- 信号处理器 (Signal Dispositions): 对于一个信号(如
SIGINT),其处理方式(是忽略、捕获还是默认动作)在整个进程中是统一的,由所有线程共享。 - 当前工作目录 (Current Working Directory)。
- 用户ID (UID) 与 组ID (GID)。
3.4 重谈从单线程到多线程
通过上述对比,可以对我们编程模型的认知进行一次升级:
- 单进程,单线程: 这是学习C语言时的默认模型。一个进程实体,内部仅有一个执行流。
- 多进程,单线程: 这是经典的Unix并发模型。通过
fork()创建多个独立的进程,每个进程内部仍然只有一个线程。 - 单进程,多线程: 这是现代并发编程的主流模型。在一个进程资源容器内,创建多个执行流协同工作。
- 多进程,多线程: 在复杂的应用中,也可能同时使用多进程和多线程,例如Chrome浏览器,每个标签页是一个独立的进程,而每个进程内部又包含多个线程来处理渲染、网络等任务。
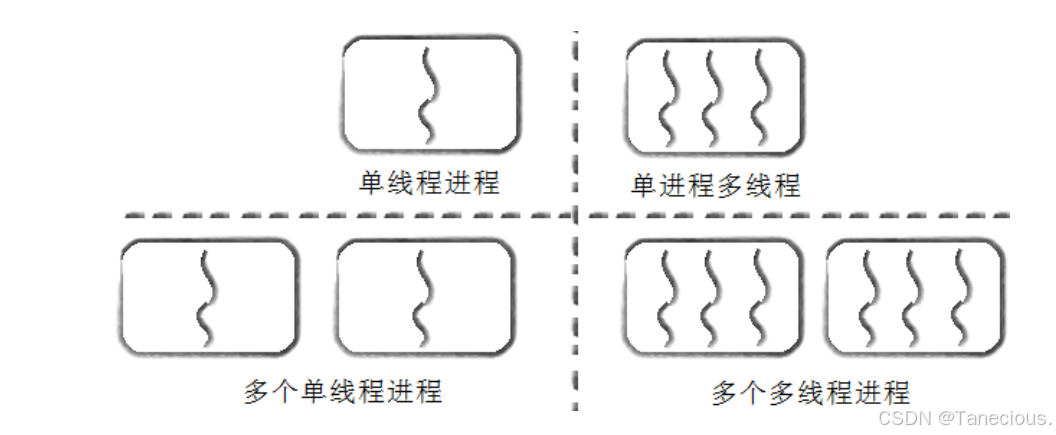
核心结论: 进程是操作系统进行资源分配和保护的基本单位,它像一个容器,圈定了资源(如地址空间)的边界。而线程是CPU调度和执行的基本单位,它在进程这个容器所提供的资源上运行。一个进程必须至少拥有一个线程,而我们过去所称的“进程”,其实可以更精确地理解为“一个单线程的进程”。
4. 线程控制
4.1 验证线程理论
在前面的章节中,深入探讨了线程的理论模型,包括其优势、缺点以及与进程的根本区别。现在,将从理论走向实践,通过具体的代码示例来验证两个核心论断和一个认识:
- Linux内核中的线程究竟是如何被实现的?
- 单个线程的崩溃为何会导致整个进程的终结?
- 认识一下 C++11 中的多线程理论。
4.1.1 实验工具:POSIX线程库 (Pthreads)
要在 Linux 下进行多线程编程,通常使用一套标准的API——POSIX线程库,简称 Pthreads 。它并非 Linux 的系统调用,而是一个被广泛遵循的用户态库标准。下面将使用其核心函数 pthread_create 来创建新线程。
具体的POSIX线程库的介绍在下文。
在开始实验前,必须明确一点:因为 Pthreads 是一个第三方库,我们在编译代码时,除了包含头文件 <pthread.h> ,还必须在链接阶段显式地告诉链接器去链接这个库。否则,就会则,就会遇到 “ undefined reference to pthread_create ” 的链接错误。
正确的编译命令如下:
gcc test.c -o test -lpthread
-l 选项告诉链接器去链接一个库,pthread 是 libpthread.so 这个库文件的规范名称。
4.1.2 验证一:揭示线程的本质——轻量级进程 (LWP)
之前的理论是:Linux内核中没有真正意义上的 “线程” 实体,它是通过 “轻量级进程”(Lightweight Process, LWP)来模拟线程的。同一个进程的所有“线程”在内核看来,其实是一组共享特定资源(如地址空间)的LWP。
4.1.2.1 实验代码
这里编写一个简单的程序,主函数(主线程)创建一个新线程,然后两者各自进入无限循环,打印自己的身份。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void* thread_run(void* args)
{
const char* name = (const char*)args;
while (1)
{
printf("I am the new thread, name: %s\n", name);
sleep(1);
}
return NULL;
}
int main()
{
pthread_t tid;
// 创建一个新线程,让它执行 thread_run 函数
pthread_create(&tid, NULL, thread_run, "thread-1");
while (1)
{
printf("I am the main thread\n");
sleep(1);
}
return 0;
}
4.1.2.2 现象观测与分析
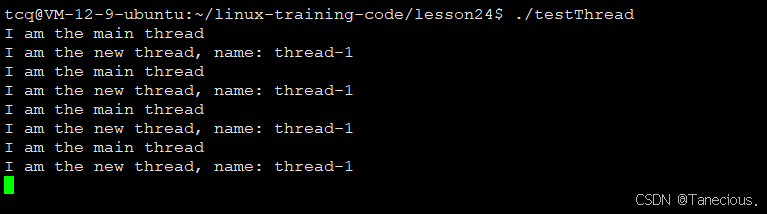
编译并运行上述代码,可以看到来自主线程和新线程的输出交替出现,这直观地证明了在一个进程内确实存在两个并行的执行流
现在,使用ps命令来深入探究其内核层面的实现:
- 从进程视角查看:
ps -ax | head -1 && ps -ax | grep testThread

结果会显示,只存在一个PID(进程ID)与程序对应。这说明从进程的维度看,它就是一个独立的实体。如果向这个PID发送信号(如kill -9 <PID>),整个程序(包括两个线程)会立即立即终止。这验证了信号是发送给进程的,并由其所有线程共享处理。
- 从线程视角查看:
ps -aL | head -1 && ps -aL | grep testThread

-L选项会列出系统中的每一个级进程(LWP)。此时,我们会看到两条记录:
- 这两条记录的
PID列是完全相同的。 - 这两条记录的
LWP列(有时也显示为TID)是不同的。
4.1.2.3 结论补充
结论:
这个实验结果完美地验证了前文理论:
- Linux线程就是LWP:操作系统调度器实际调度的实体是 LWP 。
- PID标识进程,LWP标识线程:当一个进程刚启动时,它内部只有一个执行流,此时其 PID 和 LWP 的值是相等的。每当通过
pthread_create创建一个新线程,内核实质上是创建了一个新的 LWP,这个新的 LWP 共享其父进程的 PID,但拥有一个自己独一无二的 LWP 号。 - 调度器如何区分: 当内核需要进行上下文切换时,它可以通过比较两个 LWP 的 PID 来判断这是一次线程切换(PID相同)还是一次进程(PID不同),从而决定是否需要切换页表(
