



 本文介绍了IBM的CAPI技术,旨在改善FPGA与现有系统的融合。首先阐述了通用CPU(GPCPU)的运算方式,强调其在协调工作而非大量运算中的角色。接着讲解了FPGA的专用计算原理和如何通过PCIE与系统对接。讨论了多核心CPU系统中的Cache Coherency问题以及PCIE设备如何与CPU交互。文章指出当前交互方式的不足,并介绍CAPI1.0如何解决这些问题,包括AFU、PSL和CAPP的作用。最后探讨了CAPI1.0的性能提升以及未来可能的发展方向。
本文介绍了IBM的CAPI技术,旨在改善FPGA与现有系统的融合。首先阐述了通用CPU(GPCPU)的运算方式,强调其在协调工作而非大量运算中的角色。接着讲解了FPGA的专用计算原理和如何通过PCIE与系统对接。讨论了多核心CPU系统中的Cache Coherency问题以及PCIE设备如何与CPU交互。文章指出当前交互方式的不足,并介绍CAPI1.0如何解决这些问题,包括AFU、PSL和CAPP的作用。最后探讨了CAPI1.0的性能提升以及未来可能的发展方向。
冬瓜哥和存储界的朋友们有个无声的约定,那就是,想知道产品 / 技术背后的奥秘,了解底层,剥掉厂商包装忽悠的外壳,那关注冬瓜哥是没错的,底层通,一通百通,逼格秒涨!冬瓜哥没有太多精力和兴趣去搜罗业界八卦并分析,聊八卦一向不是冬瓜哥的强项,虽然属于 MKT 的角色,但是身在曹营心在汉,你和咱说市场,咱就和你论技术,忽悠死你,哈哈 ~~ 。冬瓜哥认为,底层技术是终生受用的武器,冬瓜哥看任何产品或者说 “ 事物 ” ,都要看透其底层才可罢休,否则冬瓜哥会感觉很不爽。
闲话少说,今天我们说一说 IBM 搞的 CAPI , CAPI 是 OpenPower 体系里的一个技术,其目的是让 FPGA 更好更方便的融入现有的系统。那么现有的 FPGA 是怎么被使用的呢?不如先说说什么是 FPGA ,要弄清楚什么是 FPGA ,就得先说说什么是 CPU 。可笑, CPU 大家都知道,冬瓜哥这逼格咋降低了?笑而不语。
· 通用 CPU 是怎么运算的?
我们都知道所谓 GPCPU (通用目的 CPU ),也就是什么都能算,但又什么都算不快的 CPU ,所以其 “ 通用 ” ,比如 Intel x86 , AMD x86 , Power , PowerPC , MIPS , ARM , DragonSon/GodSon (国产)等。而 FPGA 就是专门为了某种某类计算而专门优化其内部的逻辑电路的一种专用 CPU 。 GPCPU 内部的 ALU 包含多种运算器比如加减乘除以及逻辑(比如 xor , and , or , not )运算以及整数和浮点运算,我们开始菜单计算器,算加减法,代码指令便会把对应的数据导入到 CPU 的寄存器, CPU 收到之后便会将操作数输入到运算器的输入端,并在下一个时钟周期获取到计算结果并输出到寄存器,然后写回到主存。当然, GPCPU 内部花费了大量的资源(逻辑电路)去做优化,包括缓存管理、流水线、多发射、分支预测、乱序执行等等,一条指令要最终得到执行,都要经过这些关卡的一层层处理,所以,对于那些遵纪守法的代码(比如,顺着来没有任何判断跳转)来讲其时延无疑会增加,但是目前随着业务越来越复杂,应用程序的判断条件越来越多,所以这些优化会增加最终性能,虽然时延相对上提高了,但是性能绝对上是增加了,因为如果误判了一个分支,那么整个流水线已经预读入的代码就会被冲刷走重新读入,这个时延反而会更大。
