



 本文详细描述了如何在Linux环境中安装JDK,设置JAVA环境变量,实现SSH免密登录,以及配置和安装Hadoop和Spark伪分布式环境,还包括Scala的配置过程。
本文详细描述了如何在Linux环境中安装JDK,设置JAVA环境变量,实现SSH免密登录,以及配置和安装Hadoop和Spark伪分布式环境,还包括Scala的配置过程。
步骤一:安装 JDK
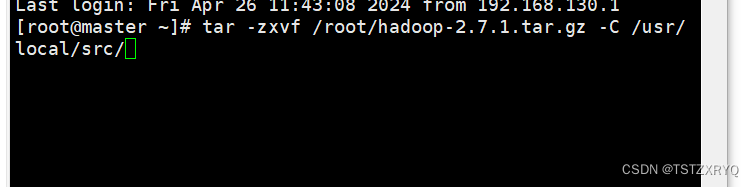
安装命令如下,将安装包解压到/usr/local/src/目录下
[root@master ~]# tar -zxvf /root/hadoop-2.7.1.tar.gz -C /usr/local/src/
[root@master ~]# ls /usr/local/src/

步骤二:设置 JAVA 环境变量
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin

执行 source 使设置生效:
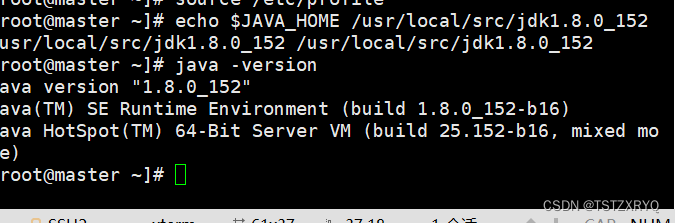
[root@master ~]# source /etc/profile
检查 JAVA 是否可用。
[root@master ~]# echo $JAVA_HOME /usr/local/src/jdk1.8.0_152