CR3寄存器)等重量级资源。
补充:
在这个实验中,可能会注意到,主线程和新线程的 printf 输出有时会混杂在一起,出现不完整的打印行。这是因为标准输出(显示器)是一个资源。两个线程都在没有加锁保护的情况下同时向同一个文件(终端文件)写入,导致了写入操作的非原子性,从而产生了竞态条件(Race Condition)。这也为我们后续学习线程同步(如互斥锁)的必要性提供了直观的例证。
4.1.3 验证二:“一荣俱荣,一损俱损”
之前的理论是:由于缺乏内存隔离,一个线程的崩溃将导致整个进程的毁灭,这使得多线程程序的健壮性低于多进程程序。
4.1.3.1 实验代码
这里修改 thread_run 函数,让它在运行1秒后,执行一个非法的数学运算除以零。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void* thread_run(void* args)
{
printf("New thread running...\n");
sleep(1); // 运行1秒
int a = 10;
a = a / 0; // 触发致命错误
printf("This line will never be printed.\n");
return NULL;
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, thread_run, NULL);
while (1)
{
printf("Main thread is still alive...\n");
sleep(1);
}
return 0;
}
4.1.3.2 现象观测与分析
编译并运行代码。会观察到:
- 程序启动,主线程和新线程开始运行。
- 大约1秒后,终端打印出
Floating point exception (core dumped)(浮点数异常)。 - 整个程序立即退出,主线程的循环打印也随之停止。

4.1.3.3 结论补充
实验结果清晰地证明了:任何一个线程的致命错误都会导致整个进程的。
其底层原理是:
- 当CPU执行除零指令时,会触发一个硬件异常。
- 内核捕获这个异常,并将其转换为一个信号(在此例中是
SIGFPE)发送给当前正在运行的 LWP 所属的进程。 - 信号是发送给整个进程的,该进程的默认信号处理方式是终止运行。
- 进程一旦终止,其拥有的所有资源(包括地址空间、所有LWP)都会被操作系统回收。
4.2 POSIX 线程库
在上一章节的实践中,使用了 pthread_create 函数来创建线程。一个自然而然的问题是:为什么创建线程需要一个用户态的库,而不是一个直接的系统调用?这背后反映了Linux系统在设计上的一大特点。
4.2.1 概念的鸿沟:用户眼中的“线程” vs. 内核眼中的“进程”
要理解Pthreads库的必要性,首先必须认识到用户(程序员)和Linux内核在 “线程” 概念上的根本分歧。
- 用户的视角:对于应用程序开发者而言,“线程”是一个清晰、独立的概念。它是一个轻量级的执行单元,用于实现并发,拥有自己的执行流,但与同一进程的其他线程共享内存。这是所有操作系统教材和编程范式中通用的模型。用户需要的是直接创建和管理“线程”的接口。
- Linux 内核的视角:Linux 内核的设计哲学中,最核心的执行实体是进程。内核并不存在一个与用户概念完全对应的、名为“线程”的独立数据结构。它所提供的,是创建**轻量级进程(LWP)**的能力。
内核通过fork, vfork, clone等系统调用来创建新进程。这些调用的区别在于新创建的进程与父进程之间资源共享的程度。。
核心矛盾:用户想要 “线程” ,但内核只提供不同共享程度的 “进程”(即LWP)。用户不关心 LWP 的实现细节,而内核不懂用户口中的 “线程” 为何物。这两者之间存在一道明显的概念鸿沟。
4.2.2 Pthreads库:填补鸿沟的抽象层
为了解决这种不匹配,Linux 提供了一个位于用户空间和内核空间之间的中间层(或适配层)——这便是线程库,其中最标准、最通用的就是 Pthreads 库 ( libpthread )。
Pthreads 库的核心职责是:将用户对“线程”的操作,翻译成内核对“轻量级进程”的操作。
通过这种增加一层软件中间层的方式,Pthreads 库为用户屏蔽了底层的 LWP 和各种系统调用的复杂性,提供了一套符合通用编程模型的、标准的、可移植的线程API。
4.2.3 两种线程模型
这种实现模式引出了两种线程模型的讨论:
- 用户级线程:线程的创建、管理和调度完全在用户空间的一个库中完成,内核对此一无所知。这种模型现在已很少见。
- 内核级线程:线程是内核直接支持和调度的实体。内核有专门的数据结构来表示线程,并提供系统调用来直接创建和管理它们。Windows操作系统是这种模型的典型代表。
那么,Linux 的 Pthreads 模型属于哪一种呢?它实际上是一种混合模型,但通常被归类为基于内核级线程的用户级线程实现。
- 用户级接口:从API层面看,它是一套用户空间的库函数。
- 内核级实体:从执行层面看,每一个用户线程(pthread)都由一个内核实体(LWP)来支撑。调度器看到并调度的是LWP。这种一一对应的关系通常被称为1:1线程模型。
因此可以说,Pthreads 是 Linux 系统为用户提供的原生线程库 (Native POSIX Thread Library, NPTL),它强有力地与系统内核绑定,共同构成了 Linux 的线程实现方案。
4.2.4 总结