有人问了,我不打开计算器,就运行个 QQ ,难道还要算加减法么?如果没有什么加减乘除运算, CPU 运行 QQ 到底是运行了些什么东西?这问题问得好,问的逼格高,一般人是根本不去想 QQ 运行时候底层都做了什么的。其实 GPCPU 大多时候还真没有在算加减乘除,而更多地是做协调工作了,也就是把内存里某段数据读出来,稍加改动或者根本不动,又写到内存其他地方去。这不闲的么, CPU 就干这个?是的。比如 QQ 要发送一句话给某个好友,其需要调用 TCP 协议栈顶上的 soket API ,后者就是一段常驻内存的 OS 内核代码,那么 QQ.exe 如何将这句话传递给这段代码? QQ.exe 会让 CPU 把这句话在当前内存的地址告诉 socket API 代码,其会将这个地址以及其他参数写入到某个 CPU 寄存器,对应机器指令就是 “mov 内存地址寄存器 A” 类似这种,然后 QQ.exe 调用 socket API ,对应机器指令就是 “call socket API 的内存地址 ” , CPU 就会把 QQ.exe 当前的地址暂存起来以便后续返回继续执行(这叫压栈),然后再跳转到 socket API 地址来执行 socket 代码(从内存中该地址读出 socket 代码执行), socket 代码执行之后,会在 CPU 寄存器内发现之前传递过来的参数(要发送数据的内容等),然后按照这个参数向下调用 TCP 协议栈将数据打包,分段,贴上 IP 标签,最后调用以太网卡驱动程序,调用过程与上述类似,然后发送到网卡。这个过程,在主路径上,加减乘除运算并不是必须的,但是在辅路径上,比如程序需要记住当前发送了多少内容了, TCP 协议栈也要记录当前发送了多少个分段了,这些就需要 CPU 做加法操作,来计数;另外,在遇到 if 代码的时候, cpu 会比对多个输入条件,对应机器指令是 comp (比较)以及 jmpz/jmpnz (遇零跳转 / 非零跳转)等此时会用到减法器或者比较器,这恐怕是通用场景下用得最多的 ALU 运算器了。所以,上述这个过程,根本就不是一个大运算量的过程。但是你如果去听 mp3 ,解码 RMVB 电影,那就需要大运算量了,这些场景也是专用场景。
· 专用 FPGA 又是怎么计算的?
通用 CPU 做通用场景的代码执行,很强,什么都能干,听着歌聊着 QQ 做着 ppt ,再加上个 SSD ,体验流畅的感觉。但是让你算一算分子动力学,某个分子内的原子是怎么运动的?算一算人脸识别?搞搞搜索?那通用 CPU 就歇菜了。此时,加减乘除、逻辑、整数、浮点统统一起上,通用场景下使用比例较少的这些 ALU ,但是专用场景下,这些 ALU 反而不够用了,一个是数量太少,一个是位宽太低。比如 XOR 运算器,如果位宽只有 64bit ,每个时钟周期只能将两个 64bit 做 XOR ,如果我要 XOR 两份 1GB 的数据,就需要 1GB/64bit=? (自己算)个时钟周期,才能算完。此时,专用计算就派上用场了,也就是所谓的 “ 硬加速 ” 。总体来讲硬加速有 4 种实现手段:露点、加宽、并行、直译。露,就是直接把最终的运算单元给露出来,抛掉那些什么分支预测等流水线步骤;宽,就是把运算器位宽直接加大,一个周期多算一些数据;并就是把多种分支直接并行检测,也就是把比较器 / 减法器直接并行化,结果相 OR 或者 AND ,来判断后续路径;直译就是把多种条件直接用译码器做出来,一个周期输出结果。所有这些都需要电路层面的改动,这就产生了 FPGA 现场可编程门电路阵列。 FGPA 内部就是一堆的直译表( DRAM ,用户自己写好逻辑然后输入进去),再加上一些外围接口,和一些固定的算法器件比如 Flash 控制器常用的 LDPC 硬核。 NIC 、存储 IO 卡、防火墙、路由器等,内部都使用了应加速,比如网卡收到一个以太网帧,其需要解析帧头,这种工作如果交给 GPCPU 的话,那就太慢了,来,先从内存读入代码看看要让爷我干点啥?译完了码,来,进流水线等着吧,我顺便去做个分支预判,找一找历史预判数据,下一位!进了流水线后,亲,你先排在后面吧因为你要的资源和别人有冲突。最后操作数到达 ALU ,尼玛,就这么点位宽?小爷这吨位起码得 1Mbit 位宽才放得下!亲,下次再来吧,来之前先进闸刀给你闸成多个 64bit ,然后每次算 64bit 吧。。而硬加速直接把这个帧载入寄存器,其中电路直接导向各个译码器,直译出下一步的操作,比如需要比对 ALC ,那么就多个目标地址 / 源地址并行比较一个周期输出,这样才能保证速度。
· 专用 FPGA 怎么与系统对接?