[root@master ~]# java -version
实现免密登陆
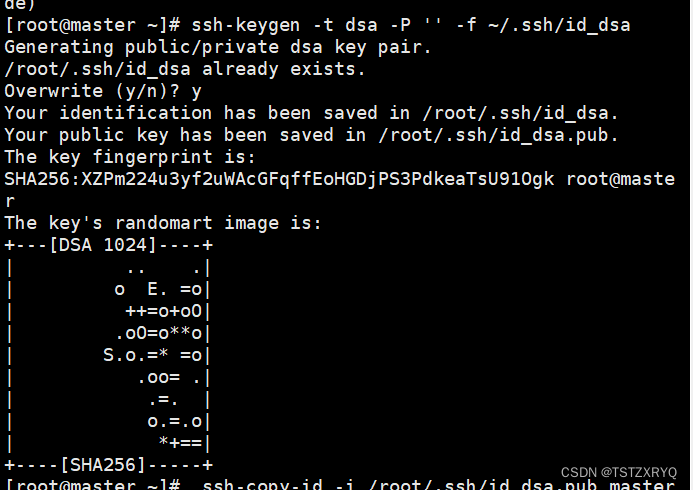
步骤一:创建ssh秘钥,输入如下命令,生成公私密钥
[root@master ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
步骤二:将master公钥id_dsa复制到master进行公钥认证,实现本机免密登陆,测试完exit退出
[root@master ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub master
[root@master ~]# ssh master
[root@master ~]# exit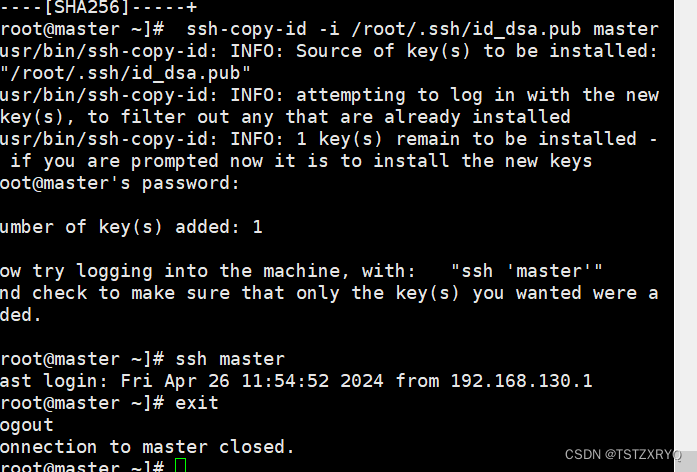
环境的安装与配置
步骤一:将/root/runajian下的hadoop-2.7.7.tar.gz压缩包解压到/usr/local/stof/目录下,并将解压文件改名为hadoop
步骤二:修改环境变量
[root@master ~]# vim /etc/profile
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@master ~]# source /etc/profile 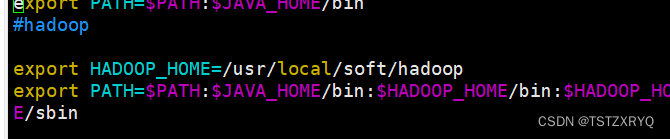