在 Linux 下对线程的操作之所以需要库,是因为 Linux 内核本身不直接提供 “线程” 这一抽象。Pthreads 库作为一个至关重要的适配层,将程序员所熟悉的通用线程模型,映射到了 Linux 内核基于轻量级进程(LWP)的底层实现上,从而为用户提供了一套功能强大且遵循标准的多线程编程接口。
4.3 创建线程
4.3.1 创建线程: pthread_create
前文已经见过这个函数,现在,现在对其进行一次正式、详细的剖析。
函数原型:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
参数详解
pthread_t *thread: 这是一个输出型参数。如果线程创建成功,这个指针所指向的内存单元将被填充上新创建线程的唯一标识符,即线程ID。pthread_t是一个不透明的数据类型,不应直接对其进行数值运算或假设其内部实现。const pthread_attr_t *attr: 这是一个输入型参数,用于设置线程的属性,例如线程的栈大小、调度策略等。在绝大多数情况下不需要特殊设置,只需传入NULL即可,此时库会使用一套默认属性来创建线程。void *(*start_routine) (void *):这是一个函数指针。它指向一个函数,这个函数将成为新线程的入口点(Entry Point)。一旦线程被成功创建,它就会立即开始执行这个函数。这是一种典型的**回调(Callback)**机制。- **
void *arg:**这个参数将被传递给start_routine所指向的函数。它允许用户在创建线程时,向新线程传递任意类型的数据(通常是指针)。如果start_routine不需要参数,则可以传入NULL。
返回值
- 若成功,返回
0。 - 若失败,返回一个正数的错误码。注意,Pthreads 函数通常不设置全局的
errno,而是直接通过返回值来报告错误。
4.3.2 等待线程: pthread_join
创建一个线程后,主线程(或其他任何线程)通常需要等待它执行完毕并回收其资源。如果不进行等待,退出的线程资源可能无法被完全释放,造成类似“僵尸进程”的资源泄漏问题。 pthread_join 函数承担了这个职责。
函数原型:
int pthread_join(pthread_t thread, void **retval);
参数详解
pthread_t thread:需要等待的线程的ID,即pthread_create返回的那个值。调用pthread_join的线程将会被阻塞,直到ID为thread的目标线程执行结束。void **retval:这是一个输出型参数,用于接收目标线程的返回值。如果调用者不关心目标线程的返回值,可以传入NULL。
深入剖析返回值 (
void **retval)这是初学者最容易混淆的地方。为什么需要一个二级指针?
- 线程的返回值类型被规定为
void*,即一个通用指针。pthread_join函数需要将这个void*类型的值,写入到调用者(主线程)提供的一个变量里。- 在C语言中,要在函数内部修改外部一个变量的值,必须传入该变量的地址。
- 因此,要修改一个
void*类型的变量(如ret),我们必须传入它的地址,即&ret。ret的类型是void*,那么&ret类型自然就是void**。所以,
pthread_join(tid, &ret)的语义是:“请把tid线程的void*返回值,写入到这个void*类型变量ret的地址所指向的空间里。”
补充:
pthread_join只能获取线程的正常退出码,无法获取其是否因异常信号而终止。原因在于:线程的致命异常是进程级别的灾难。
如果一个线程因为非法内存访问、除零等问题崩溃,内核会向整个进程发送一个致命信号(如
SIGSEGV)。该信号会导致整个进程(包括其中所有线程)被终止。此时,主线程自身也已崩溃,根本没有机会去调用pthread_join来检查退出状态。
4.3.3 实践:创建、等待与数据传递的线程 demo
下面是一个完整的示例,它演示了线程的创建、等待、ID的获取以及返回值的处理。
示例代码:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
void* thread_run(void* args)
{
const char* name = (const char*)args;
int i = 0;
for (i = 0; i < 5; i++)
{
printf("I am new thread, name: %s, loop %d\n", name, i);
sleep(1);
}
return (void*)100; // 线程退出,返回一个值
}
int main()
{
pthread_t tid;
char thread_name[] = "thread-1";
// 1. 创建线程,并传递参数 "thread-1"
pthread_create(&tid, NULL, thread_run, (void*)thread_name);
printf("Main thread created a new thread [%lu]\n", tid);
// 2. 等待新线程结束,并获取其返回值
void* ret = NULL;
pthread_join(tid, &ret);
printf("Main thread joined. New thread exited with code: %ld\n", (long)ret);
return 0;
}
运行结果:

可以看到,当代码运行起来之后,父进程立即创建一个新线程,并且新线程也将自己的 tid 打印出来,并开始新线程代码的运行,在运行的同时,父进程则是一直在等待,直到线程结束。但是可以看到这里打印出的tid是一个很大的无符号整数,这是为什么呢,这个很大的数字又代表什么呢?