目前的 FPGA 都是使用 PCIE 与 host 通信的,也就是做成一张 PCIE 卡查到主板 PCIE 槽上。主程序通过驱动程序,将需要运算的数据指针告诉 FPGA ,然后 FPGA 从主存 DMA 读取待计算数据然后计算,算完后 DMA 回主存并通知主程序。
· 多核心多 CPU 系统以及 PCIE 设备

所有 CPU 看到单一物理地址空间,所有 Threads 看到单一虚拟地址空间, PCIE 物理地址空间映射到 CPU 物理地址空间, CPU 物理地址空间也映射到 PCIE 物理地址空间。

数据出了 ALU ,面对的一张复杂的路由网络,目的地址为内存地址,但是其相对外部网络的复杂性在于,目标的位置是不固定的,还可能有多份拷贝。 Need Coherency !硬件透明搞定 Cache Coherency 。 CC 不负责多线程并发访问 cache line 时的互斥,互斥需要程序显式发出 lock ,底层硬件会锁住总线访问周期。
· PCIE 设备如何与 CPU 交互?
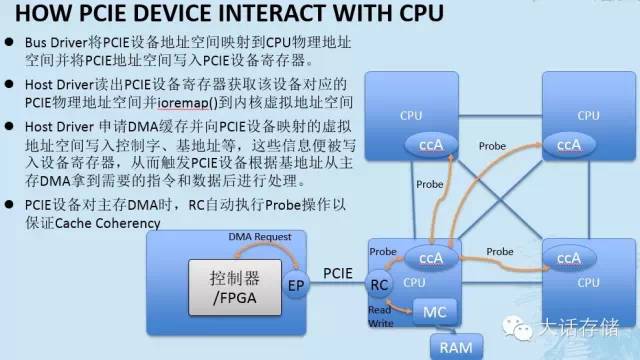
1. BusDriver 将 PCIE 设备地址空间映射到 CPU 物理地址空间并将 PCIE 地址空间写入 PCIE 设备寄存器。
2. HostDriver 读出 PCIE 设备寄存器获取该设备对应的 PCIE 物理地址空间并 ioremap() 到内核虚拟地址空间
3. HostDriver 申请 DMA 缓存并向 PCIE 设备映射的虚拟地址空间写入控制字、基地址等,这些信息便被写入设备寄存器,从而触发 PCIE 设备根据基地址从主存 DMA 拿到需要的指令和数据后进行处理。
4. PCIE 设备对主存 DMA 时, RC 自动执行 Probe 操作以保证 CacheCoherency
· 当前交互方式存在的不足
1. 执行路径长而且全软件参与:应用 call-> 传输协议栈(如有) ->Host 驱动 ->PCIE 设备 ->DMAà 中断服务 ->Host 驱动 -> 传输协议栈(如有) -> 应用 buffer
2. PCIE 设备与 CPU 看到不同的物理地址空间, RC 进行映射和转换。驱动程序申请内存之后得用 pci_map_single() 映射成 PCIE 物理地址。
3. 用户态程序必须主动从内核地址空间 mmap() 才可以直接与 PCIE 设备 DMA 互传数据。用户态程序必须区分不同的地址段。
· CAPI1.0 版本如何解决当前的问题?