步骤三:编辑/usr/local/soft/hadoop/etc/hadoop/hadoop-env.sh文件
[root@master ~]# vi /usr/local/soft/hadoop/etc/hadoop/hadoop-env.sh
修改配置文件为jdk的安装路径:
export JAVA_HOME=/usr/local/soft/jdk1.8.0_152

步骤四:编辑/usr/local/soft/hadoop/etc/hadoop/core-site.xml文件
[root@master ~]# vi /usr/local/soft/hadoop/etc/hadoop/core-site.xml
修改配置文件为:
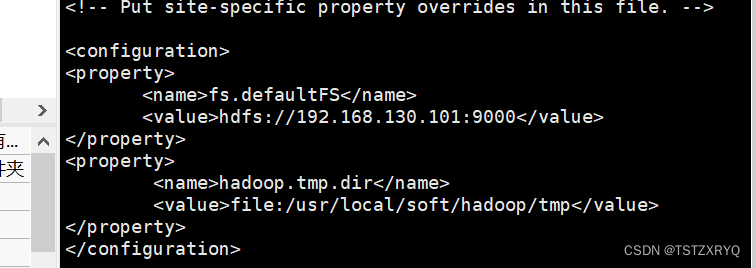
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>
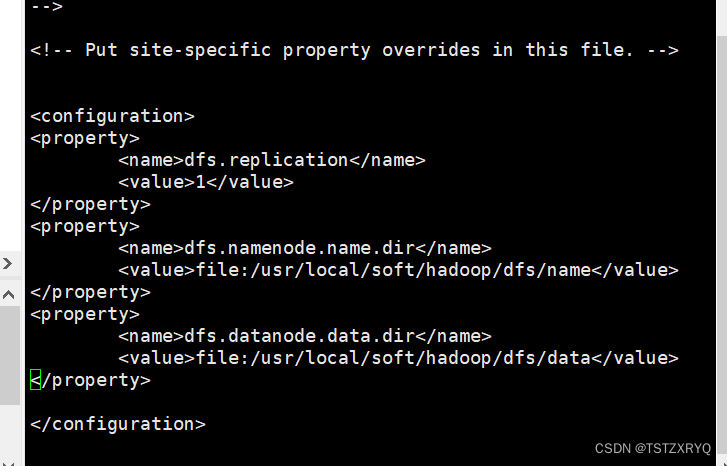
步骤五:编辑/usr/local/soft/hadoop/etc/hadoop/hdfs-site.xml文件
[root@master ~]# cd /urs/local/soft/hadoop/etc/hadoop