4.3.4 线程ID(pthread_t)的剖析与验证
4.3.4.1 深度剖析线程ID
在上面的 demo 代码中,可以发现打印出的tid 是一个很大的无符号整数。他并不是之前使用指令在内核中查到的 LWP号,这个ID是 Pthreads 库在用户态维护的标识符。因为 POSIX库的目的是通过封装,为用户提供了统一的操作线程的接口,其最终目的就是要隐藏了底层的实现细节。所以用户只需要知道使用这个可移植的ID即可,至于此数字如何得到底层细节没有必要知道。
4.3.4.2 验证线程ID
可以在线程内部通过 pthread_self() 函数来获取自身的线程ID,并与主线程得到的ID进行比较。
函数原型:
pthread_t pthread_self(void);
参数详解
- 该函数没有任何参数。
返回值
- 成功调用时,它会返回调用者线程的线程ID。这个返回值的类型是
pthread_t。 - 这个函数总是成功的,它不像其他Pthreads函数那样会返回错误码。
示例代码:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
void* thread_run(void* args)
{
const char* name = (const char*)args;
// 3. 新线程获取自身线程ID
pthread_t self_tid = pthread_self();
printf("I am new thread, name: %s, loop %d, thread ID %d\n", name, i, self_tid);
sleep(1);
return (void*)100; // 线程退出,返回一个值
}
int main()
{
pthread_t tid;
char thread_name[] = "thread-1";
// 1. 创建线程,并传递参数 "thread-1"
pthread_create(&tid, NULL, thread_run, (void*)thread_name);
printf("Main thread created a new thread [%lu]\n", tid);
// 2. 等待新线程结束,并获取其返回值
void* ret = NULL;
pthread_join(tid, &ret);
printf("Main thread joined. New thread exited with code: %ld\n", (long)ret);
return 0;
}
运行结果:

4.4 线程终止
如果需要只终止某个线程而不终止整个进程,可以有三种方法:
- 从线程函数
return。这种方法对主线程不适用,从main函数return相当于调用exit。- 线程可以调用
pthread_exit终止自己。- 一个线程可以调用
pthread_cancel终止同一进程中的另一个线程。
4.4.1 线程的自我终止:两种等效的方式
一个线程完成其任务后,最自然、最推荐的退出方式是自我终止。
4.4.1.1 方式一:从线程入口函数 return
这是最标准、最清晰最清晰的线程终止方式。当线程的入口函数执行到 return 语句时,该线程的生命周期便自然结束。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void* thread_run(void* args)
{
// 新线程开始工作
printf(" -> New Thread: Starting my work...\n");
for (int i = 1; i <= 3; i++)
{
printf(" -> New Thread: Working... (%d/3)\n", i);
sleep(1);
}
// 任务完成, 通过 return 返回退出状态码 100。
printf(" -> New Thread: Work complete. Returning with exit code 100.\n");
return (void*)100;
}
int main()
{
pthread_t tid;
void* retval = NULL;
// 创建新线程
printf("Main Thread: Creating a new thread.\n");
pthread_create(&tid, NULL, thread_run, NULL);
// 主线程等待新线程
printf("Main Thread: Waiting for the new thread to finish...\n");
pthread_join(tid, &retval);
// 新线程结束,主线程通过 pthread_join 捕获返回值
printf("Main Thread: Joined with the new thread.\n");
printf("Main Thread: The captured return value is %ld.\n", (long)retval);
return 0;
}
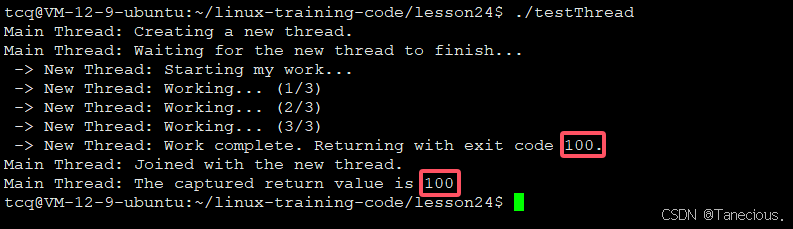
新线程自然地完成了它的工作流程,并通过 return 语句将其退出码 100 传递回来。主线程通过 pthread_join 成功捕获并验证了这个值。这是最理想的线程退出模型。
4.4.1.2 方式二:调用 pthread_exit()
Pthreads库 提供了一个专门的函数,允许线程在入口函数的任何位置立即终止自己,而无需等到函数末尾。
函数原型
#include <pthread.h>
void pthread_exit(void *retval);
参数与功能
void *retval:retval是一个void*类型的参数,它将作为该线程的退出状态码。其他线程可以通过pthread_join()来获取这个值。- 该函数不会返回。一旦调用,当前线程将立即终止。
pthread_exit() 的效果与在入口函数末尾 return 一个值是等价的。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void* thread_run(void* args)
{
printf(" -> New Thread: Starting my work...\n");
sleep(2);
int error_condition = 1; // 模拟一个错误条件
if (error_condition)
{
printf(" -> New Thread: An error occurred! Exiting early with code 200.\n");
// 在函数中间提前退出,效果等同于 return (void*)200;
pthread_exit((void*)200);
}
// 因为 pthread_exit 被调用,下面的代码将永远不会被执行
printf(" -> New Thread: This line will never be printed.\n");
return (void*)0;
}
int main()
{
pthread_t tid;
void* retval = NULL;
// 创建新线程
printf("Main Thread: Creating a new thread.\n");
pthread_create(&tid, NULL, thread_run, NULL);
// 主线程等待新线程
printf("Main Thread: Waiting for the new thread to finish...\n");
pthread_join(tid, &retval);
// 新线程结束,主线程通过 pthread_join 捕获返回值
printf("Main Thread: Joined with the new thread.\n");
printf("Main Thread: The captured return value is %ld.\n", (long)retval);
return 0;
}
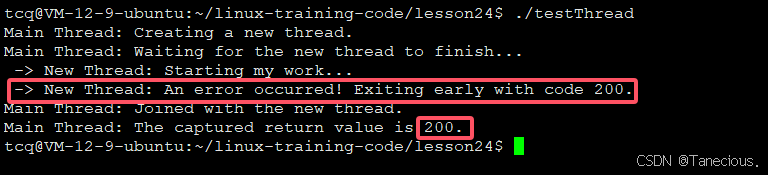
分析显示,新线程没有执行到函数末尾的 return 语句。它在检测到模拟的错误条件后,调用 pthread_exit() 提前终止。主线程依然通过 pthread_join 成功捕获了 pthread_exit() 传递的退出码 200,证明了其与 return 的等效性。
4.4.2 从外部终止:取消一个线程
除了线程自我终止,Pthreads 还提供了一种机制,允许一个线程去“请求”另一个线程终止。
4.4.2.1 函数介绍
函数原型
#include <pthread.h>
int pthread_cancel(pthread_t thread);
参数:
- **
pthread_t thread:**要取消的目标线程的ID。
返回值:
- 成功发送请求返回0,失败返回错误码
功能:
pthread_cancel()的作用是向目标线程发送一个取消请求。它并不会粗暴地、立即地杀死目标线程,而是将目标线程标记为“已被请求取消”。目标线程何时以及是否真正终止,还取决于其自身的设置(取消点、取消类型等,这是更高级的话题)。
4.4.2.2 等待被取消的线程
当一个线程被成功取消后,它就进入了终止状态。其他线程同样需要调用 pthread_join() 来等待它并回收其资源。那么,pthread_join() 获取到的返回值会是什么呢?
