




SCRATCHING VISUAL TRANSFORMER’S BACK WITH UNIFORM ATTENTION 一行代码提升transformer性能
总体概览:本文发现VIT 受益于密集的交互作用,并提出了一种轻量级模块(一行代码),以明确地将密集交互作用注入 VIT。
Why
多头自注意力通过全局操作建模长程依赖,CNN则是通过逐步堆叠局部操作来扩大交互范围。
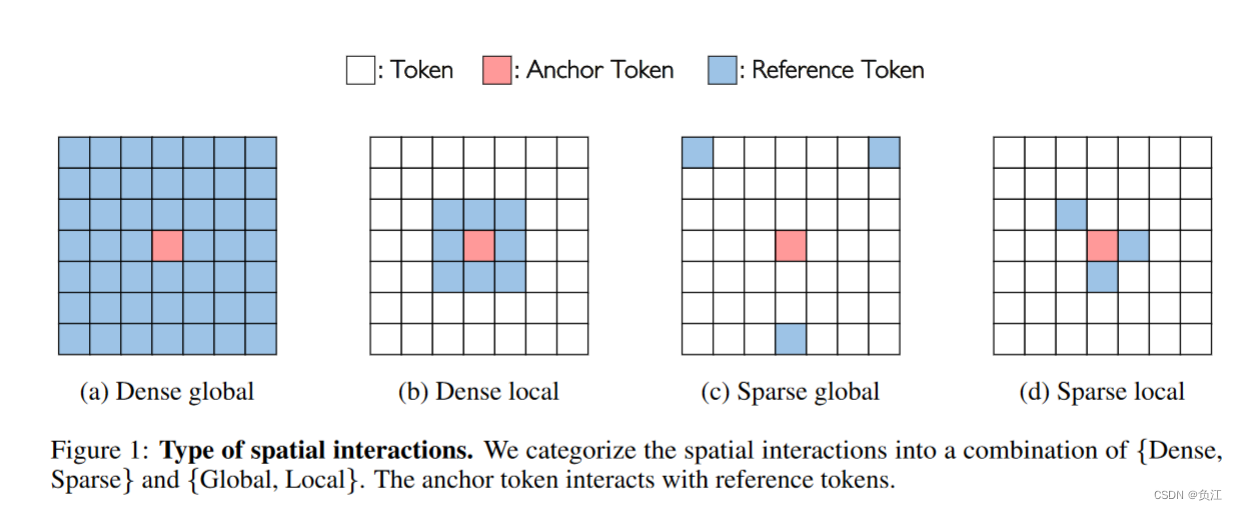
长程依赖性或全局交互作用指的是到达与参考标记相距较远位置的连接。密度指的是所有标记中非零交互的比例。
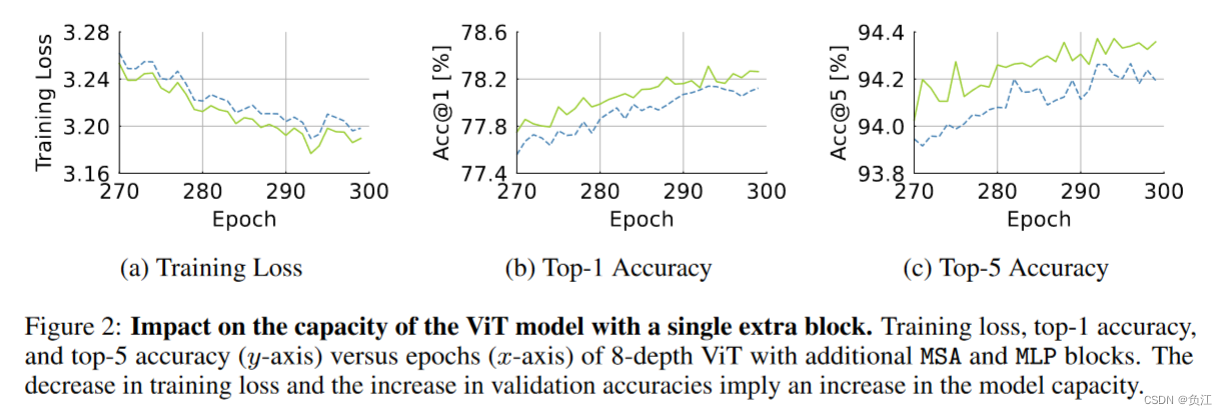
发现ViTs还需要更多的密集交互:在 ImageNet-1K 上对八层 ViT 进行了 300 次历时训练,并在最后一层插入了额外的 MSA 或 MLP 层。增加的参数数和 FLOP 几乎相等。发现增加MSA得到的效果增加更多。
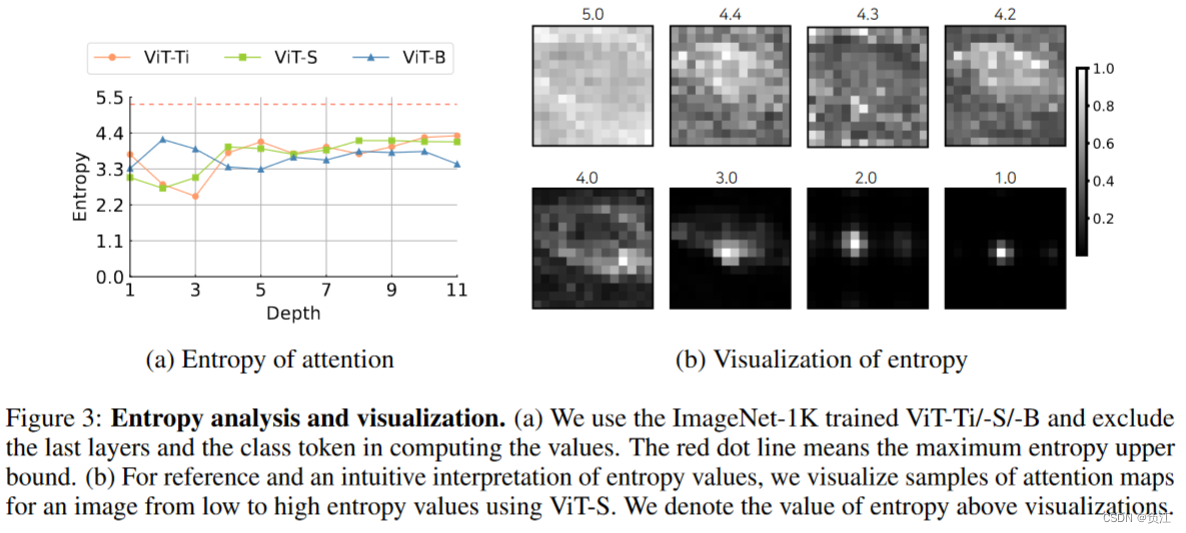
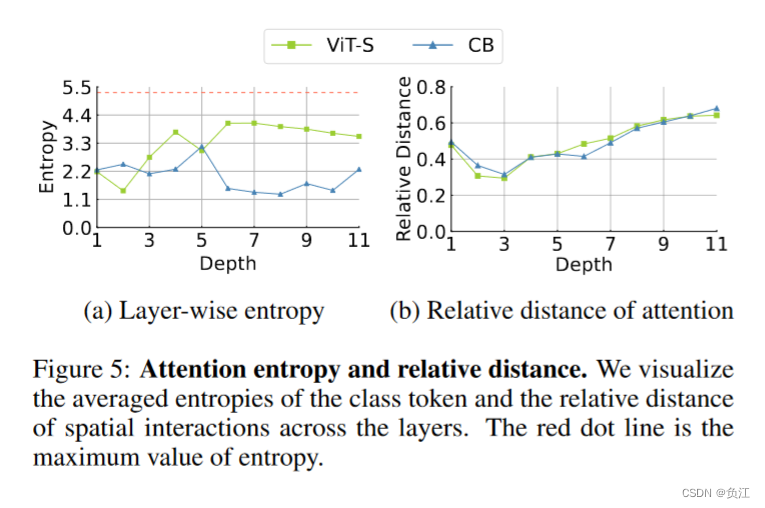
MSA需要那种类型的空间交互:根据注意力矩阵的熵值来判断注意力的密集程度。左图显示ViT的熵值都很高,而右图显示了熵值和注意力矩阵的权重的关系,很明显看到熵值越高,权重越大,操作也就越密集。
均匀分布的注意力矩阵的梯度:熵最大的情况是均匀分布,这时候操作更密集。通过对softmax在均匀情况下的分析,发现这时候的梯度很不稳定。
结论:
- 进一步的空间连接比进一步的通道互动更有利于 ViT 模型。
- MSA 层倾向于学习熵值更高的密集交互。
- 然而注意力图越密集,MSA 层的梯度就越陡峭,训练就越难。
也就是说密集的注意图很难学习,但似乎对 ViT 至关重要。
What
既然均匀分布的注意力很难学,但是又很重要,那么直接手动给它增加一次统一注意力:
Context Broadcasting(CB)
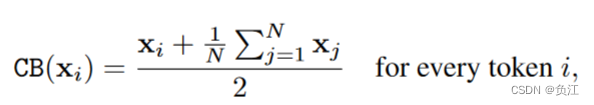
也就是为X中每个元素加上均值后除2。
将CB插入在注意力中
1)将多头自我注意中的一个头替换为 CB(记为 Replc.),从而减少被替换头对应的参数数;
2)调整 Replc.方法的参数数,使其与原始 ViT 的参数数相当(记为 Comp.);
3)将 CB 作为额外的头并行附加到多头自我注意中(记为 Att.)。

