




 本文深入探讨无监督学习中的聚类技术,介绍聚类的基本原理、数学描述、性能度量,以及k均值算法、高斯混合聚类、密度聚类DBSCAN和层次聚类的算法原理和实现步骤。
本文深入探讨无监督学习中的聚类技术,介绍聚类的基本原理、数学描述、性能度量,以及k均值算法、高斯混合聚类、密度聚类DBSCAN和层次聚类的算法原理和实现步骤。
简介
在无监督学习中unsupervised learning中,训练样本的标记信息是未知的,其目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。而此类学习任务中应用最广、研究最多的即聚类clustering。
以通俗的语言讲解,聚类学习将数据集中的样本分成若干个互不相交的子集(称为簇cluster)。保持簇内差异尽可能小而簇间差异尽可能大我们就可以将每个簇映射到一些潜在的类别。
需要注意的是,划分的类别对于聚类而言事先是位置的,聚类过程仅能将数据集自动划分为不同的簇,但每个簇对应的概念语义是需要使用者自己来把握和命名。
数学描述
照旧我们以数学语言描述聚类学习,假定样本集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D = \{x_1, x_2, ..., x_m\}
D={x1,x2,...,xm}包含
m
m
m个无标记样本,每个样本
x
i
=
(
x
i
1
;
x
i
2
;
.
.
.
;
x
i
m
)
x_i = (x_{i1};x_{i2};...;x_{im})
xi=(xi1;xi2;...;xim)是一个
n
n
n维特征向量,则聚类算法将样本
D
D
D划分为
k
k
k个不相交的簇
{
C
l
∣
l
=
1
,
2
,
.
.
.
,
k
}
\{C_l | l=1,2,...,k\}
{Cl∣l=1,2,...,k}。我们用
λ
j
∈
1
,
2
,
.
.
.
,
k
\lambda_j\in{1,2,...,k}
λj∈1,2,...,k表示样本
x
j
x_j
xj的簇标记cluster label,则聚类结果可用包含
m
m
m个元素的簇标记向量
λ
=
(
λ
1
;
λ
2
;
.
.
.
;
λ
m
)
\lambda=(\lambda_1;\lambda_2;...;\lambda_m)
λ=(λ1;λ2;...;λm)表示。
性能度量
从本质上讲,我们希望聚类形成簇内方差尽可能小而簇间方差尽可能大的分类结果,即相同类别的元素尽可能相似而归属不同类别的元素尽可能不同。
对数据集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm},假定通过聚类给出的簇划分为 C = { C 1 , C 2 , . . . , C k } C=\{C_1,C_2,...,C_k\} C={C1,C2,...,Ck},定义:
a
v
g
(
C
)
=
2
∣
C
∣
(
∣
C
∣
−
1
)
)
∑
1
≤
i
<
j
≤
∣
C
∣
d
i
s
t
(
x
i
,
x
j
)
d
i
a
m
(
C
)
=
m
a
x
1
≤
i
<
j
≤
∣
C
∣
d
i
s
t
(
x
i
,
x
j
)
d
m
i
n
(
C
i
,
C
j
)
=
m
i
n
x
i
∈
C
i
,
x
j
∈
C
j
d
i
s
t
(
x
i
,
x
j
)
d
c
e
n
(
C
i
,
C
j
)
=
d
i
s
t
(
μ
i
,
μ
j
)
μ
=
1
∣
C
∣
∑
1
≤
i
≤
∣
C
∣
x
i
avg(C)=\frac{2}{|C|(|C|-1))}\sum_{1\leq i<j \leq |C|}dist(x_i, x_j) \\ diam(C)=max_{1 \leq i < j \leq |C|}dist(x_i, x_j) \\ d_{min}(C_i,C_j)=min_{x_i\in C_i, x_j\in C_j}dist(x_i, x_j) \\ d_{cen}(C_i,C_j) = dist(\mu_i, \mu_j) \\ \mu = \frac{1}{|C|}\sum_{1\leq i \leq |C|}x_i