[root@master ~]# vi hdfs-site.xml
修改配置文件:
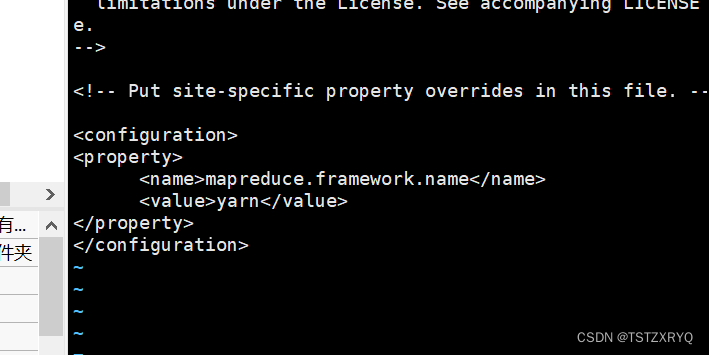
步骤六:编辑/usr/local/soft/hadoop/etc/hadoop/mapred-site.xml文件
[root@master ~]# cd /urs/local/soft/hadoop/etc/hadoop
[root@master ~]# vi mapred-site.xml
 步骤七:编辑/usr/local/soft/hadoop/etc/hadoop/yarn-site.文件
步骤七:编辑/usr/local/soft/hadoop/etc/hadoop/yarn-site.文件
[root@master hadoop]# vi yarn-site.xml
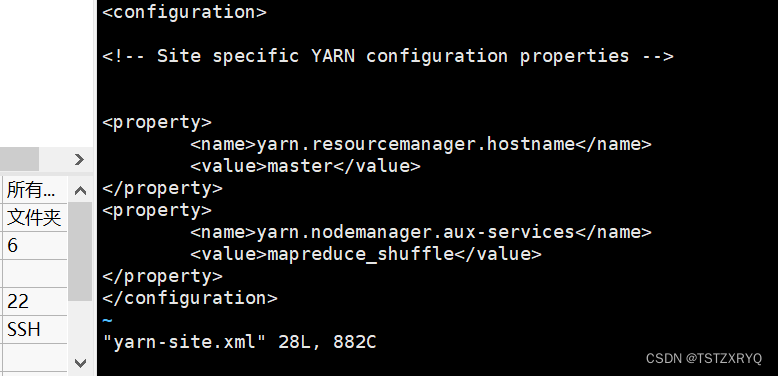
步骤八:编辑/usr/local/soft/hadoop/etc/hadoop/slaves文件
[root@master hadoop]# vi slaves
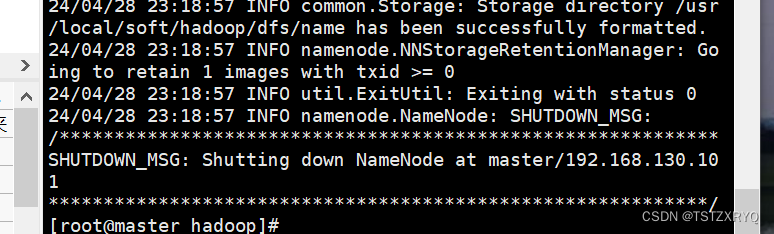
步骤九: 格式化hdfs
[root@master ~]# hdfs namenode -format
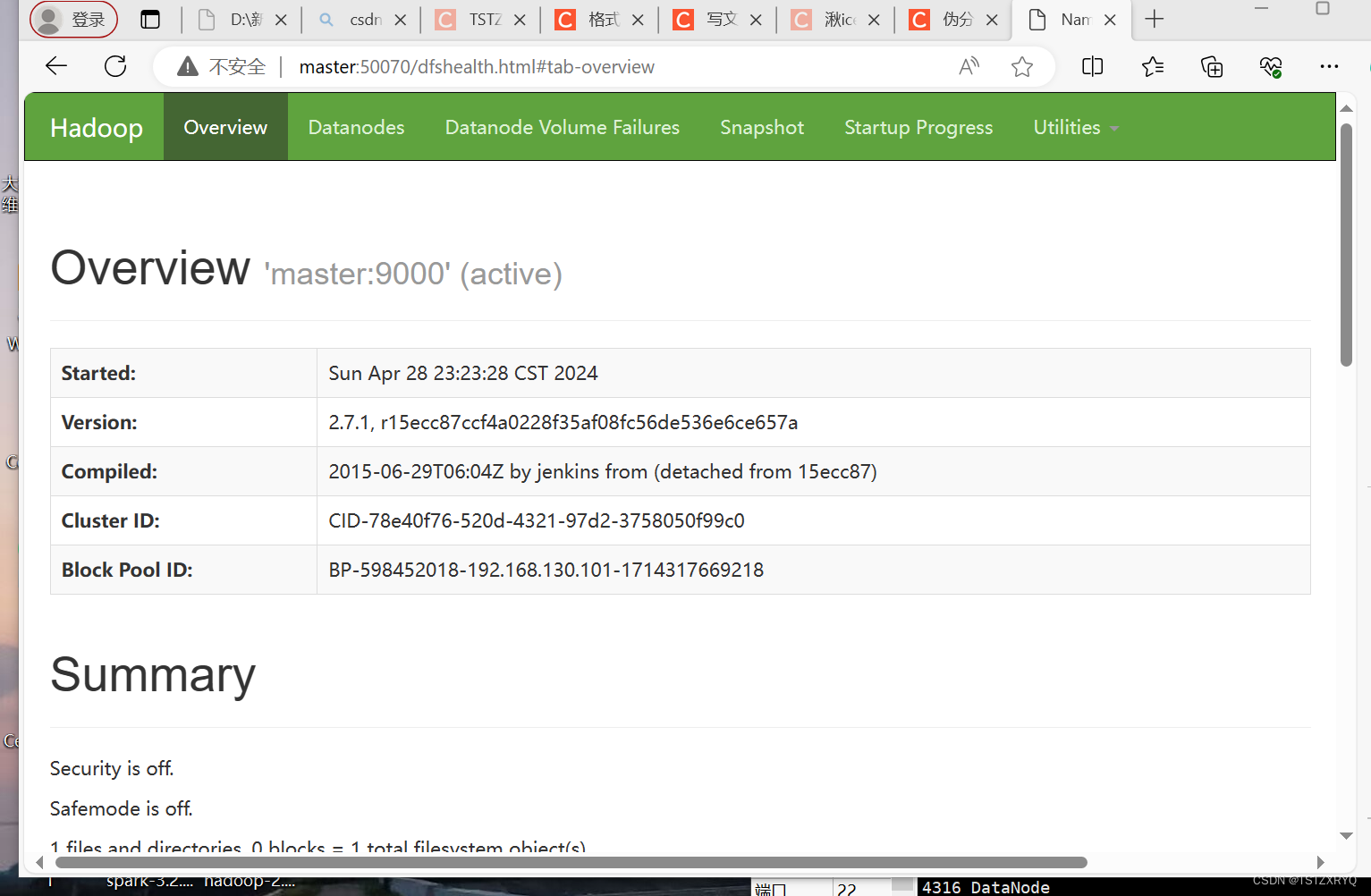