答案是一个特殊的宏:PTHREAD_CANCELED。
PTHREAD_CANCELED 被定义为 (void *) -1。当 pthread_join() 返回的退出码等于这个特殊值时,就表明目标线程是被取消的,而不是正常 return 或 pthread_exit() 的。
4.4.2.3 实践示例
下面的代码演示了主线程如何取消一个正在无限循环的子线程。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void* infinite_loop(void* args)
{
printf("New thread starting its infinite loop...\n");
while(1)
{
// 在实际应用中,这里应该是一个"取消点",例如 read, write, sleep
// sleep() 是一个取消点,允许线程响应取消请求
sleep(1);
}
// 这行代码永远不会执行
return NULL;
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, infinite_loop, NULL);
// 让新线程先运行3秒
printf("Main thread: letting the new thread run for 3 seconds.\n");
sleep(3);
// 发送取消请求
printf("Main thread: sending a cancellation request...\n");
pthread_cancel(tid);
// 等待被取消的线程,并获取其退出状态
void* ret_val = NULL;
pthread_join(tid, &ret_val);
if (ret_val == PTHREAD_CANCELED)
{
printf("Main thread: Confirmed, the new thread was canceled. Exit code: %ld\n", (long)ret_val);
}
else
{
printf("Main thread: The new thread exited normally.\n");
}
return 0;
}

4.4.3 致命的错误:在线程中调用 exit()
一个绝对要避免的常见错误是在线程函数中调用 exit()。
pthread_exit(): 终止调用它的线程。exit(): 终止调用它的进程。
exit() 是一个进程级别的函数。无论在哪个线程中被调用,它都会导致整个进程(包括其内部的所有线程)立即终止。除非你的意图确实是结束整个程序,否则绝不应该在线程函数中使用 exit() 来终止单个线程。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h> // for exit()
#include <pthread.h>
void* thread_run(void* args)
{
printf(" -> New Thread: I will terminate the whole process in 3 seconds.\n");
sleep(3);
printf(" -> New Thread: Calling exit(13) NOW!\n");
// 这是一个错误的做法!它会杀死整个进程!
exit(13);
// 下面的代码永远不会执行
return NULL;
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, thread_run, NULL);
// 主线程进入自己的循环,它期望能一直运行
for (int i = 0; i < 10; i++)
{
printf("Main Thread: I am still alive... (%d/10)\n", i + 1);
sleep(1);
}
printf("Main Thread: This line will never be reached.\n");
pthread_join(tid, NULL); // 也永远不会执行到这里
return 0;
}
程序在这里戛然而止。主线程的循环在打印第3次后被中断,并没有完成10次循环。main 函数最后 printf 和 pthread_join 都没有被执行。在终端中执行 echo $? 会显示 13。这无可辩驳地证明了:新线程调用的 exit(13) 终止了整个进程,主线程也随之被销毁。
4.4.4 总结与最佳实践
| 终止方式 | 调用者 | 作用范围 | 结果 | 推荐度 |
|---|---|---|---|---|
return retval; | 线程自身 | 单个线程 | 线程正常退出,pthread_join 获取 retval | ⭐⭐⭐⭐⭐ |
pthread_exit(retval); | 线程自身 | 单个线程 | 线程正常退出,pthread_join 获取 retval | ⭐⭐⭐⭐ |
exit(code); | 任意线程 | 整个进程 | 进程终止,所有线程被销毁 | ❌ (除非有意) |
pthread_cancel(tid); | 其他线程 | 单个线程 | 线程被取消,pthread_join 获取 PTHREAD_CANCELED ((void*)-1) | ⭐⭐⭐ |
4.5 分离线程
在所有之前的例子中,都有一个不变的模式:主线程创建新线程后,必须调用 pthread_join() 来等待它,以回收其资源。然而,在许多真实世界的应用中,例如后台服务器或桌面应用,主线程本身是一个永不退出的事件循环。它不能被 pthread_join() 长时间阻塞。