avg(C)=∣C∣(∣C∣−1))21≤i<j≤∣C∣∑dist(xi,xj)diam(C)=max1≤i<j≤∣C∣dist(xi,xj)dmin(Ci,Cj)=minxi∈Ci,xj∈Cjdist(xi,xj)dcen(Ci,Cj)=dist(μi,μj)μ=∣C∣11≤i≤∣C∣∑xi
其中
d
i
s
t
(
x
i
,
x
j
)
dist(x_i, x_j)
dist(xi,xj)衡量两个样本之间的距离,
μ
\mu
μ表示簇
C
C
C的中心点,
a
v
g
(
C
)
avg(C)
avg(C)表示簇
C
C
C内样本间的平均距离,
d
i
a
m
(
C
)
diam(C)
diam(C)表示簇
C
C
C内样本间的最远距离,
d
m
i
n
(
C
i
,
C
j
)
d_{min}(C_i,C_j)
dmin(Ci,Cj)表示两个簇最近样本间的距离,
d
c
e
n
(
C
i
,
C
j
)
d_{cen}(C_i,C_j)
dcen(Ci,Cj)表示两个簇中心点间的距离。
基于这些指标,我们常用下面的聚类性能度量聚类效果:
- DB指数
Davies-Bouldin Index:值越小表示聚类效果越好
D B I = 1 k ∑ i = 1 k max j ≠ i ( a v g ( C i ) + a v g ( C j ) d c e n ( μ i , μ j ) ) DBI = \frac{1}{k}\sum_{i=1}^{k} \max_{j \neq i}(\frac{avg(C_i)+avg(C_j)}{d_{cen}(\mu_i,\mu_j)}) DBI=k1i=1∑kj=imax(dcen(μi,μj)avg(Ci)+avg(Cj)) - Dunn指数
Dunn Index:值越大表示聚类效果越好
D I = min 1 ≤ i ≤ k { min j ≠ i ( d m i n ( C i , C j ) m a x 1 ≤ l ≤ k d i a m ( C l ) ) } DI = \min_{1 \leq i \leq k}\{\min_{j\neq i}(\frac{d_{min}(C_i,C_j)}{max_{1 \leq l \leq k} diam(C_l)}) \} DI=1≤i≤kmin{j=imin(max1≤l≤kdiam(Cl)dmin(Ci,Cj))}
给定样本 x i = ( x i 1 ; x i 2 ; . . . ; x i n ) x_i=(x_{i1};x_{i2};...;x_{in}) xi=(xi1;xi2;...;xin)和 x j = ( x j 1 ; x j 2 ; . . . ; x j n ) x_j=(x_{j1};x_{j2};...;x_{jn}) xj=(xj1;xj2;...;xjn),度量两个样本点间距离 d i s t ( x i , x j ) dist(x_i, x_j) dist(xi,xj)的方法有很多种,最常用的就是“闵可夫斯基距离”Minkowski distance:
d i s t m k ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 p dist_{mk}(x_i,x_j) = (\sum_{u=1}{n}|x_{iu}-x_{ju}|^p)^{\frac{1}{p}} distmk(xi,xj)=(u=1∑n∣xiu−xju∣p)p1
当 p = 2 p=2 p=2时,闵可夫斯基距离等价于欧式距离
Euclidean distance; p = 1 p=1 p=1时,闵可夫斯基距离等价于曼哈顿距离Manhattan distance
k均值算法
给定样本集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\{x_1,x_2,...,x_m\}
D={x1,x2,...,xm},k-means最小化聚类所得簇划分
C
=
{
C
1
,
C
2
,
.
.
.