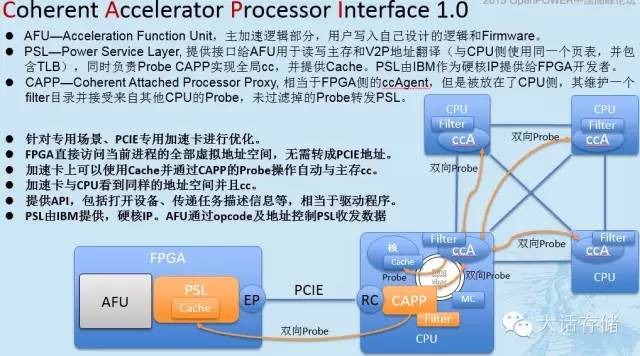
AFU —Acceleration Function Unit ,主加速逻辑部分,用户写入自己设计的逻辑和 Firmware 。
PSL —Power Service Layer, 提供接口给 AFU 用于读写主存和 V2P 地址翻译(与 CPU 侧使用同一个页表,并包含 TLB ),同时负责 Probe CAPP 实现全局 cc ,并提供 Cache 。 PSL 由 IBM 作为硬核 IP 提供给 FPGA 开发者。
CAPP —Coherent Attached Processor Proxy, 相当于 FPGA 侧的 ccAgent ,但是被放在了 CPU 侧,其维护一个 filter 目录并接受来自其他 CPU 的 Probe ,未过滤掉的 Probe 转发 PSL 。
· 性能能提高多少?
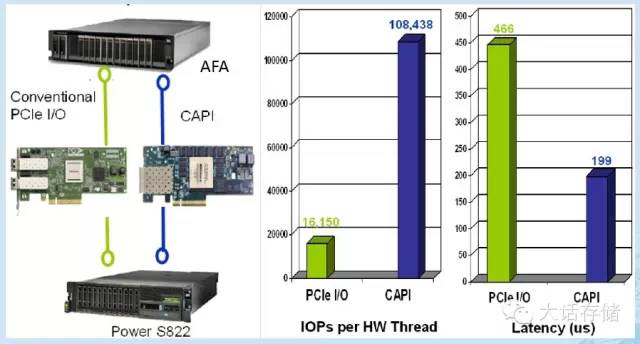
上图是 IBM 自己的一个测试,利用 CAPI enabled FC HBA (基于 FGPA ),与传统方式相对比,性能提升非常大,我没有是测过,对其底层的机制有点怀疑, FPGA 后端同样使用传统的 FC 控制器以及驱动程序连接 AFA 阵列,这与直接把 FC 卡插在主机上相比,增加了一层 CAPI ,只会时延更高,但是结果却是时延下降,由于 IBM 并没有提供更多信息,所以这里不好判断。
· CAPI1.0 暂时做不到的事情, Maybe in future

o CPU 侧看不到 AFU 上的地址空间 (MMIO 控制寄存器地址除外 ) 。
o AFU 只能给一个进程使用:进程 Open AFU 之后便独占之。
o 如果可以把 FPGA 直接接入 CPU 的 FSB ,是不是会更快? Maybe in future 。
本次分享就到这里,敬请期待下次分享。只出精品,这是冬瓜哥的原则。谢谢大家,如果觉得好,来点小费冬瓜哥也是不介意的!冬瓜哥会更有动力为大家分享更多干货!微信支付扫码打赏冬瓜哥:)
关注“大话存储”公众号,获取最前沿最底层最通俗的存储技术更新,提升逼格!



















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