那么,能否创建一个 “即发即忘” 的线程,让它在任务完成后自动清理自己,而无需主线程的干预呢?答案是肯定的,这便是线程分离机制。
4.5.1核心概念:可结合 (Joinable) vs. 分离 (Detached)
默认情况下,一个线程被创建时处于**可结合(Joinable)**状态。这意味着它必须被其他线程使用 pthread_join() 来“回收”。如果不这样做,当这个线程终止时,其核心资源(如线程ID和退出状态)会一直保留在内存中,造成资源泄漏,这与僵尸进程非常相似。
与之相对的是分离(Detached)状态。当一个线程被设置为分离状态后,它就与进程中的其他线程“解绑”了。系统保证当这个线程终止时,其所有资源都会被自动回收。
注意:
线程分离不等于资源隔离。分离后的线程依然在同一个进程的地址空间内运行,它仍然共享全局变量、文件描述符等所有共享资源。分离的唯一含义是:该线程不再能被 pthread_join() 等待。主线程只是放弃了等待它的权利和义务。
4.5.2 如何分离线程:pthread_detach()
Pthreads库提供了 pthread_detachhread_detach() 函数来将一个可结合的线程转换为分离状态。
函数原型
#include <pthread.h>
int pthread_detach(pthread_t thread);
参数:
pthread_t thread: 要设置为分离状态的目标线程的ID。
功能:
- 调用此函数后,ID为
thread的线程就被标记为分离状态。
返回值:
- 成功返回0,失败返回错误码。
4.5.3 分离线程的方式
有两种主要的方式来分离一个线程:
- 由创建者(或其他线程)分离目标线程。
- 线程自己分离自己。
下面通过两个实例来分别演示。
4.5.3.1 方式一:由主线程分离新线程
这是最常见的用法。主线程创建了一个工作线程后,如果它不关心这个工作线程的返回值,并且希望它完成后自动清理,就可以立即将其分离。
#include <stdio.h>
#include <unistd.h>
#include <string.h> // for strerror()
#include <errno.h> // for errno values
#include <pthread.h>
void* worker_thread_run(void* args)
{
// 新线程开始工作
printf(" -> Worker Thread: Starting my 5-second task.\n");
sleep(5);
// 新线程工作完成,结束线程
printf(" -> Worker Thread: Task finished, I will now exit and self-release.\n");
return NULL;
}
int main()
{
// 创建新线程
pthread_t tid;
pthread_create(&tid, NULL, worker_thread_run, NULL);
printf("Main Thread: Created a worker thread.\n");
// 立即分离新线程
printf("Main Thread: Detaching the worker thread...\n");
pthread_detach(tid);
// 主线程继续做自己的事情,这里用 sleep 模拟
// 确保主线程比工作线程活得长,以便观察
sleep(7);
// 现在尝试去 join 一个已经被分离的线程
printf("Main Thread: Attempting to join the detached thread...\n");
int join_ret = pthread_join(tid, NULL);
if (join_ret != 0)
{
// 预期返回:EINVAL (22) is "Invalid argument"
printf("Main Thread: As expected, pthread_join failed.\n");
printf("Main Thread: Error code %d means: %s\n", join_ret, strerror(join_ret));
}
else
{
printf("Main Thread: This should not happen!\n");
}
printf("Main Thread: Program finished.\n");
return 0;
}
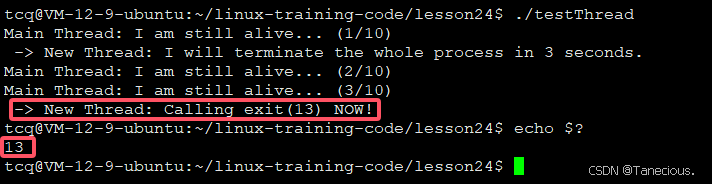
运行流程:
- 分离操作:主线程创建线程后,立即调用
pthreaddetach(),然后继续执行自己的sleep(7)。 - 并发执行:工作线程独立地执行它的5秒任务,并在结束后打印退出信息。
- Join失败:主线程在
sleep(7)结束后,尝试调用pthread_join()此时,工作线程早已终止并(由系统)释放了资源。pthread_join()找不到一个可结合的目标线程,因此调用**strerror(join_ret)**,返回错误码22,即EINVAL(无效参数)。` - 结论:这个实验完美地证明了,一个被分离的线程是不能被
join的。
4.5.3.2 线程自我分离
一个线程也可以在自己的入口函数中决定将自己设置为分离状态。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
#include <pthread.h>
void* worker_thread_run(void* args)
{
// 线程获取自己的ID
pthread_t self_id = pthread_self();