,
C
k
}
C=\{C_1,C_2,...,C_k\}
C={C1,C2,...,Ck}的平方误差:
E
=
∑
i
=
1
k
∑
x
∈
C
i
∣
∣
x
−
μ
i
∣
∣
2
2
E=\sum_{i=1}^{k}\sum_{x\in C_i}||x-\mu_i||_2^2
E=i=1∑kx∈Ci∑∣∣x−μi∣∣22
最小化上式需要遍历样本集
D
D
D中所有可能的簇划分,这本身就是一个NP难的问题,因此k-means算法采取了贪心策略,通过迭代优化来近似求解。
输入:样本集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\{x_1,x_2,...,x_m\}
D={x1,x2,...,xm},聚类簇数
k
k
k
输出:最优的簇划分
C
=
{
C
1
,
C
2
,
.
.
.
,
C
k
}
C=\{C_1,C_2,...,C_k\}
C={C1,C2,...,Ck}
- 从 D D D中随机抽取 k k k个样本作为初始均值向量 { μ 1 , μ 2 , . . . , μ k } \{\mu_1,\mu_2,...,\mu_k \} {μ1,μ2,...,μk}
- 遍历 D D D中的每个样本 x j x_j xj,计算它与各均值向量 μ i ( 1 ≤ i ≤ k ) \mu_i(1\leq i \leq k) μi(1≤i≤k)的距离: d j i = ∣ ∣ x j − μ i ∣ ∣ 2 d_{ji}=||x_j-\mu_i||_2 dji=∣∣xj−μi∣∣2,将样本划入离它最近的簇中: λ j = a r g m i n i ∈ 1 , 2 , . . . , k d j i \lambda_j = argmin_{i\in{1,2,...,k}}d_{ji} λj=argmini∈1,2,...,kdji,对应的簇更新为 C λ j = C λ j ∪ { x j } C_{\lambda_j}=C_{\lambda_j}\cup \{x_j\} Cλj=Cλj∪{xj}
- 对 k k k个簇重新计算均值向量: μ i ′ = 1 ∣ C i ∣ ∑ x ∈ C i x {\mu_i}'=\frac{1}{|C_i|}\sum_{x\in C_i}x μi′=∣Ci∣1∑x∈Cix,更新均值向量
- 重复1-3步骤直至均值向量不再更新
高斯混合聚类
1.多元高斯分布
先回顾以下多元高斯分布的概率密度函数:
p
(
x
)
=
1
(
2
π
)
n
2
∣
∑
∣
1
2
e
−
1
2
(
x
−
μ
)
T
∑
−
1
(
x
−
μ
)
p(x) = \frac{1}{(2\pi)^{\frac{n}{2}}|\sum|^{\frac{1}{2}}}e^{-\frac{1}{2}(x-\mu)^T\sum^{-1}(x-\mu)}
p(x)=(2π)2n∣∑∣211e−21(x−μ)T∑−1(x−μ)
其中
μ
\mu
μ是均值向量,
∑
\sum
∑是
n
×
n
n\times n
n×n的协方差矩阵,高斯分布完全由均值向量
μ
\mu
μ和协方差矩阵
∑
\sum
∑这俩参数确定,因此我们可将其记为
p
(
x
∣
μ
∑
)
p(x|\mu \sum)
p(x∣μ∑)。
2.高斯混合分布
基于多元高斯分布的概念,我们可定义高斯混合分布:
p
M
(
x
)
=
∑
i
k
α
i
⋅
⋅
p
(
x
∣
μ
i
,
∑
i
)
p_{\mathcal{M}}(x)=\sum_{i}^k \alpha_i··p(x|\mu_i, \sum_i)
pM(x)=i∑kαi⋅⋅p(x∣μi,i∑)
该分布共由
k
k
k个混合分布组成,每个混合成分对应一个高斯分布,而
α
i
>
0
\alpha_i>0
αi>0为相应的混合系数mixture coefficient,且满足
∑
i
=
1
k
α
i
=
1
\sum_{i=1}^{k}\alpha_i = 1
∑i=1kαi=1
3.高斯混合聚类原理
假设样本的生成过程由高斯混合分布给出:首先根据
α
i
\alpha _i
αi定义先验分布选择高斯混合成分,然后根据被选择的混合成份的概率密度函数进行采样,从而生成相应的样本。
给定训练集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\{x_1,x_2,...,x_m\}
D={x1,x2,...,xm}由上述过程生成,令随机变量
z
j
∈
{
1
,
2
,
.