维度缩放
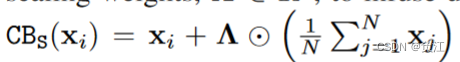
给每个通道选择一个权重。
How
将CB插入在ViT的哪个位置

插入在MLP中更好,MLP中插入在两个FC中间或第二个FC后比较好。
在分割上的性能
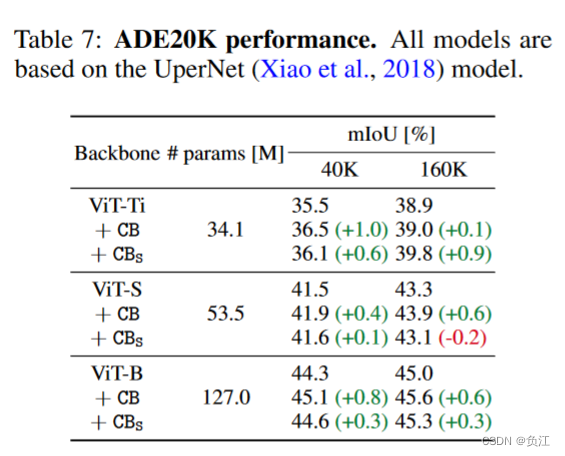
CB是否能减轻注意力密集操作的压力?

















 1011
1011



 到【灌水乐园】发言
到【灌水乐园】发言