// 线程自己分离自己
pthread_detach(self_id);
printf(" -> Worker Thread [%lu]: I have detached myself.\n", self_id);
// 新线程开始工作
printf(" -> Worker Thread: Starting my 5-second task.\n");
sleep(5);
// 工作完成结束线程
printf(" -> Worker Thread: Task finished, exiting.\n");
return NULL;
}
int main()
{
// 创建新线程
pthread_t tid;
pthread_create(&tid, NULL, worker_thread_run, NULL);
printf("Main Thread: Created a worker thread [%lu].\n", tid);
// 等待足够长的时间,以确保工作线程已经把自己分离了
sleep(1);
// 主进程尝试捕获新线程
printf("Main Thread: Attempting to join the (now detached) thread...\n");
int join_ret = pthread_join(tid, NULL);
if (join_ret != 0)
{
// 成功捕获
printf("Main Thread: As expected, pthread_join failed.\n");
printf("Main Thread: Error code %d means: %s\n", join_ret, strerror(join_ret));
}
// 主线程需要存活,否则进程退出,所有线程都会被杀死
sleep(6);
printf("Main Thread: Program finished.\n");
return 0;
}
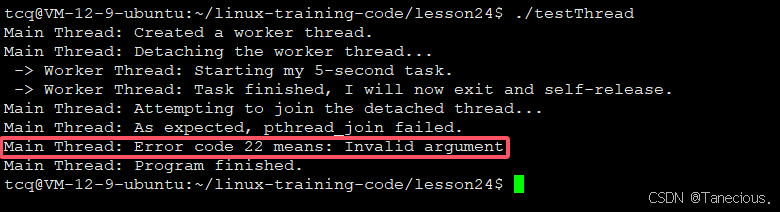
结果与方式一完全一致。新线程一开始就调用 pthread_detach(pthread_self()) 将自己设置为分离状态。因此,当主线程稍后尝试 pthread_join() 时,尽管新线程没有结束,同样会立即失败并返回 EINVAL 错误。
5. 线程ID及进程地址空间布局
5.1 一切的舞台:进程虚拟地址空间
首先,必须明确两个基本事实:
- 用户编写的、包含多线程代码的程序,在编译后是一个标准的ELF格式可执行文件。
libpthread.so本身,也是一个ELF格式的动态库(共享对象)文件。
当用户的程序运行时,操作系统会为其创建一个进程和相应的虚拟地址空间。然后,动态链接器会介入,将libpthread.so这个动态库加载并映射到该进程的虚拟地址空间中的某个区域(通常是共享库区域)。
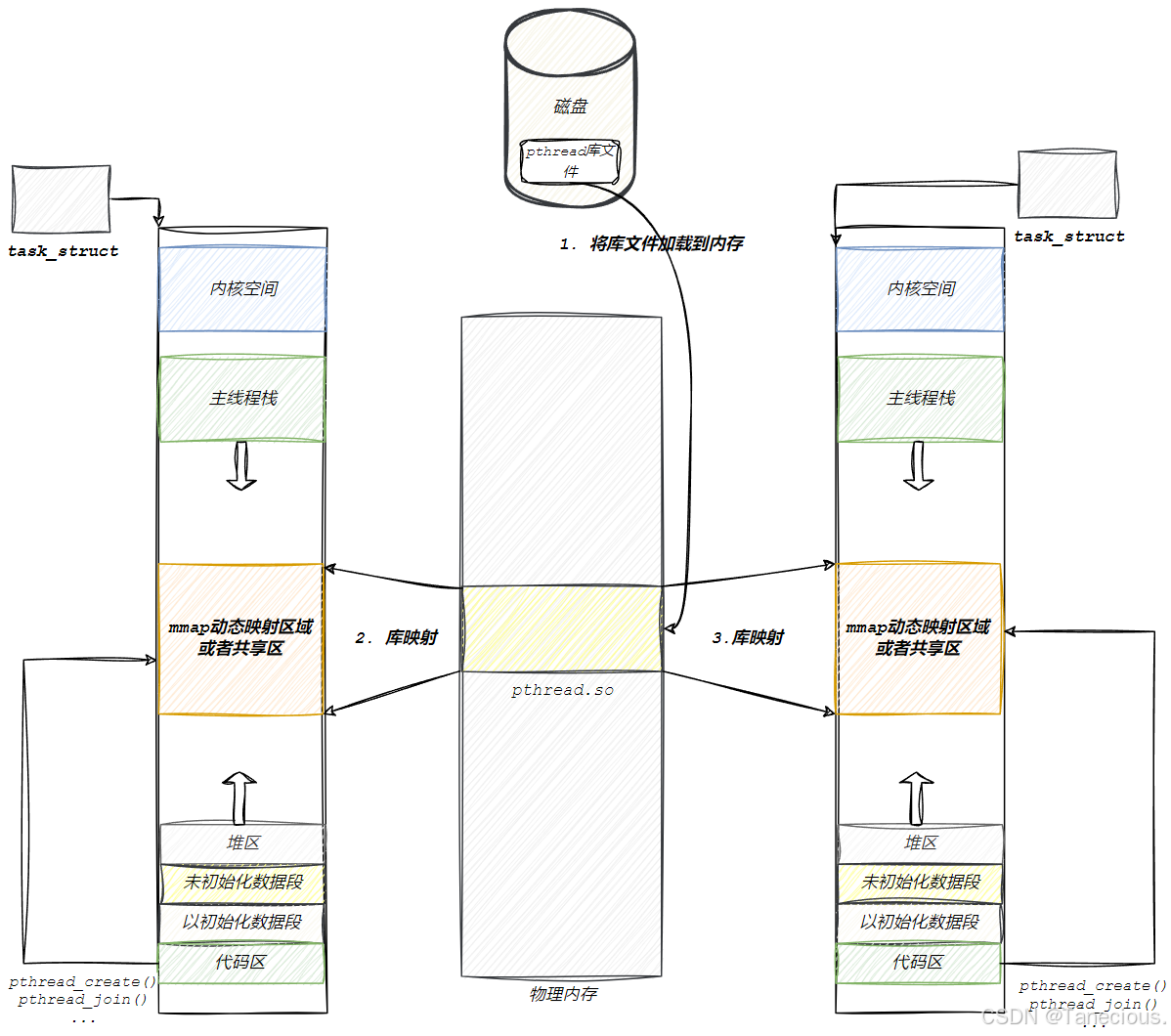
结论:Pthreads 库的代码和数据,与用户自己的代码和数据,都位于同一个进程的虚拟地址空间中。这意味着,用户的代码可以直接调用库函数,而库函数也可以在进程的地址空间内申请内存、读写数据。
5.2 库管理线程
既然 “线程” 的概念是 Pthreads 库在用户态实现的,那么库就必须有办法追踪和管理它所创建的每一个线程。这引出了一个核心的数据结构,这个核心的数据结构,在glibc的NPTL(原生POSIX线程库)实现中,被称为 struct pthread。这就是我们之前所说的**线程控制块(TCB)**的真实面目。
// A simplified representation of the TCB in glibc's NPTL
struct pthread
{
// ... other members ...
pid_t lwp; // The LWP (Lightweight Process) ID from the kernel.
// This is the direct link to the kernel entity!
void *(*start_routine) (void *); // Pointer to the user-provided thread function.
void *arg; // Argument to be passed to the start_routine.
void *retval; // To store the return value when the thread exits.
int joinable; // A flag to indicate if the thread is joinable or detached.
// ... many other fields for thread attributes, cancellation, etc. ...
};
- 必要性:库需要一个地方来存储每个线程的属性,从源码可以看出:
- 内核关联:
pid_t lwp;这个成员是整个模型中最关键的证据。它直接存储了与此用户态线程相关联的内核轻量级进程的ID。这证明了Linux线程是一一对应的1:1模型。 - 任务记录:
start_routine和arg成员记录了用户指定的线程入口函数及其参数。 - 结果:
retval成员就是为线程的返回值预留的空间。 - 状态管理:
joinable这样的标志位用于管理线程的状态(可结合或分离)。
- 内核关联:
- 类比:这与C标准库中的
fopen()函数非常相似。当调用fopen()时,库会在堆上malloc一个FILE结构体,用来管理文件的缓冲区、文件描述符等信息,然后将这个结构体的地址返回给你。 pthread_create()的动作:同理,当调用pthread_create()时,Pthreads库会在其内部为这个新线程创建一个TCB结构体,用来描述和管理这个用户态线程。