.
.
,
k
}
z_j\in \{1,2,...,k\}
zj∈{1,2,...,k}表示生成样本
x
j
x_j
xj的高斯混合成分,其取值未知。根据贝叶斯定理,可以计算
z
j
z_j
zj的后验分布为:
p
M
(
z
j
=
i
∣
x
j
)
=
P
(
z
j
=
i
)
×
p
(
M
)
(
x
j
∣
z
j
=
i
)
p
M
(
x
j
)
=
α
i
×
p
(
x
j
∣
μ
i
,
∑
i
)
∑
l
=
1
k
α
l
×
p
(
x
j
∣
μ
l
,
∑
l
)
\begin{aligned} p_{\mathcal{M}}(z_j=i|x_j) &= \frac{P(z_j=i)\times p_{\mathcal(M)}(x_j|z_j=i)}{p_{\mathcal{M}}(x_j)} \\ &= \frac{\alpha_i \times p(x_j|\mu_i, \sum_i)}{\sum_{l=1}^{k}\alpha_l\times p(x_j|\mu_l,\sum_l)} \end{aligned}
pM(zj=i∣xj)=pM(xj)P(zj=i)×p(M)(xj∣zj=i)=∑l=1kαl×p(xj∣μl,∑l)αi×p(xj∣μi,∑i)
即
p
M
(
z
j
=
i
∣
x
j
)
p_{\mathcal{M}}(z_j=i|x_j)
pM(zj=i∣xj)给定了样本
x
j
x_j
xj由第
i
i
i个高斯混合成分生成的后验概率,我们将其记为
γ
j
i
\gamma_{ji}
γji,高斯混合聚类将样本集
D
D
D划分为
k
k
k个簇
C
=
{
C
1
,
C
2
,
.
.
.
,
C
k
}
C=\{C_1,C_2,...,C_k\}
C={C1,C2,...,Ck},每个样本
x
j
x_j
xj的簇标记
λ
j
\lambda_j
λj确定如下:
λ
j
=
a
r
g
min
i
∈
{
1
,
2
,
.
.
.
,
k
}
γ
j
i
\lambda_j=arg\min_{i\in\{1,2,...,k\}}\gamma_{ji}
λj=argi∈{1,2,...,k}minγji
4.高斯混合聚类算法
输入:样本集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\{x_1,x_2,...,x_m\}
D={x1,x2,...,xm};高斯混合成分个数
k
k
k
输出:簇划分
C
=
{
C
1
,
C
2
,
.
.
.
,
C
k
}
C=\{C_1,C_2,...,C_k\}
C={C1,C2,...,Ck}
- 初始化高斯混合分布参数 { ( α i , μ i , ∑ i ) ∣ 1 ≤ i ≤ k } \{(\alpha_i,\mu_i,\sum_i)|1\leq i \leq k\} {(αi,μi,∑i)∣1≤i≤k}
- 计算 x j x_j xj由高斯各混合部分生成的后验概率,即 γ j i = p M ( z j = i ∣ x j ) \gamma_{ji}=p_{\mathcal{M}}(z_j=i|x_j) γji=pM(zj=i∣xj)