步骤十:启动集群 jps查看,登录网页
[root@master ~]# start-all.sh
[root@master ~]# jps
在浏览器的地址栏输入http://master:50070,进入页面可以查看NameNode和DataNode 信息
安装伪分布式spark
步骤一:安装命令如下
[root@master ~]# tar -zxf spark-3.2.1-bin-hadoop2.7.tgz -C /usr/local/soft/![]()
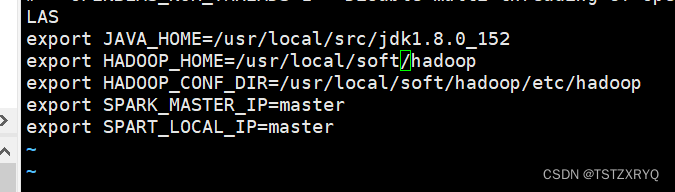
步骤二:复制和重命名后得到spark-env.sh,打开spark-env.sh添加内容
[root@master ~]# cd /usr/local/soft/spark-3.2.1-bin-hadoop2.7/conf/
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
[root@master conf]#
步骤三:进入spark目录的/sbin下启动spark集群,jps查看
[root@master conf]# cd /usr/local/soft/spark-3.2.1-bin-hadoop2.7/sbin/
[root@master sbin]# ./start-all.sh