关键区别:这个用户态的TCB不是内核的进程控制块(PCB / task_struct)。TCB只包含线程在用户态的属性,它不包含任何与内核调度相关的信息(如时间片、优先级、寄存器上下文等)。那些信息都存放在与该线程一一对应的LWP的内核PCB中。
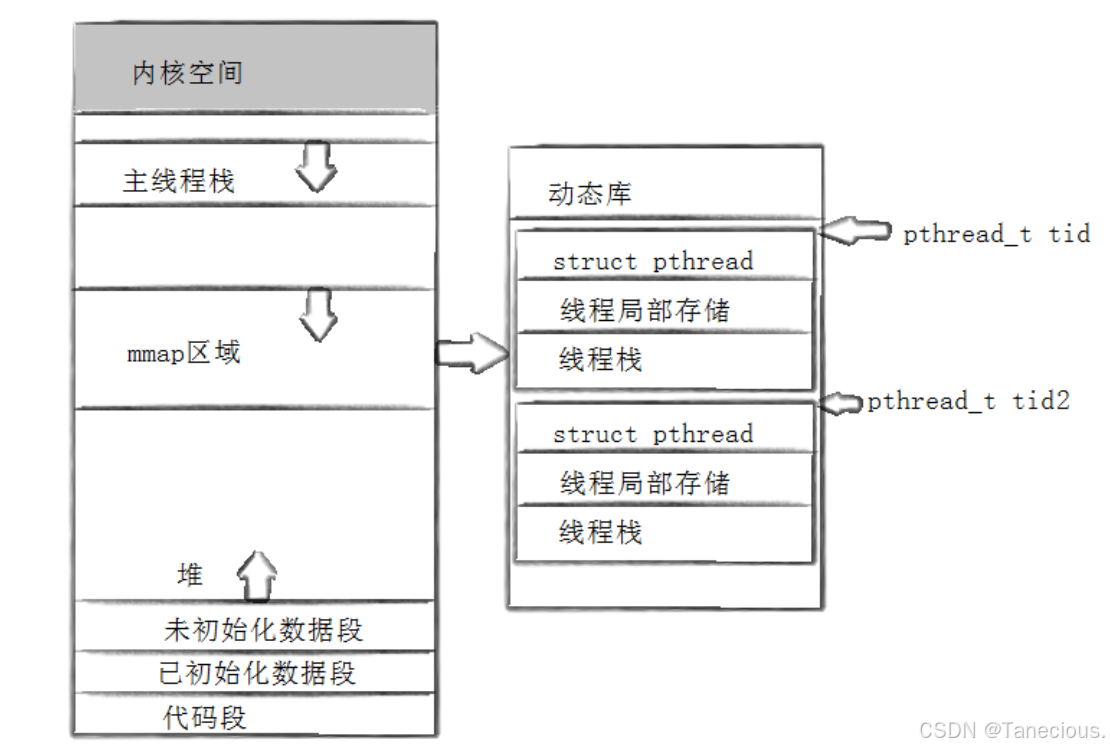
5.3 分配舞台:mmap()
Pthreads 库需要为每个线程分配一块相当大的内存,用于存放其 TCB、独立的栈等。对于这样的大块内存分配,库通常不使用 malloc(其底层对于大内存块的实现可能较慢或不灵活),而是使用一个更底层的系统调用:mmap()。
mmap(memory map)是一个功能强大的接口,其核心作用是将一个文件或者设备映射到进程的虚拟地址空间。但它有一个非常重要的特性,即匿名映射(Anonymous Mapping)。
- 匿名映射:通过在
mmap的参数中指定MAP_ANONYMOUS标志,我们可以让内核在进程的虚拟地址空间中凭空创建一块内存区域,这块区域不与任何磁盘文件关联。它就像一块“私有的、按需分配的”虚拟内存,非常适合用来作为线程的私有栈和管理区域。
// mmap的基本原型
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
// Pthreads库在内部可能像这样使用它来申请线程空间
// PROT_READ | PROT_WRITE: 内存可读可写
// MAP_PRIVATE | MAP_ANONYMOUS: 私有的、匿名的映射
// -1, 0: 因为是匿名的,所以不需要文件描述符和偏移量
thread_memory_block = mmap(NULL, THREAD_STACK_SIZE, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
Pthreads 库通过 mmap 的匿名映射功能,为每个新创建的线程在进程的虚拟地址空间中(通常在堆和栈之间的内存映射区)开辟了一块专属的、连续的内存区域。
5.4 探究三个秘密
5.4.1 线程ID (pthread_t) 的真面目
现在可以揭晓第一个秘密了。pthread_create 通过第一个参数返回的那个巨大的、看起来像随机数的线程ID ( pthread_t ),其本质就是上一步中通过 mmap 申请的那块内存区域的起始虚拟地址。
结论:线程ID就是一个虚拟地址。它指向Pthreads库为该线程所维护的管理数据结构的起点。
这块内存区域通常包含:
- TCB (Thread Control Block):存放线程的用户态属性。
- Stack:该线程专属的、独立的栈空间。
- TLS (Thread Local Storage):线程局部存储区。
- 其他管理信息…
最精妙的地方在于它如何将用户态的 TCB 与内核态的 LWP 关联起来。当库调用 clone() 系统调用时,它会向内核传递两个至关重要的参数:
- 要执行的函数:即用户传给
pthread_create的start_routine函数指针。 - 要使用的栈:即刚刚在用户态通过
mmap申请的那块线程栈内存区域的地址。
这样,内核创建 LWP 后,就知道当这个 LWP 被调度执行时,应该去执行哪个用户函数,并且应该使用哪个用户态的栈来保存其函数调用信息和局部变量。
一个生动的比喻:
这就像你在宿舍里点外卖。
- 你 (主线程):不想下楼,于是决定创建一个“任务”。你在脑子里(用户态TCB)记下了:要点什么(任务函数)、谁去拿(LWP)、预期结果(返回值)等信息。
- 外卖小哥 (L/内核):他负责实际的执行工作(排队、取餐、上楼)。他不需要知道你点餐的全部心路历程,他只需要知道去哪家店取什么餐 (
start_routine),以及把餐送到哪个宿舍 (stack)。- 联动:你通过App(
pthread_create/clone)把任务派发给小哥。小哥在楼下执行,而你在楼上维护着这个任务的“元数据”。任务完成后,小哥把外卖(返回值)送回你的宿舍(TCB),你查收即可。
5.4.2 线程返回值是如何传递的?
当一个线程执行 return value; 或 pthread_exitalue); 时,Pthreads 库的内部代码会将 value 这个值,写入到该线程对应的TCB中的一个特定字段(例如 void* retval;)。
当主线程调用 pthread_join(tid, &ret); 时,库会:
- 使用
tid(也就是那块管理区域的起始地址)找到对应的TCB。 - 从TCB的
retval字段中,读取之前存入的那个值。 - 将这个值写入
ret所指向的内存中(这就是为什么需要二级级指针)。
最后,库会 munmap 这整块线程管理区域的内存,完成资源回收。
5.4.3 线程 (pthread_detach) 的本质是什么?
在线程的TCB中,有一个状态标志位,例如 bool is_joinle;,默认值为 true。
当用户调用 pthread_detach(tid);,库只是简单地找到对应的TCB,并将这个标志位设置为 false。
当这个分离的线程终止时,内核中的LWP被销毁。Pthreads库会得到通知,它检查该线程TCB中的 is_joinable 标志。发现是 false 后,它就不会保留TCB等待join,而是立即自己回收(munmap)这块线程管理区域的内存。

















 3403
3403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