- 计算新均值向量 μ i ′ = ∑ j = 1 m γ j i x j ∑ j = 1 m γ j i {\mu_i}'=\frac{\sum_{j=1}^{m}\gamma_{ji}x_j}{\sum_{j=1}^{m}\gamma_ji} μi′=∑j=1mγji∑j=1mγjixj,计算新协方差矩阵 ∑ i ′ = ∑ j = 1 m γ j i ( x j − μ i ′ ) ( x j − μ i ′ ) T ∑ j = 1 m γ j i {\sum_i}'=\frac{\sum_{j=1}^{m}\gamma_{ji}(x_j-{\mu_i}')(x_j-{\mu_i}')^T}{\sum_{j=1}^{m}\gamma_{ji}} ∑i′=∑j=1mγji∑j=1mγji(xj−μi′)(xj−μi′)T,计算新混合系数 α i ′ = ∑ j = 1 m γ j i m {\alpha_i}' = \frac{\sum_{j=1}^{m}\gamma_{ji}}{m} αi′=m∑j=1mγji,并更新对应的三个模型参数
- 重复进行2-3步骤直至满足停止条件(EM算法达到最大迭代次数或者似然函数增长很少)
- 根据 λ j = a r g min i ∈ { 1 , 2 , . . . , k } γ j i \lambda_j=arg\min_{i\in\{1,2,...,k\}}\gamma_{ji} λj=argmini∈{1,2,...,k}γji将样本 x j x_j xj划到对应的簇中,即 C λ j = C λ j ∪ { x j } C_{\lambda_j}=C{\lambda_j}\cup\{x_j\} Cλj=Cλj∪{xj}
密度聚类DBSCAN
密度聚类density-based clustering假设聚类结构能通过样本分布的紧密程度确定,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。
1.密度聚类的相关概念
给定数据集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm},有如下概念:
- ϵ \epsilon ϵ邻域: N ϵ = { x i ∈ D ∣ d i s t ( x i , x j ) ≤ ϵ } N_{\epsilon}=\{x_i\in D|dist(x_i,x_j)\leq \epsilon\} Nϵ={xi∈D∣dist(xi,xj)≤ϵ},即样本集中与 x j x_j xj距离不超过 ϵ \epsilon ϵ的样本集合
- 核心对象
core object:若 x j x_j xj的 ϵ \epsilon ϵ邻域内至少包含 M i n P t s MinPts MinPts个样本,则它是一个核心对象 - 密度直达
directly density-reachable:若 x j x_j xj位于 x i x_i xi的 ϵ \epsilon ϵ邻域中,且 x i x_i xi是核心对象,则称 x j x_j xj由 x i x_i xi密度直达 - 密度可达
density-reachable:对 x i x_i xi和 x j x_j xj,若存在样本序列 p 1 , p 2 , . . . , p n p_1,p_2,...,p_n p1,p2,...,pn,其中 p 1 = x i , p n = x j p_1=x_i, p_n=x_j p1=xi,pn=xj且 p i + 1 p_{i+1} pi+1由 p i p_i pi密度直达,则称 x j x_j xj由 x i x_i xi密度可达 - 密度相连
density-connect:对 x i x_i xi与 x j x_j xj,如果存在 x k x_k xk使得 x i x_i xi与 x j x_j xj均由 x k x_k xk密度可达,则称 x i x_i xi和 x j x_j xj密度相连
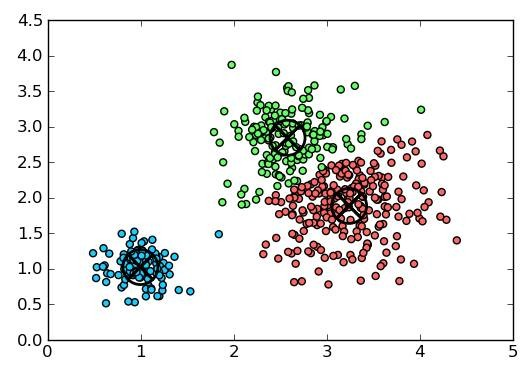
下图给出了密度聚类相关概念的直观展示:
在 M i n P t s = 3 MinPts=3 MinPts=3的情况下,虚线表示 ϵ \epsilon ϵ邻域, x 1 x_1 x1是核心对象, x 2 x_2 x2由 x 1 x_1 x1密度直达, x 3 x_3 x3由 x 1 x_1 x1密度可达, x 3 x_3 x3与 x 4 x_4 x4密度相连。
2.密度聚类原理
基于上述的概念,密度聚类将“簇”定义为:由密度可达关系导出的最大密度相连样本集合。从数学角度上讲,即给定邻域参数 ( ϵ , M i n P t s ) (\epsilon,MinPts) (ϵ,MinPts),簇 C ⊆ D C \subseteq D C⊆D是满足以下性质的非空样本子集:
- 连接性
connectivity: x i ∈ C , x j ∈ C ⇒ x i 和 x j 密度相连 x_i \in C, x_j \in C \Rightarrow x_i\text{和} x_j \text{密度相连} xi∈C,xj∈C⇒xi和xj密度相连 - 最大型
maximality: x i ∈ C , x j 由 x i 密度可达 ⇒ x j ∈ C x_i \in C, x_j\text{由}x_i\text{密度可达} \Rightarrow x_j \in C xi∈C,xj由xi密度可达⇒xj∈C
不难证明,若 x x x为核心对象,则由其密度可达的所有样本组成的集合记为 X = { x ′ ∈ D ∣ x ′ 由 x 密度可达 } X = \{{x}' \in D| {x}'\text{由}x\text{密度可达}\} X={x′∈D∣x′由x密度可达}满足连接性与最大性。
3.密度聚类算法
输入:样本集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\{x_1, x_2,...,x_m\}
D={x1,x2,...,xm};邻域参数
(
ϵ
,
M
i
n
P
t
s
)
(\epsilon, MinPts)
(ϵ,MinPts)
输出:簇划分
C
=
{
C
1
,
C
2
,
.
.
.
,
C
k
}
C=\{C_1,C_2,...,C_k\}
C={C1,C2,...,Ck}
- 遍历所有样本,如果样本 x j x_j xj的 ϵ \epsilon ϵ邻域满足 ∣ N ϵ ( x j ) ∣ ≥ M i n P t s |N_{\epsilon}(x_j)| \geq MinPts ∣Nϵ(xj)∣≥MinPts,那么将其加入核心对象集合 Ω = Ω ∪ { x j } \Omega=\Omega \cup\{x_j\} Ω=Ω∪{xj}
- 随机抽取一个核心对象 o ∈ Ω o\in \Omega o∈Ω,遍历该核心对象 ϵ \epsilon ϵ邻域内的所有样本点 q q q(包括它自身),如果该样本也是核心对象,则 Δ = N ϵ ( q ) ∩ Γ \Delta = N_{\epsilon}(q) \cap \Gamma Δ=Nϵ(q)∩Γ
- 对于2步骤中的核心对象,继续搜寻其 ϵ \epsilon ϵ邻域内的所有样本点,更新 Δ \Delta Δ,生成聚类簇 C 1 = Δ C_1 = \Delta C1=Δ
- 继续随机抽取一个核心对象生成聚类簇,重复2-3步骤,直至所有核心对象均被访问过为止。
直观展示如下:
层次聚类
层次聚类hierarchical clustering试图在不同层次上对数据集进行划分,从而形成树形的聚类结构,数据集的划分既可以采用“自底向上”的聚合策略,也可以采用“自顶向下”的分拆策略。