[root@master sbin]# jps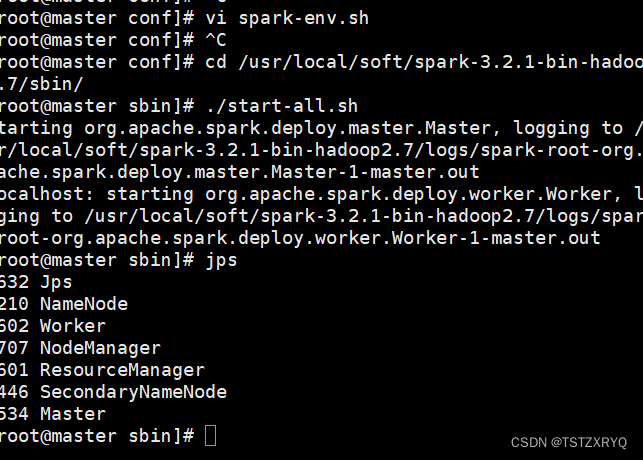 步步
步步
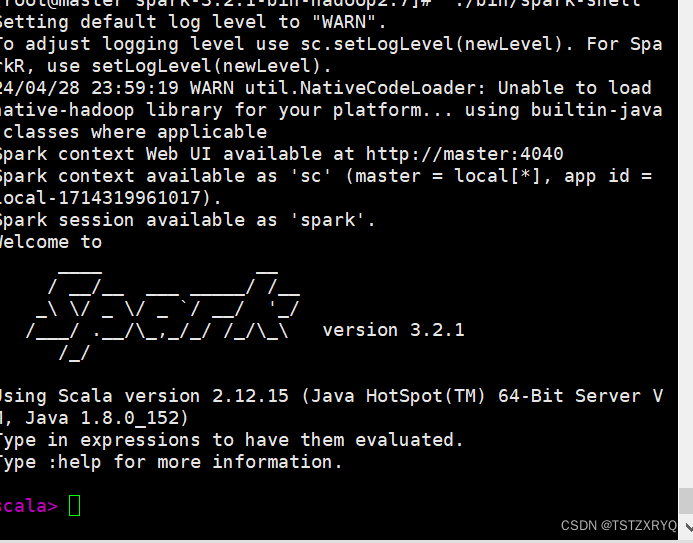
步骤四:启动spark-ahell
[root@master ~]# cd /usr/local/soft/spark-3.2.1-bin-hadoop2.7/
[root@master spark-3.2.1-bin-hadoop2.7]# ./bin/spark-shell
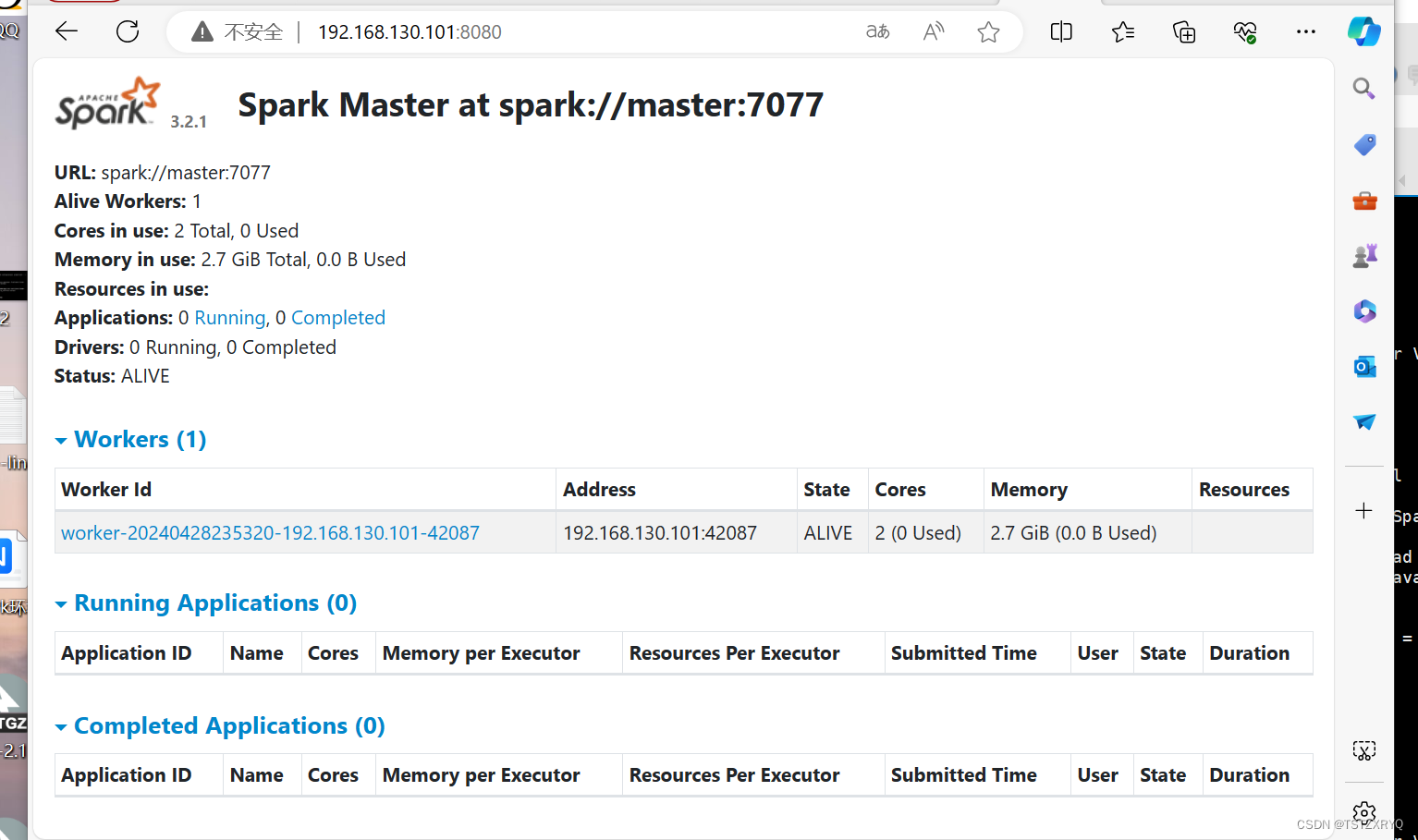
 步骤五:浏览器搜索192.168.130.101:8080
步骤五:浏览器搜索192.168.130.101:8080
安装伪分布式scala
步骤一:安装命令如下

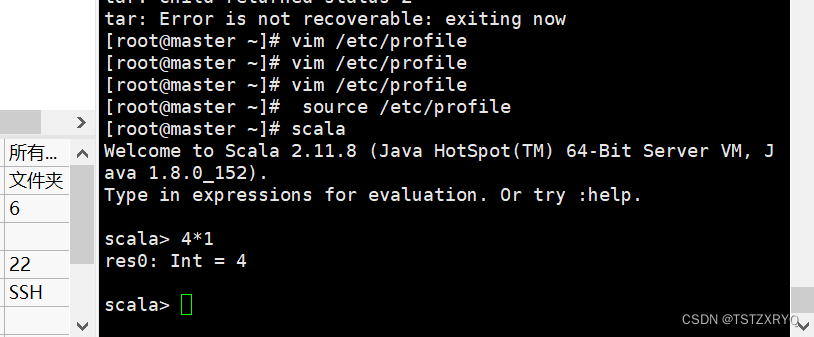
步骤二:配置scala环境变量,重新加载配置文件,运行scala
[root@master ~]# vim /etc/profile
[root@master ~]# source /etc/profile
[root@master ~]# scala


















 2332
2332





 到【灌水乐园】发言
到【灌水乐园】发言