AGNES是一种自底向上聚合策略的层次聚类算法,它先将数据集中每个样本看成一个初始聚类簇,然后在算法运行的每一步中找到最近的两个聚类簇进行合并,该过程不断重复直至达到预设的聚类簇个数,关键在于如何计算连个聚类簇之间的距离。
1.计算距离的方式
最小距离:
d
m
i
n
(
C
i
,
C
j
)
)
=
min
x
∈
C
i
,
z
∈
C
j
d
i
s
t
(
x
,
z
)
d_{min}(C_i,C_j))= \min_{x\in C_i,z \in C_j}dist(x,z)
dmin(Ci,Cj))=minx∈Ci,z∈Cjdist(x,z)
最大距离:
d
m
a
x
(
C
i
,
C
j
)
)
=
max
x
∈
C
i
,
z
∈
C
j
d
i
s
t
(
x
,
z
)
d_{max}(C_i,C_j))= \max_{x\in C_i,z \in C_j}dist(x,z)
dmax(Ci,Cj))=maxx∈Ci,z∈Cjdist(x,z)
平均距离::
d
a
v
g
(
C
i
,
C
j
)
)
=
1
∣
C
i
∣
∣
C
j
∣
∑
x
∈
C
i
∑
z
∈
C
j
d
i
s
t
(
x
,
z
)
d_{avg}(C_i,C_j))=\frac{1}{|C_i||C_j|}\sum_{x\in C_i}\sum_{z \in C_j}dist(x,z)
davg(Ci,Cj))=∣Ci∣∣Cj∣1∑x∈Ci∑z∈Cjdist(x,z)
当聚类簇距离分别由
d
m
i
n
d_{min}
dmin、
d
m
a
x
d_{max}
dmax或
d
a
v
g
d_{avg}
davg计算时,AGNES算法被相应地成为“单链接”single-linkage、“全链接”complete-linkage或“均链接”average-linkage算法。
2.算法
输入:样本集
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\{x_1, x_2,...,x_m\}
D={x1,x2,...,xm};聚类簇距离度量函数
d
d
d;聚类簇数
k
k
k
输出:簇划分
C
=
{
C
1
,
C
2
,
.
.
.
,
C
k
}
C=\{C_1,C_2,...,C_k\}
C={C1,C2,...,Ck}
- 每个样本最为单独一类, C j = { x j } C_j=\{x_j\} Cj={xj}
- 计算任意两个样本簇间的距离: M ( i , j ) = d ( C i , C j ) M(i, j) = d(C_i,C_j) M(i,j)=d(Ci,Cj)
- 找到距离最近的两个聚类簇 C i ∗ C_{i*} Ci∗和 C j ∗ C_{j*} Cj∗,将其合并 C i ∗ = C i ∗ ∪ C j ∗ C_{i*}=C_{i*}\cup C_{j*} Ci∗=Ci∗∪Cj∗,对于所有下标大于 j j j的簇,将聚类簇 C j C_j Cj重编号为 C j − 1 C_{j-1} Cj−1
- 根据最新的簇更新一下第2步骤计算的簇间距离矩阵
- 重复2-4步骤直至当前聚类簇个数等于预设的聚类簇数 k k k
3.树状图
令AGNES算法执行到所有样本出现在同一个簇中,可得到如下的树状图:
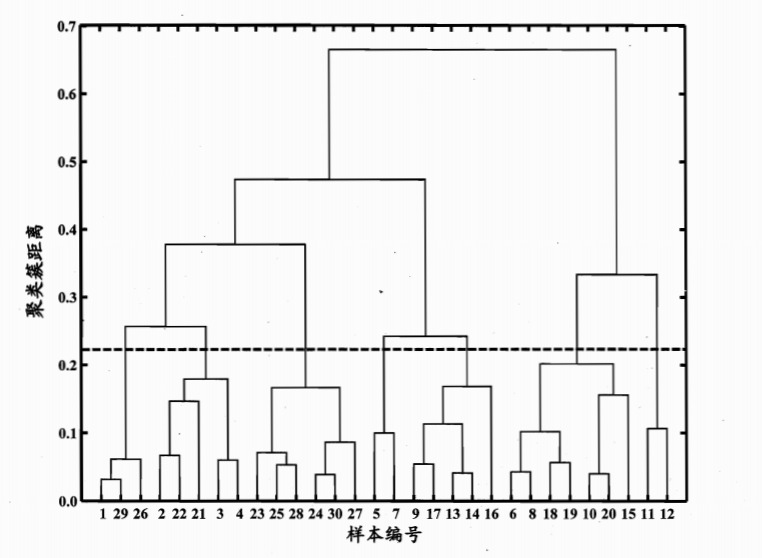
在树状图的特定层次上分割即可得到对应的簇划分结果,上图中虚线划分的位置将样本分为7个簇,理解一下背后的原理。
Reference
[1] 周志华 机器学习


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









